 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestioning Representational Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis
May 16, 2025Much of the excitement in modern AI is driven by the observation that scaling up existing systems leads to better performance. But does better performance necessarily imply better internal representations? While the representational optimist assumes it must, this position paper challenges that view. We compare neural networks evolved through an open-ended search process to networks trained via conventional stochastic gradient descent (SGD) on the simple task of generating a single image. This minimal setup offers a unique advantage: each hidden neuron's full functional behavior can be easily visualized as an image, thus revealing how the network's output behavior is internally constructed neuron by neuron. The result is striking: while both networks produce the same output behavior, their internal representations differ dramatically. The SGD-trained networks exhibit a form of disorganization that we term fractured entangled representation (FER). Interestingly, the evolved networks largely lack FER, even approaching a unified factored representation (UFR). In large models, FER may be degrading core model capacities like generalization, creativity, and (continual) learning. Therefore, understanding and mitigating FER could be critical to the future of representation learning.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Simulating Tabular Datasets through LLMs to Rapidly Explore Hypotheses about Real-World Entities
Nov 27, 2024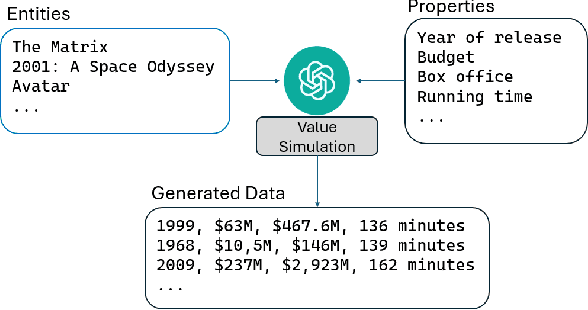
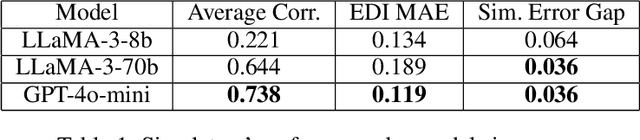


Do horror writers have worse childhoods than other writers? Though biographical details are known about many writers, quantitatively exploring such a qualitative hypothesis requires significant human effort, e.g. to sift through many biographies and interviews of writers and to iteratively search for quantitative features that reflect what is qualitatively of interest. This paper explores the potential to quickly prototype these kinds of hypotheses through (1) applying LLMs to estimate properties of concrete entities like specific people, companies, books, kinds of animals, and countries; (2) performing off-the-shelf analysis methods to reveal possible relationships among such properties (e.g. linear regression); and towards further automation, (3) applying LLMs to suggest the quantitative properties themselves that could help ground a particular qualitative hypothesis (e.g. number of adverse childhood events, in the context of the running example). The hope is to allow sifting through hypotheses more quickly through collaboration between human and machine. Our experiments highlight that indeed, LLMs can serve as useful estimators of tabular data about specific entities across a range of domains, and that such estimations improve with model scale. Further, initial experiments demonstrate the potential of LLMs to map a qualitative hypothesis of interest to relevant concrete variables that the LLM can then estimate. The conclusion is that LLMs offer intriguing potential to help illuminate scientifically interesting patterns latent within the internet-scale data they are trained upon.
Quality-Diversity through AI Feedback
Oct 31, 2023



In many text-generation problems, users may prefer not only a single response, but a diverse range of high-quality outputs from which to choose. Quality-diversity (QD) search algorithms aim at such outcomes, by continually improving and diversifying a population of candidates. However, the applicability of QD to qualitative domains, like creative writing, has been limited by the difficulty of algorithmically specifying measures of quality and diversity. Interestingly, recent developments in language models (LMs) have enabled guiding search through AI feedback, wherein LMs are prompted in natural language to evaluate qualitative aspects of text. Leveraging this development, we introduce Quality-Diversity through AI Feedback (QDAIF), wherein an evolutionary algorithm applies LMs to both generate variation and evaluate the quality and diversity of candidate text. When assessed on creative writing domains, QDAIF covers more of a specified search space with high-quality samples than do non-QD controls. Further, human evaluation of QDAIF-generated creative texts validates reasonable agreement between AI and human evaluation. Our results thus highlight the potential of AI feedback to guide open-ended search for creative and original solutions, providing a recipe that seemingly generalizes to many domains and modalities. In this way, QDAIF is a step towards AI systems that can independently search, diversify, evaluate, and improve, which are among the core skills underlying human society's capacity for innovation.
Quality Diversity through Human Feedback
Oct 18, 2023



Reinforcement learning from human feedback (RLHF) has exhibited the potential to enhance the performance of foundation models for qualitative tasks. Despite its promise, its efficacy is often restricted when conceptualized merely as a mechanism to maximize learned reward models of averaged human preferences, especially in areas such as image generation which demand diverse model responses. Meanwhile, quality diversity (QD) algorithms, dedicated to seeking diverse, high-quality solutions, are often constrained by the dependency on manually defined diversity metrics. Interestingly, such limitations of RLHF and QD can be overcome by blending insights from both. This paper introduces Quality Diversity through Human Feedback (QDHF), which employs human feedback for inferring diversity metrics, expanding the applicability of QD algorithms. Empirical results reveal that QDHF outperforms existing QD methods regarding automatic diversity discovery, and matches the search capabilities of QD with human-constructed metrics. Notably, when deployed for a latent space illumination task, QDHF markedly enhances the diversity of images generated by a Diffusion model. The study concludes with an in-depth analysis of QDHF's sample efficiency and the quality of its derived diversity metrics, emphasizing its promise for enhancing exploration and diversity in optimization for complex, open-ended tasks.
OMNI: Open-endedness via Models of human Notions of Interestingness
Jun 02, 2023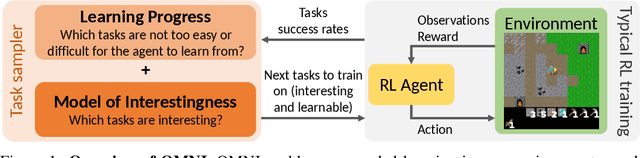

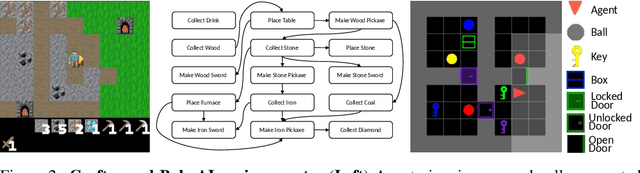
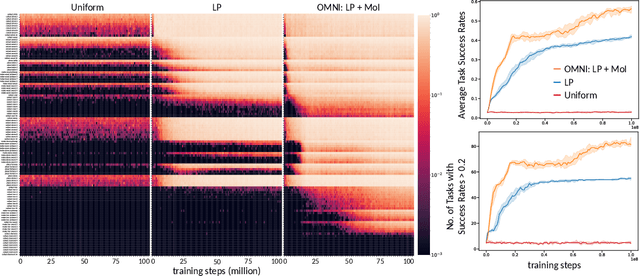
Open-ended algorithms aim to learn new, interesting behaviors forever. That requires a vast environment search space, but there are thus infinitely many possible tasks. Even after filtering for tasks the current agent can learn (i.e., learning progress), countless learnable yet uninteresting tasks remain (e.g., minor variations of previously learned tasks). An Achilles Heel of open-endedness research is the inability to quantify (and thus prioritize) tasks that are not just learnable, but also $\textit{interesting}$ (e.g., worthwhile and novel). We propose solving this problem by $\textit{Open-endedness via Models of human Notions of Interestingness}$ (OMNI). The insight is that we can utilize large (language) models (LMs) as a model of interestingness (MoI), because they $\textit{already}$ internalize human concepts of interestingness from training on vast amounts of human-generated data, where humans naturally write about what they find interesting or boring. We show that LM-based MoIs improve open-ended learning by focusing on tasks that are both learnable $\textit{and interesting}$, outperforming baselines based on uniform task sampling or learning progress alone. This approach has the potential to dramatically advance the ability to intelligently select which tasks to focus on next (i.e., auto-curricula), and could be seen as AI selecting its own next task to learn, facilitating self-improving AI and AI-Generating Algorithms.
Language Model Crossover: Variation through Few-Shot Prompting
Feb 23, 2023This paper pursues the insight that language models naturally enable an intelligent variation operator similar in spirit to evolutionary crossover. In particular, language models of sufficient scale demonstrate in-context learning, i.e. they can learn from associations between a small number of input patterns to generate outputs incorporating such associations (also called few-shot prompting). This ability can be leveraged to form a simple but powerful variation operator, i.e. to prompt a language model with a few text-based genotypes (such as code, plain-text sentences, or equations), and to parse its corresponding output as those genotypes' offspring. The promise of such language model crossover (which is simple to implement and can leverage many different open-source language models) is that it enables a simple mechanism to evolve semantically-rich text representations (with few domain-specific tweaks), and naturally benefits from current progress in language models. Experiments in this paper highlight the versatility of language-model crossover, through evolving binary bit-strings, sentences, equations, text-to-image prompts, and Python code. The conclusion is that language model crossover is a promising method for evolving genomes representable as text.
Machine Love
Feb 22, 2023



While ML generates much economic value, many of us have problematic relationships with social media and other ML-powered applications. One reason is that ML often optimizes for what we want in the moment, which is easy to quantify but at odds with what is known scientifically about human flourishing. Thus, through its impoverished models of us, ML currently falls far short of its exciting potential, which is for it to help us to reach ours. While there is no consensus on defining human flourishing, from diverse perspectives across psychology, philosophy, and spiritual traditions, love is understood to be one of its primary catalysts. Motivated by this view, this paper explores whether there is a useful conception of love fitting for machines to embody, as historically it has been generative to explore whether a nebulous concept, such as life or intelligence, can be thoughtfully abstracted and reimagined, as in the fields of machine intelligence or artificial life. This paper forwards a candidate conception of machine love, inspired in particular by work in positive psychology and psychotherapy: to provide unconditional support enabling humans to autonomously pursue their own growth and development. Through proof of concept experiments, this paper aims to highlight the need for richer models of human flourishing in ML, provide an example framework through which positive psychology can be combined with ML to realize a rough conception of machine love, and demonstrate that current language models begin to enable embodying qualitative humanistic principles. The conclusion is that though at present ML may often serve to addict, distract, or divide us, an alternative path may be opening up: We may align ML to support our growth, through it helping us to align ourselves towards our highest aspirations.
Evolution through Large Models
Jun 17, 2022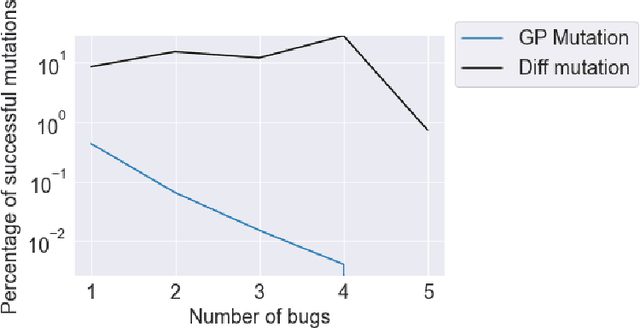
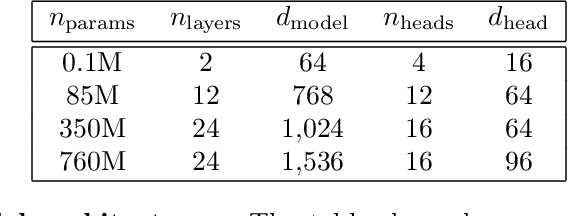
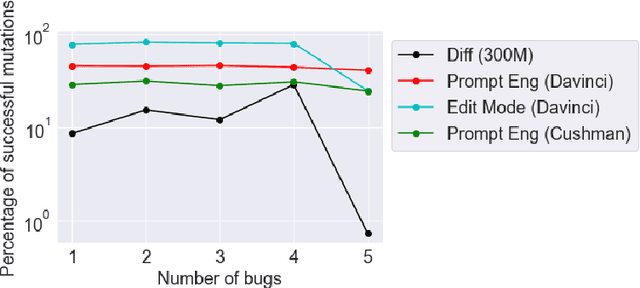
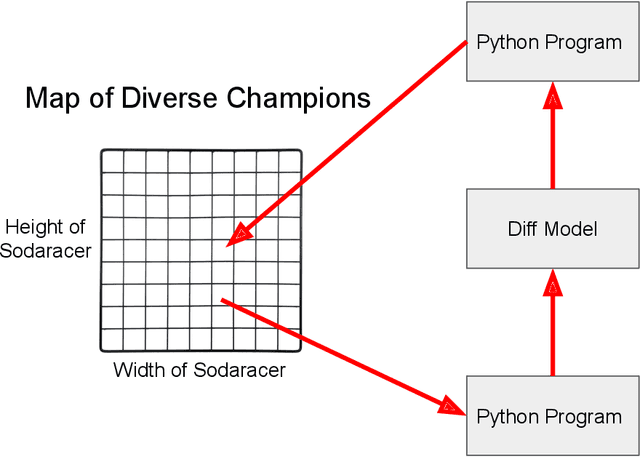
This paper pursues the insight that large language models (LLMs) trained to generate code can vastly improve the effectiveness of mutation operators applied to programs in genetic programming (GP). Because such LLMs benefit from training data that includes sequential changes and modifications, they can approximate likely changes that humans would make. To highlight the breadth of implications of such evolution through large models (ELM), in the main experiment ELM combined with MAP-Elites generates hundreds of thousands of functional examples of Python programs that output working ambulating robots in the Sodarace domain, which the original LLM had never seen in pre-training. These examples then help to bootstrap training a new conditional language model that can output the right walker for a particular terrain. The ability to bootstrap new models that can output appropriate artifacts for a given context in a domain where zero training data was previously available carries implications for open-endedness, deep learning, and reinforcement learning. These implications are explored here in depth in the hope of inspiring new directions of research now opened up by ELM.
Ideas for Improving the Field of Machine Learning: Summarizing Discussion from the NeurIPS 2019 Retrospectives Workshop
Jul 21, 2020This report documents ideas for improving the field of machine learning, which arose from discussions at the ML Retrospectives workshop at NeurIPS 2019. The goal of the report is to disseminate these ideas more broadly, and in turn encourage continuing discussion about how the field could improve along these axes. We focus on topics that were most discussed at the workshop: incentives for encouraging alternate forms of scholarship, re-structuring the review process, participation from academia and industry, and how we might better train computer scientists as scientists. Videos from the workshop can be accessed at https://slideslive.com/neurips/west-114-115-retrospectives-a-venue-for-selfreflection-in-ml-research