 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Recurrent Networks without Recurrence
Jun 04, 2026Training recurrent neural networks (RNNs) requires assigning credit across long sequences of computations. Standard backpropagation through time (BPTT) addresses this problem poorly: it is sequential in time, limiting parallelism, and suffers from vanishing or exploding gradients, making long-range associations difficult to learn. We propose Supervised Memory Training (SMT), a method for training nonlinear RNNs that sidesteps recurrent credit propagation entirely by reducing RNN training to supervised learning on one-step memory transition labels $(m_t, x_{t+1}) \rightarrow m_{t+1}$. SMT acquires these memory labels by training a Transformer-based encoder on a predictive state objective--retaining only information from the past necessary to predict the future. By decoupling what to remember from how to update memory, SMT enables time-parallel RNN training with a stable $O(1)$ length gradient path between any two tokens--without ever unrolling the RNN. We find that SMT outperforms BPTT when pretraining various RNN architectures on tasks like language modeling and pixel sequence modeling. SMT enables nonlinear RNNs to better capture long-range dependencies and train in parallel, potentially unlocking the scaling of models that build temporal abstractions of past experience.
Vector Policy Optimization: Training for Diversity Improves Test-Time Search
May 21, 2026Language models must now generalize out of the box to novel environments and work inside inference-scaling search procedures, such as AlphaEvolve, that select rollouts with a variety of task-specific reward functions. Unfortunately, the standard paradigm of LLM post-training optimizes a pre-specified scalar reward, often leading current LLMs to produce low-entropy response distributions and thus to struggle at displaying the diversity that inference-time search will require. We propose Vector Policy Optimization (VPO), an RL algorithm that explicitly trains policies to anticipate diverse downstream reward functions and to produce diverse solutions. VPO exploits that rewards are often vector-valued in practice, like per-test-case correctness in code generation or, say, multiple different user personas or reward models. VPO is essentially a drop-in replacement for the GRPO advantage estimator, but it trains the LLM to output a set of solutions where individual solutions specialize to different trade-offs in the vector reward space. Across four tasks, VPO matches or beats the strongest scalar RL baselines on test-time search (e.g. pass@k and best@k), with the gap widening as the search budget grows. For evolutionary search, VPO models unlock problems that GRPO models cannot solve at all. As test-time search becomes more standardized, optimizing for diversity may need to become the default post-training objective.
Training Language Models via Neural Cellular Automata
Mar 09, 2026Pre-training is crucial for large language models (LLMs), as it is when most representations and capabilities are acquired. However, natural language pre-training has problems: high-quality text is finite, it contains human biases, and it entangles knowledge with reasoning. This raises a fundamental question: is natural language the only path to intelligence? We propose using neural cellular automata (NCA) to generate synthetic, non-linguistic data for pre-pre-training LLMs--training on synthetic-then-natural language. NCA data exhibits rich spatiotemporal structure and statistics resembling natural language while being controllable and cheap to generate at scale. We find that pre-pre-training on only 164M NCA tokens improves downstream language modeling by up to 6% and accelerates convergence by up to 1.6x. Surprisingly, this even outperforms pre-pre-training on 1.6B tokens of natural language from Common Crawl with more compute. These gains also transfer to reasoning benchmarks, including GSM8K, HumanEval, and BigBench-Lite. Investigating what drives transfer, we find that attention layers are the most transferable, and that optimal NCA complexity varies by domain: code benefits from simpler dynamics, while math and web text favor more complex ones. These results enable systematic tuning of the synthetic distribution to target domains. More broadly, our work opens a path toward more efficient models with fully synthetic pre-training.
Digital Red Queen: Adversarial Program Evolution in Core War with LLMs
Jan 06, 2026Large language models (LLMs) are increasingly being used to evolve solutions to problems in many domains, in a process inspired by biological evolution. However, unlike biological evolution, most LLM-evolution frameworks are formulated as static optimization problems, overlooking the open-ended adversarial dynamics that characterize real-world evolutionary processes. Here, we study Digital Red Queen (DRQ), a simple self-play algorithm that embraces these so-called "Red Queen" dynamics via continual adaptation to a changing objective. DRQ uses an LLM to evolve assembly-like programs, called warriors, which compete against each other for control of a virtual machine in the game of Core War, a Turing-complete environment studied in artificial life and connected to cybersecurity. In each round of DRQ, the model evolves a new warrior to defeat all previous ones, producing a sequence of adapted warriors. Over many rounds, we observe that warriors become increasingly general (relative to a set of held-out human warriors). Interestingly, warriors also become less behaviorally diverse across independent runs, indicating a convergence pressure toward a general-purpose behavioral strategy, much like convergent evolution in nature. This result highlights a potential value of shifting from static objectives to dynamic Red Queen objectives. Our work positions Core War as a rich, controllable sandbox for studying adversarial adaptation in artificial systems and for evaluating LLM-based evolution methods. More broadly, the simplicity and effectiveness of DRQ suggest that similarly minimal self-play approaches could prove useful in other more practical multi-agent adversarial domains, like real-world cybersecurity or combating drug resistance.
Questioning Representational Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis
May 16, 2025Much of the excitement in modern AI is driven by the observation that scaling up existing systems leads to better performance. But does better performance necessarily imply better internal representations? While the representational optimist assumes it must, this position paper challenges that view. We compare neural networks evolved through an open-ended search process to networks trained via conventional stochastic gradient descent (SGD) on the simple task of generating a single image. This minimal setup offers a unique advantage: each hidden neuron's full functional behavior can be easily visualized as an image, thus revealing how the network's output behavior is internally constructed neuron by neuron. The result is striking: while both networks produce the same output behavior, their internal representations differ dramatically. The SGD-trained networks exhibit a form of disorganization that we term fractured entangled representation (FER). Interestingly, the evolved networks largely lack FER, even approaching a unified factored representation (UFR). In large models, FER may be degrading core model capacities like generalization, creativity, and (continual) learning. Therefore, understanding and mitigating FER could be critical to the future of representation learning.
Automating the Search for Artificial Life with Foundation Models
Dec 23, 2024



With the recent Nobel Prize awarded for radical advances in protein discovery, foundation models (FMs) for exploring large combinatorial spaces promise to revolutionize many scientific fields. Artificial Life (ALife) has not yet integrated FMs, thus presenting a major opportunity for the field to alleviate the historical burden of relying chiefly on manual design and trial-and-error to discover the configurations of lifelike simulations. This paper presents, for the first time, a successful realization of this opportunity using vision-language FMs. The proposed approach, called Automated Search for Artificial Life (ASAL), (1) finds simulations that produce target phenomena, (2) discovers simulations that generate temporally open-ended novelty, and (3) illuminates an entire space of interestingly diverse simulations. Because of the generality of FMs, ASAL works effectively across a diverse range of ALife substrates including Boids, Particle Life, Game of Life, Lenia, and Neural Cellular Automata. A major result highlighting the potential of this technique is the discovery of previously unseen Lenia and Boids lifeforms, as well as cellular automata that are open-ended like Conway's Game of Life. Additionally, the use of FMs allows for the quantification of previously qualitative phenomena in a human-aligned way. This new paradigm promises to accelerate ALife research beyond what is possible through human ingenuity alone.
Reward Scale Robustness for Proximal Policy Optimization via DreamerV3 Tricks
Oct 26, 2023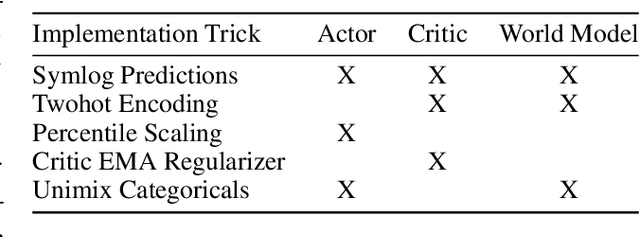
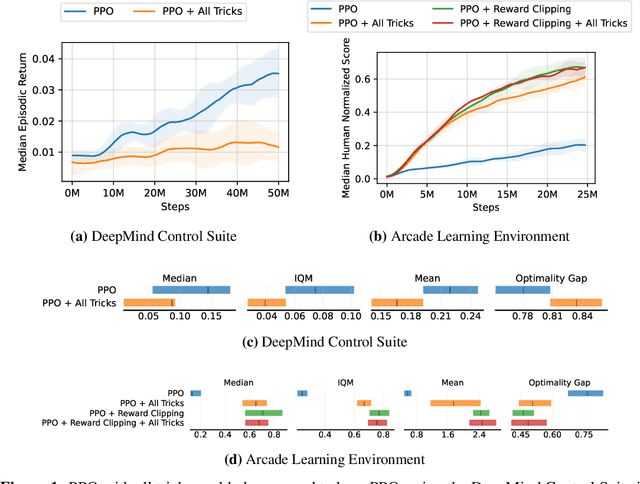
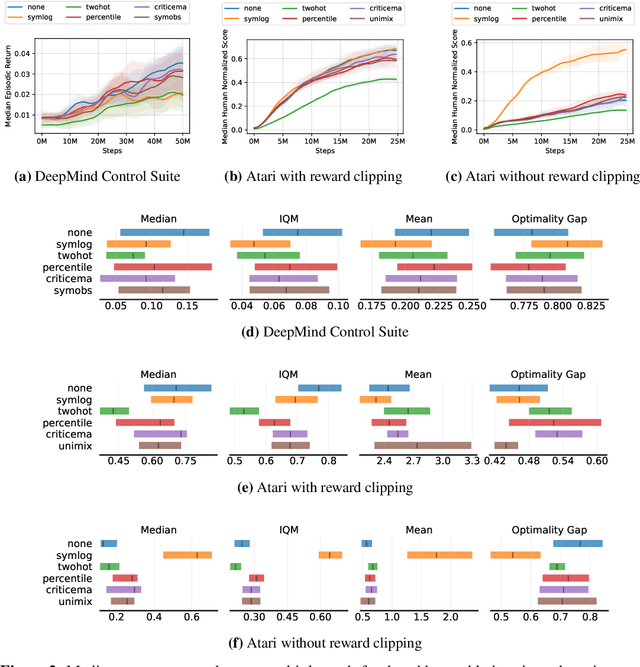
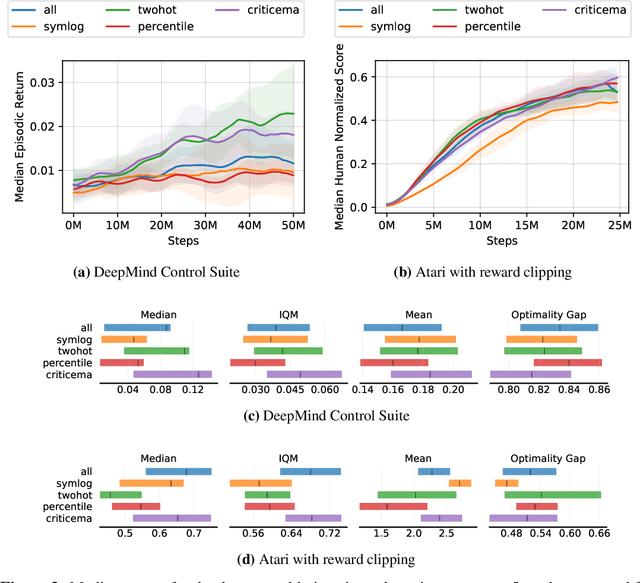
Most reinforcement learning methods rely heavily on dense, well-normalized environment rewards. DreamerV3 recently introduced a model-based method with a number of tricks that mitigate these limitations, achieving state-of-the-art on a wide range of benchmarks with a single set of hyperparameters. This result sparked discussion about the generality of the tricks, since they appear to be applicable to other reinforcement learning algorithms. Our work applies DreamerV3's tricks to PPO and is the first such empirical study outside of the original work. Surprisingly, we find that the tricks presented do not transfer as general improvements to PPO. We use a high quality PPO reference implementation and present extensive ablation studies totaling over 10,000 A100 hours on the Arcade Learning Environment and the DeepMind Control Suite. Though our experiments demonstrate that these tricks do not generally outperform PPO, we identify cases where they succeed and offer insight into the relationship between the implementation tricks. In particular, PPO with these tricks performs comparably to PPO on Atari games with reward clipping and significantly outperforms PPO without reward clipping.
Effective Mutation Rate Adaptation through Group Elite Selection
Apr 11, 2022
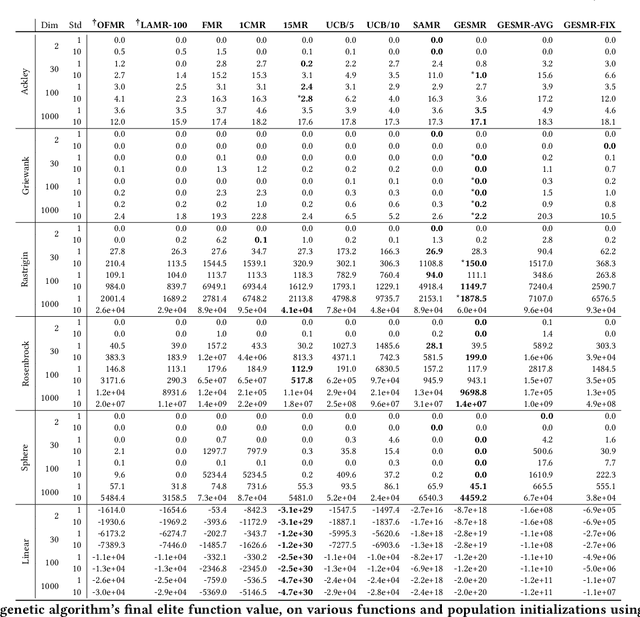
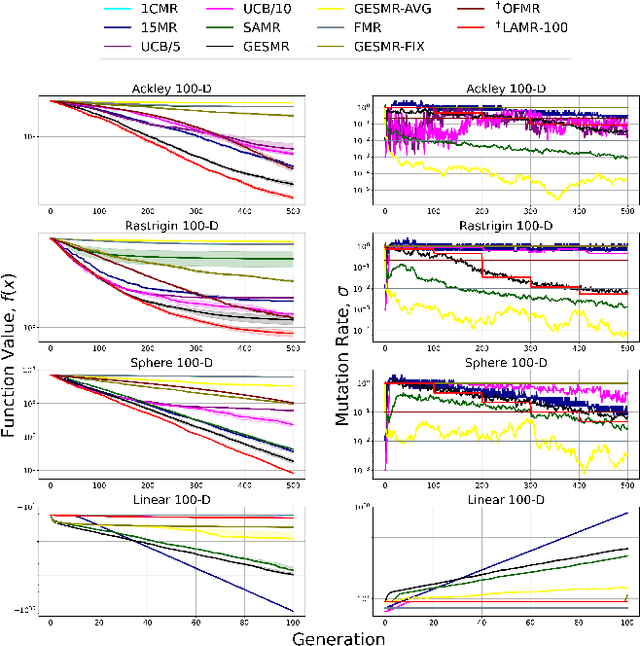
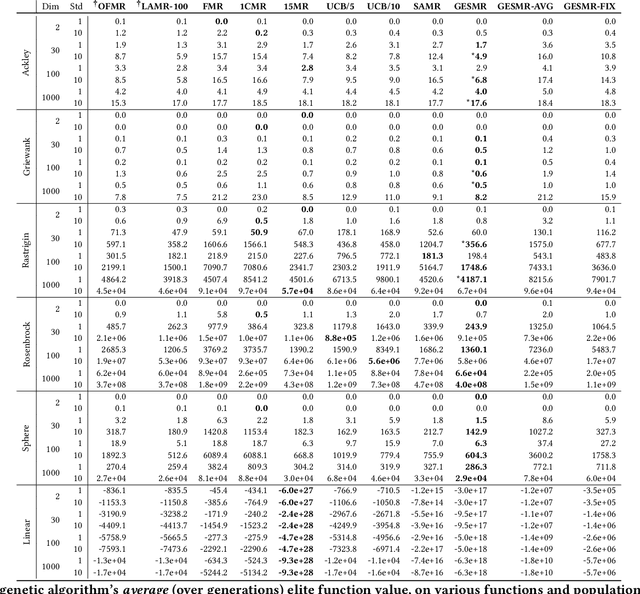
Evolutionary algorithms are sensitive to the mutation rate (MR); no single value of this parameter works well across domains. Self-adaptive MR approaches have been proposed but they tend to be brittle: Sometimes they decay the MR to zero, thus halting evolution. To make self-adaptive MR robust, this paper introduces the Group Elite Selection of Mutation Rates (GESMR) algorithm. GESMR co-evolves a population of solutions and a population of MRs, such that each MR is assigned to a group of solutions. The resulting best mutational change in the group, instead of average mutational change, is used for MR selection during evolution, thus avoiding the vanishing MR problem. With the same number of function evaluations and with almost no overhead, GESMR converges faster and to better solutions than previous approaches on a wide range of continuous test optimization problems. GESMR also scales well to high-dimensional neuroevolution for supervised image-classification tasks and for reinforcement learning control tasks. Remarkably, GESMR produces MRs that are optimal in the long-term, as demonstrated through a comprehensive look-ahead grid search. Thus, GESMR and its theoretical and empirical analysis demonstrate how self-adaptation can be harnessed to improve performance in several applications of evolutionary computation.
Physically Plausible Pose Refinement using Fully Differentiable Forces
May 17, 2021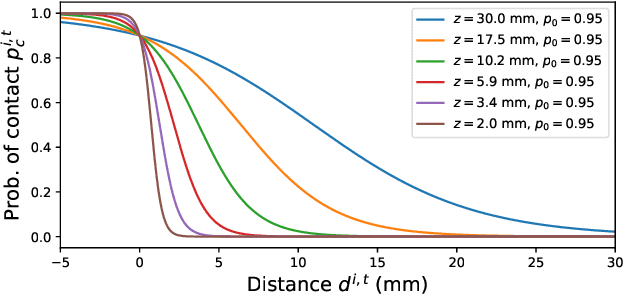
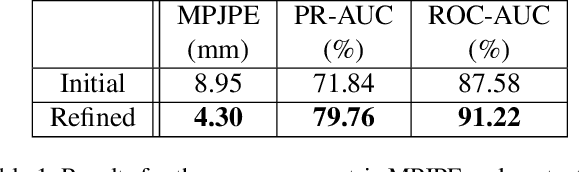
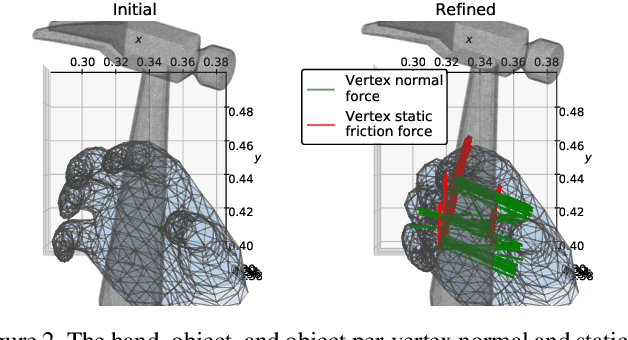
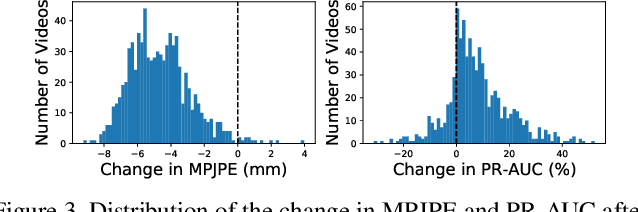
All hand-object interaction is controlled by forces that the two bodies exert on each other, but little work has been done in modeling these underlying forces when doing pose and contact estimation from RGB/RGB-D data. Given the pose of the hand and object from any pose estimation system, we propose an end-to-end differentiable model that refines pose estimates by learning the forces experienced by the object at each vertex in its mesh. By matching the learned net force to an estimate of net force based on finite differences of position, this model is able to find forces that accurately describe the movement of the object, while resolving issues like mesh interpenetration and lack of contact. Evaluating on the ContactPose dataset, we show this model successfully corrects poses and finds contact maps that better match the ground truth, despite not using any RGB or depth image data.