 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Q(s,s') with Deep Deterministic Dynamics Gradients
Feb 21, 2020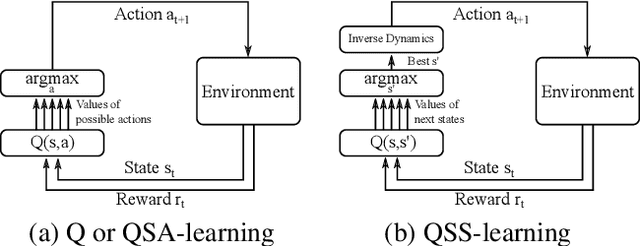
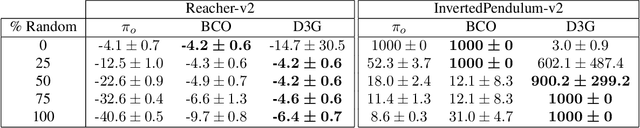
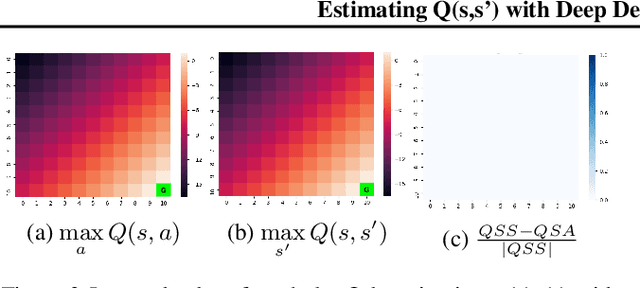
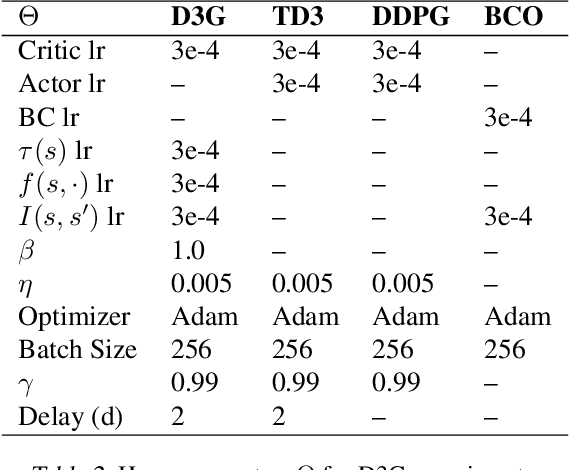
In this paper, we introduce a novel form of value function, $Q(s, s')$, that expresses the utility of transitioning from a state $s$ to a neighboring state $s'$ and then acting optimally thereafter. In order to derive an optimal policy, we develop a forward dynamics model that learns to make next-state predictions that maximize this value. This formulation decouples actions from values while still learning off-policy. We highlight the benefits of this approach in terms of value function transfer, learning within redundant action spaces, and learning off-policy from state observations generated by sub-optimal or completely random policies. Code and videos are available at \url{sites.google.com/view/qss-paper}.
Plug and Play Language Models: A Simple Approach to Controlled Text Generation
Jan 08, 2020
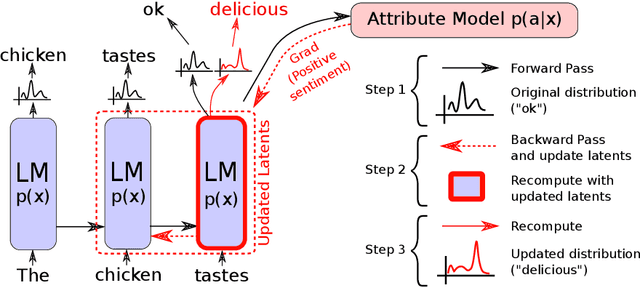
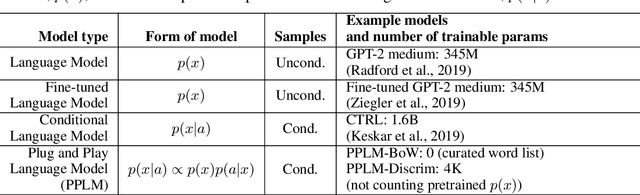
Large transformer-based language models (LMs) trained on huge text corpora have shown unparalleled generation capabilities. However, controlling attributes of the generated language (e.g. switching topic or sentiment) is difficult without modifying the model architecture or fine-tuning on attribute-specific data and entailing the significant cost of retraining. We propose a simple alternative: the Plug and Play Language Model (PPLM) for controllable language generation, which combines a pretrained LM with one or more simple attribute classifiers that guide text generation without any further training of the LM. In the canonical scenario we present, the attribute models are simple classifiers consisting of a user-specified bag of words or a single learned layer with 100,000 times fewer parameters than the LM. Sampling entails a forward and backward pass in which gradients from the attribute model push the LM's hidden activations and thus guide the generation. Model samples demonstrate control over a range of topics and sentiment styles, and extensive automated and human annotated evaluations show attribute alignment and fluency. PPLMs are flexible in that any combination of differentiable attribute models may be used to steer text generation, which will allow for diverse and creative applications beyond the examples given in this paper.
Metropolis-Hastings Generative Adversarial Networks
Nov 28, 2018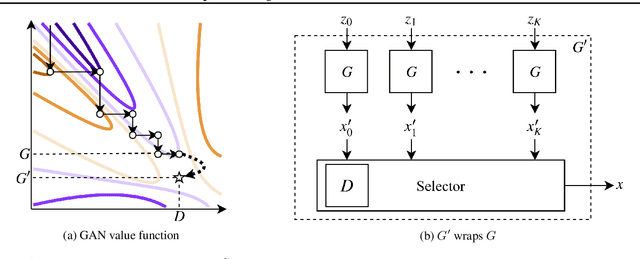
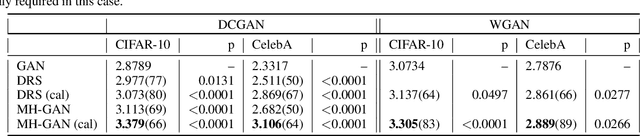
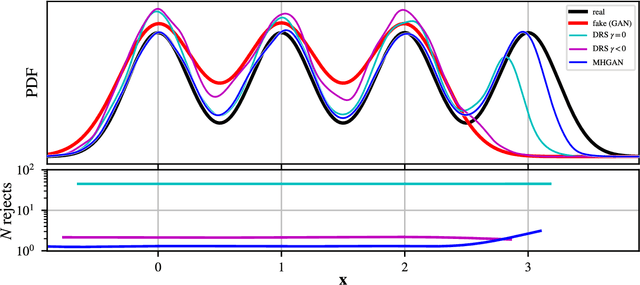

We introduce the Metropolis-Hastings generative adversarial network (MH-GAN), which combines aspects of Markov chain Monte Carlo and GANs. The MH-GAN draws samples from the distribution implicitly defined by a GAN's discriminator-generator pair, as opposed to sampling in a standard GAN which draws samples from the distribution defined by the generator. It uses the discriminator from GAN training to build a wrapper around the generator for improved sampling. With a perfect discriminator, this wrapped generator samples from the true distribution on the data exactly even when the generator is imperfect. We demonstrate the benefits of the improved generator on multiple benchmark datasets, including CIFAR-10 and CelebA, using DCGAN and WGAN.
Applying Faster R-CNN for Object Detection on Malaria Images
Apr 25, 2018
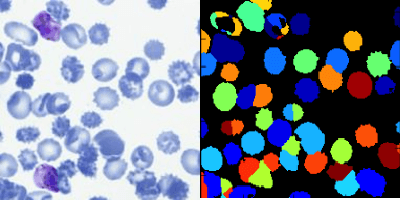
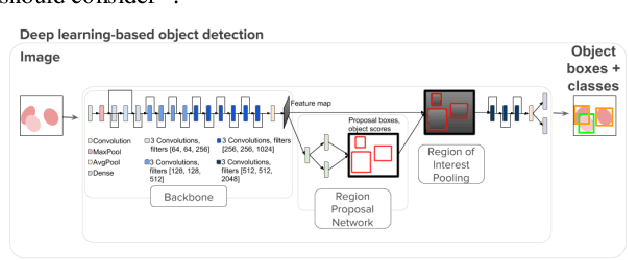

Deep learning based models have had great success in object detection, but the state of the art models have not yet been widely applied to biological image data. We apply for the first time an object detection model previously used on natural images to identify cells and recognize their stages in brightfield microscopy images of malaria-infected blood. Many micro-organisms like malaria parasites are still studied by expert manual inspection and hand counting. This type of object detection task is challenging due to factors like variations in cell shape, density, and color, and uncertainty of some cell classes. In addition, annotated data useful for training is scarce, and the class distribution is inherently highly imbalanced due to the dominance of uninfected red blood cells. We use Faster Region-based Convolutional Neural Network (Faster R-CNN), one of the top performing object detection models in recent years, pre-trained on ImageNet but fine tuned with our data, and compare it to a baseline, which is based on a traditional approach consisting of cell segmentation, extraction of several single-cell features, and classification using random forests. To conduct our initial study, we collect and label a dataset of 1300 fields of view consisting of around 100,000 individual cells. We demonstrate that Faster R-CNN outperforms our baseline and put the results in context of human performance.