 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeprETA: An ETA Post-processing System at Scale
Jun 05, 2022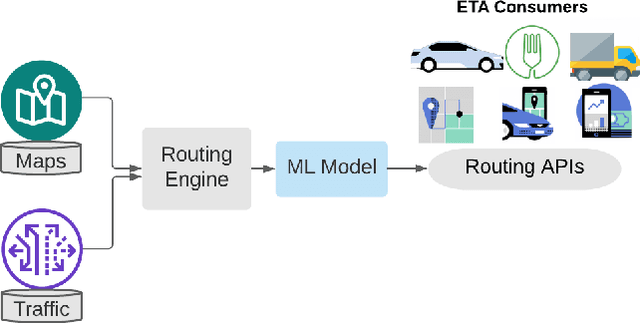
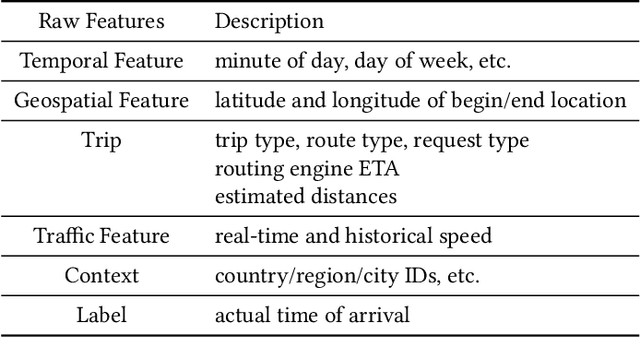
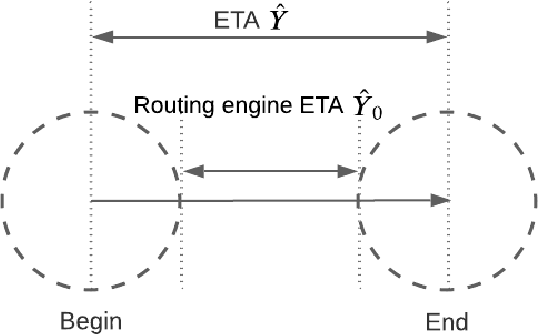
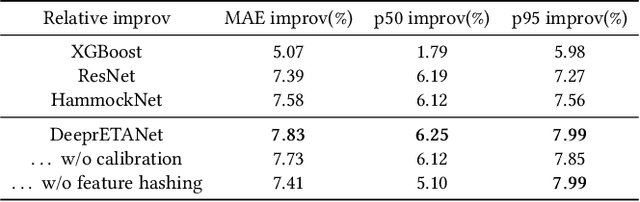
Estimated Time of Arrival (ETA) plays an important role in delivery and ride-hailing platforms. For example, Uber uses ETAs to calculate fares, estimate pickup times, match riders to drivers, plan deliveries, and more. Commonly used route planning algorithms predict an ETA conditioned on the best available route, but such ETA estimates can be unreliable when the actual route taken is not known in advance. In this paper, we describe an ETA post-processing system in which a deep residual ETA network (DeeprETA) refines naive ETAs produced by a route planning algorithm. Offline experiments and online tests demonstrate that post-processing by DeeprETA significantly improves upon the accuracy of naive ETAs as measured by mean and median absolute error. We further show that post-processing by DeeprETA attains lower error than competitive baseline regression models.
Plug and Play Language Models: A Simple Approach to Controlled Text Generation
Jan 08, 2020
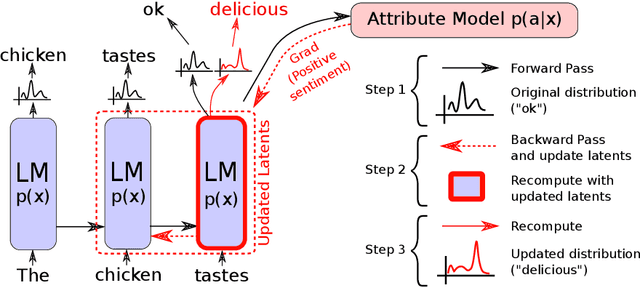
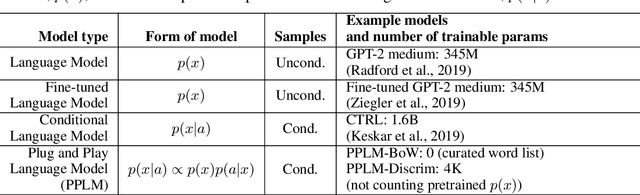
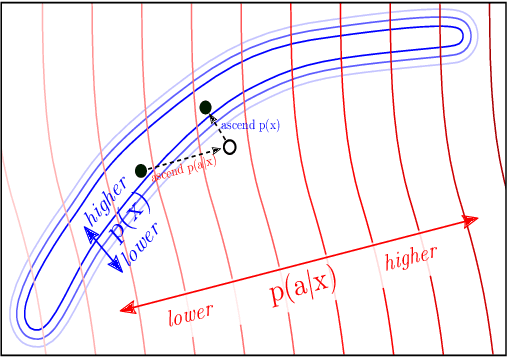
Large transformer-based language models (LMs) trained on huge text corpora have shown unparalleled generation capabilities. However, controlling attributes of the generated language (e.g. switching topic or sentiment) is difficult without modifying the model architecture or fine-tuning on attribute-specific data and entailing the significant cost of retraining. We propose a simple alternative: the Plug and Play Language Model (PPLM) for controllable language generation, which combines a pretrained LM with one or more simple attribute classifiers that guide text generation without any further training of the LM. In the canonical scenario we present, the attribute models are simple classifiers consisting of a user-specified bag of words or a single learned layer with 100,000 times fewer parameters than the LM. Sampling entails a forward and backward pass in which gradients from the attribute model push the LM's hidden activations and thus guide the generation. Model samples demonstrate control over a range of topics and sentiment styles, and extensive automated and human annotated evaluations show attribute alignment and fluency. PPLMs are flexible in that any combination of differentiable attribute models may be used to steer text generation, which will allow for diverse and creative applications beyond the examples given in this paper.
An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution
Jul 09, 2018

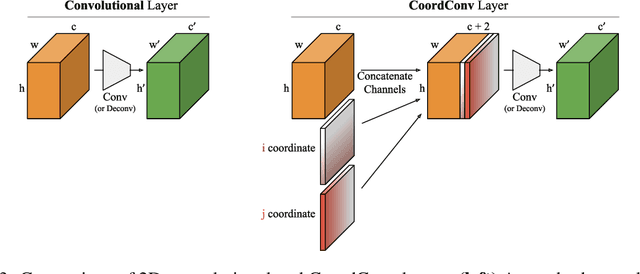
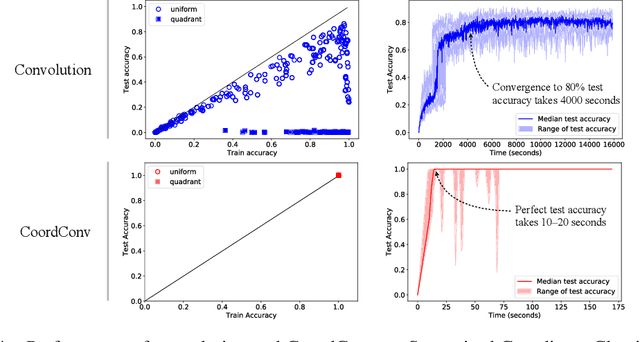
Few ideas have enjoyed as large an impact on deep learning as convolution. For any problem involving pixels or spatial representations, common intuition holds that convolutional neural networks may be appropriate. In this paper we show a striking counterexample to this intuition via the seemingly trivial coordinate transform problem, which simply requires learning a mapping between coordinates in (x,y) Cartesian space and one-hot pixel space. Although convolutional networks would seem appropriate for this task, we show that they fail spectacularly. We demonstrate and carefully analyze the failure first on a toy problem, at which point a simple fix becomes obvious. We call this solution CoordConv, which works by giving convolution access to its own input coordinates through the use of extra coordinate channels. Without sacrificing the computational and parametric efficiency of ordinary convolution, CoordConv allows networks to learn either perfect translation invariance or varying degrees of translation dependence, as required by the task. CoordConv solves the coordinate transform problem with perfect generalization and 150 times faster with 10--100 times fewer parameters than convolution. This stark contrast raises the question: to what extent has this inability of convolution persisted insidiously inside other tasks, subtly hampering performance from within? A complete answer to this question will require further investigation, but we show preliminary evidence that swapping convolution for CoordConv can improve models on a diverse set of tasks. Using CoordConv in a GAN produced less mode collapse as the transform between high-level spatial latents and pixels becomes easier to learn. A Faster R-CNN detection model trained on MNIST detection showed 24% better IOU when using CoordConv, and in the RL domain agents playing Atari games benefit significantly from the use of CoordConv layers.