 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusing Blame: Task-Dependent Credit Assignment in Biologically Plausible Dual-Stream Networks
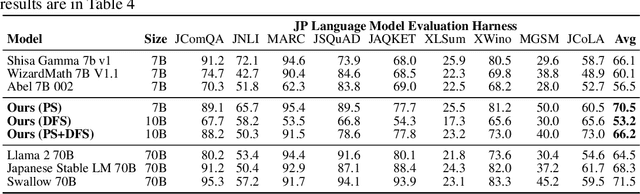
Jun 30, 2026Biological neural circuits obey Dale's principle: each neuron's synapses are uniformly excitatory or inhibitory. Artificial networks that respect this constraint must coordinate separate excitatory and inhibitory populations, fundamentally changing how credit is assigned during learning. Several biologically plausible learning rules avoid backpropagation's weight transport requirement, but it has been difficult to achieve strong performance under Dale's principle beyond MNIST. Error Diffusion (ED) was originally proposed in a dual-stream excitatory/inhibitory architecture, where learning is driven by routing global error signals to all layers without transporting transposed forward weights or relying on random feedback matrices. Whether such a rule can scale under Dale's principle across both supervised classification and reinforcement learning remains unknown. Here, we introduce modulo error routing to extend Error Diffusion beyond binary classification, and show that a dual-stream excitatory/inhibitory architecture trained with this method achieves 96.7% on MNIST and establishes a 61.7% baseline on CIFAR-10, demonstrating that representation learning is possible even when strictly enforcing Dale's principle. For the classification setting, we introduce three domain-specific innovations: layer-specific sigmoid widths, batch-centered class error signals, and asymmetric initialization, and ablation analysis reveals that their relative importance reverses between MNIST and CIFAR-10, exposing task-dependent credit-assignment bottlenecks invisible to single-benchmark evaluation. In reinforcement learning, we integrate ED with Proximal Policy Optimization (PPO) and evaluate it on continuous-control tasks in Google Brax and on Craftax, an open-ended exploration task. We show that ED-PPO achieves competitive performance relative to Direct Feedback Alignment, a backpropagation-free baseline.
Digital Red Queen: Adversarial Program Evolution in Core War with LLMs
Jan 06, 2026Large language models (LLMs) are increasingly being used to evolve solutions to problems in many domains, in a process inspired by biological evolution. However, unlike biological evolution, most LLM-evolution frameworks are formulated as static optimization problems, overlooking the open-ended adversarial dynamics that characterize real-world evolutionary processes. Here, we study Digital Red Queen (DRQ), a simple self-play algorithm that embraces these so-called "Red Queen" dynamics via continual adaptation to a changing objective. DRQ uses an LLM to evolve assembly-like programs, called warriors, which compete against each other for control of a virtual machine in the game of Core War, a Turing-complete environment studied in artificial life and connected to cybersecurity. In each round of DRQ, the model evolves a new warrior to defeat all previous ones, producing a sequence of adapted warriors. Over many rounds, we observe that warriors become increasingly general (relative to a set of held-out human warriors). Interestingly, warriors also become less behaviorally diverse across independent runs, indicating a convergence pressure toward a general-purpose behavioral strategy, much like convergent evolution in nature. This result highlights a potential value of shifting from static objectives to dynamic Red Queen objectives. Our work positions Core War as a rich, controllable sandbox for studying adversarial adaptation in artificial systems and for evaluating LLM-based evolution methods. More broadly, the simplicity and effectiveness of DRQ suggest that similarly minimal self-play approaches could prove useful in other more practical multi-agent adversarial domains, like real-world cybersecurity or combating drug resistance.
EDINET-Bench: Evaluating LLMs on Complex Financial Tasks using Japanese Financial Statements
Jun 10, 2025



Financial analysis presents complex challenges that could leverage large language model (LLM) capabilities. However, the scarcity of challenging financial datasets, particularly for Japanese financial data, impedes academic innovation in financial analytics. As LLMs advance, this lack of accessible research resources increasingly hinders their development and evaluation in this specialized domain. To address this gap, we introduce EDINET-Bench, an open-source Japanese financial benchmark designed to evaluate the performance of LLMs on challenging financial tasks including accounting fraud detection, earnings forecasting, and industry prediction. EDINET-Bench is constructed by downloading annual reports from the past 10 years from Japan's Electronic Disclosure for Investors' NETwork (EDINET) and automatically assigning labels corresponding to each evaluation task. Our experiments reveal that even state-of-the-art LLMs struggle, performing only slightly better than logistic regression in binary classification for fraud detection and earnings forecasting. These results highlight significant challenges in applying LLMs to real-world financial applications and underscore the need for domain-specific adaptation. Our dataset, benchmark construction code, and evaluation code is publicly available to facilitate future research in finance with LLMs.
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Apr 10, 2025


AI is increasingly playing a pivotal role in transforming how scientific discoveries are made. We introduce The AI Scientist-v2, an end-to-end agentic system capable of producing the first entirely AI generated peer-review-accepted workshop paper. This system iteratively formulates scientific hypotheses, designs and executes experiments, analyzes and visualizes data, and autonomously authors scientific manuscripts. Compared to its predecessor (v1, Lu et al., 2024 arXiv:2408.06292), The AI Scientist-v2 eliminates the reliance on human-authored code templates, generalizes effectively across diverse machine learning domains, and leverages a novel progressive agentic tree-search methodology managed by a dedicated experiment manager agent. Additionally, we enhance the AI reviewer component by integrating a Vision-Language Model (VLM) feedback loop for iterative refinement of content and aesthetics of the figures. We evaluated The AI Scientist-v2 by submitting three fully autonomous manuscripts to a peer-reviewed ICLR workshop. Notably, one manuscript achieved high enough scores to exceed the average human acceptance threshold, marking the first instance of a fully AI-generated paper successfully navigating a peer review. This accomplishment highlights the growing capability of AI in conducting all aspects of scientific research. We anticipate that further advancements in autonomous scientific discovery technologies will profoundly impact human knowledge generation, enabling unprecedented scalability in research productivity and significantly accelerating scientific breakthroughs, greatly benefiting society at large. We have open-sourced the code at https://github.com/SakanaAI/AI-Scientist-v2 to foster the future development of this transformative technology. We also discuss the role of AI in science, including AI safety.
Automating the Search for Artificial Life with Foundation Models
Dec 23, 2024



With the recent Nobel Prize awarded for radical advances in protein discovery, foundation models (FMs) for exploring large combinatorial spaces promise to revolutionize many scientific fields. Artificial Life (ALife) has not yet integrated FMs, thus presenting a major opportunity for the field to alleviate the historical burden of relying chiefly on manual design and trial-and-error to discover the configurations of lifelike simulations. This paper presents, for the first time, a successful realization of this opportunity using vision-language FMs. The proposed approach, called Automated Search for Artificial Life (ASAL), (1) finds simulations that produce target phenomena, (2) discovers simulations that generate temporally open-ended novelty, and (3) illuminates an entire space of interestingly diverse simulations. Because of the generality of FMs, ASAL works effectively across a diverse range of ALife substrates including Boids, Particle Life, Game of Life, Lenia, and Neural Cellular Automata. A major result highlighting the potential of this technique is the discovery of previously unseen Lenia and Boids lifeforms, as well as cellular automata that are open-ended like Conway's Game of Life. Additionally, the use of FMs allows for the quantification of previously qualitative phenomena in a human-aligned way. This new paradigm promises to accelerate ALife research beyond what is possible through human ingenuity alone.
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Aug 15, 2024


One of the grand challenges of artificial general intelligence is developing agents capable of conducting scientific research and discovering new knowledge. While frontier models have already been used as aides to human scientists, e.g. for brainstorming ideas, writing code, or prediction tasks, they still conduct only a small part of the scientific process. This paper presents the first comprehensive framework for fully automatic scientific discovery, enabling frontier large language models to perform research independently and communicate their findings. We introduce The AI Scientist, which generates novel research ideas, writes code, executes experiments, visualizes results, describes its findings by writing a full scientific paper, and then runs a simulated review process for evaluation. In principle, this process can be repeated to iteratively develop ideas in an open-ended fashion, acting like the human scientific community. We demonstrate its versatility by applying it to three distinct subfields of machine learning: diffusion modeling, transformer-based language modeling, and learning dynamics. Each idea is implemented and developed into a full paper at a cost of less than $15 per paper. To evaluate the generated papers, we design and validate an automated reviewer, which we show achieves near-human performance in evaluating paper scores. The AI Scientist can produce papers that exceed the acceptance threshold at a top machine learning conference as judged by our automated reviewer. This approach signifies the beginning of a new era in scientific discovery in machine learning: bringing the transformative benefits of AI agents to the entire research process of AI itself, and taking us closer to a world where endless affordable creativity and innovation can be unleashed on the world's most challenging problems. Our code is open-sourced at https://github.com/SakanaAI/AI-Scientist
Evolutionary Optimization of Model Merging Recipes
Mar 19, 2024

We present a novel application of evolutionary algorithms to automate the creation of powerful foundation models. While model merging has emerged as a promising approach for LLM development due to its cost-effectiveness, it currently relies on human intuition and domain knowledge, limiting its potential. Here, we propose an evolutionary approach that overcomes this limitation by automatically discovering effective combinations of diverse open-source models, harnessing their collective intelligence without requiring extensive additional training data or compute. Our approach operates in both parameter space and data flow space, allowing for optimization beyond just the weights of the individual models. This approach even facilitates cross-domain merging, generating models like a Japanese LLM with Math reasoning capabilities. Surprisingly, our Japanese Math LLM achieved state-of-the-art performance on a variety of established Japanese LLM benchmarks, even surpassing models with significantly more parameters, despite not being explicitly trained for such tasks. Furthermore, a culturally-aware Japanese VLM generated through our approach demonstrates its effectiveness in describing Japanese culture-specific content, outperforming previous Japanese VLMs. This work not only contributes new state-of-the-art models back to the open-source community, but also introduces a new paradigm for automated model composition, paving the way for exploring alternative, efficient approaches to foundation model development.
Learning to Generalize with Object-centric Agents in the Open World Survival Game Crafter
Aug 05, 2022
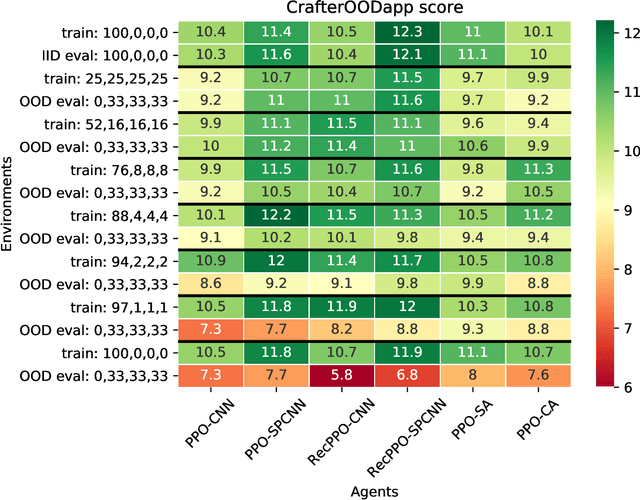
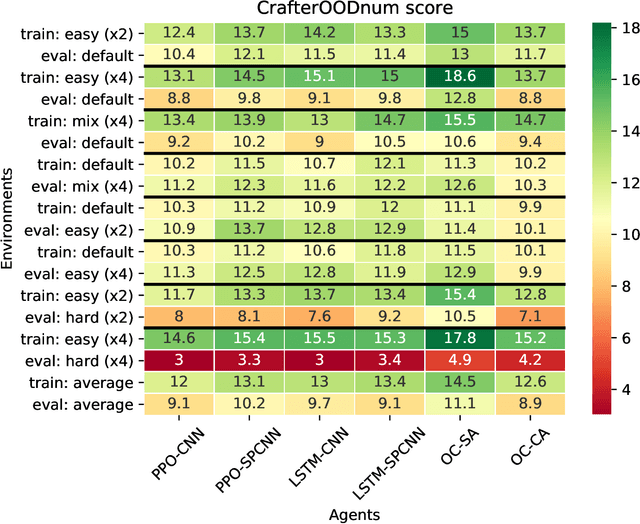
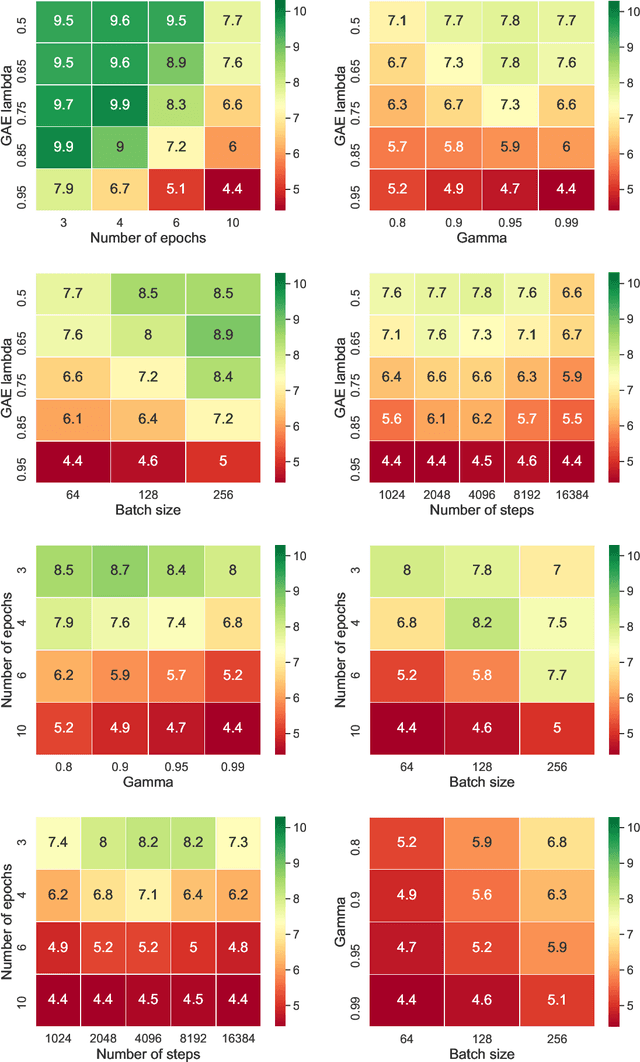
Reinforcement learning agents must generalize beyond their training experience. Prior work has focused mostly on identical training and evaluation environments. Starting from the recently introduced Crafter benchmark, a 2D open world survival game, we introduce a new set of environments suitable for evaluating some agent's ability to generalize on previously unseen (numbers of) objects and to adapt quickly (meta-learning). In Crafter, the agents are evaluated by the number of unlocked achievements (such as collecting resources) when trained for 1M steps. We show that current agents struggle to generalize, and introduce novel object-centric agents that improve over strong baselines. We also provide critical insights of general interest for future work on Crafter through several experiments. We show that careful hyper-parameter tuning improves the PPO baseline agent by a large margin and that even feedforward agents can unlock almost all achievements by relying on the inventory display. We achieve new state-of-the-art performance on the original Crafter environment. Additionally, when trained beyond 1M steps, our tuned agents can unlock almost all achievements. We show that the recurrent PPO agents improve over feedforward ones, even with the inventory information removed. We introduce CrafterOOD, a set of 15 new environments that evaluate OOD generalization. On CrafterOOD, we show that the current agents fail to generalize, whereas our novel object-centric agents achieve state-of-the-art OOD generalization while also being interpretable. Our code is public.
Simultaneous Multiple-Prompt Guided Generation Using Differentiable Optimal Transport
Apr 18, 2022


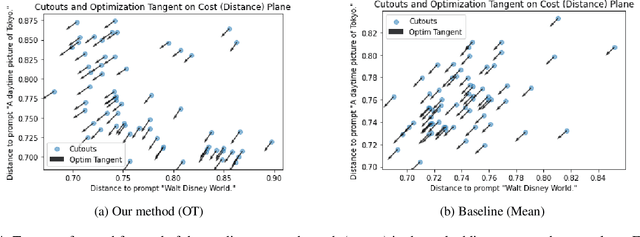
Recent advances in deep learning, such as powerful generative models and joint text-image embeddings, have provided the computational creativity community with new tools, opening new perspectives for artistic pursuits. Text-to-image synthesis approaches that operate by generating images from text cues provide a case in point. These images are generated with a latent vector that is progressively refined to agree with text cues. To do so, patches are sampled within the generated image, and compared with the text prompts in the common text-image embedding space; The latent vector is then updated, using gradient descent, to reduce the mean (average) distance between these patches and text cues. While this approach provides artists with ample freedom to customize the overall appearance of images, through their choice in generative models, the reliance on a simple criterion (mean of distances) often causes mode collapse: The entire image is drawn to the average of all text cues, thereby losing their diversity. To address this issue, we propose using matching techniques found in the optimal transport (OT) literature, resulting in images that are able to reflect faithfully a wide diversity of prompts. We provide numerous illustrations showing that OT avoids some of the pitfalls arising from estimating vectors with mean distances, and demonstrate the capacity of our proposed method to perform better in experiments, qualitatively and quantitatively.
Evolving Modular Soft Robots without Explicit Inter-Module Communication using Local Self-Attention
Apr 13, 2022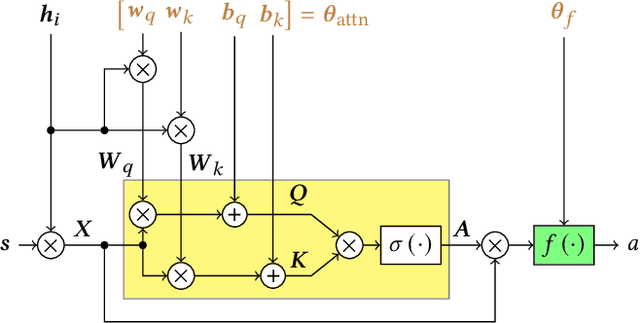
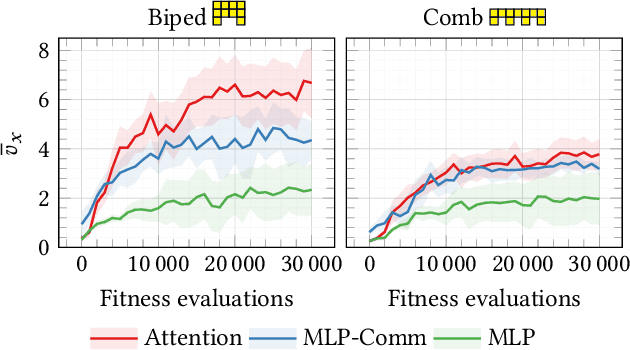
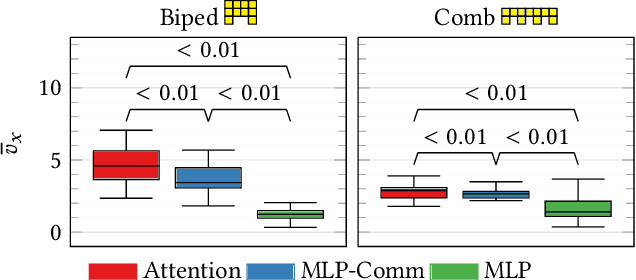
Modularity in robotics holds great potential. In principle, modular robots can be disassembled and reassembled in different robots, and possibly perform new tasks. Nevertheless, actually exploiting modularity is yet an unsolved problem: controllers usually rely on inter-module communication, a practical requirement that makes modules not perfectly interchangeable and thus limits their flexibility. Here, we focus on Voxel-based Soft Robots (VSRs), aggregations of mechanically identical elastic blocks. We use the same neural controller inside each voxel, but without any inter-voxel communication, hence enabling ideal conditions for modularity: modules are all equal and interchangeable. We optimize the parameters of the neural controller-shared among the voxels-by evolutionary computation. Crucially, we use a local self-attention mechanism inside the controller to overcome the absence of inter-module communication channels, thus enabling our robots to truly be driven by the collective intelligence of their modules. We show experimentally that the evolved robots are effective in the task of locomotion: thanks to self-attention, instances of the same controller embodied in the same robot can focus on different inputs. We also find that the evolved controllers generalize to unseen morphologies, after a short fine-tuning, suggesting that an inductive bias related to the task arises from true modularity.