 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Learning Strategies for Evolved Virtual Soft Robots
Apr 14, 2026Optimizing the body and brain of a robot is a coupled challenge: the morphology determines what control strategies are effective, while the control parameters influence how well the morphology performs. This joint optimization can be done through nested loops of evolutionary and learning processes, where the control parameters of each robot are learned independently. However, the control parameters learned by one robot may contain valuable information for others. Thus, we introduce a social learning approach in which robots can exploit optimized parameters from their peers to accelerate their own brain optimization. Within this framework, we systematically investigate how the selection of teachers, deciding which and how many robots to learn from, affects performance, experimenting with virtual soft robots in four tasks and environments. In particular, we study the effect of inheriting experience from morphologically similar robots due to the tightly coupled body and brain in robot optimization. Our results confirm the effectiveness of building on others' experience, as social learning clearly outperforms learning from scratch under equivalent computational budgets. In addition, while the optimal teacher selection strategy remains open, our findings suggest that incorporating knowledge from multiple teachers can yield more consistent and robust improvements.
Interactive LLM-assisted Curriculum Learning for Multi-Task Evolutionary Policy Search
Feb 11, 2026Multi-task policy search is a challenging problem because policies are required to generalize beyond training cases. Curriculum learning has proven to be effective in this setting, as it introduces complexity progressively. However, designing effective curricula is labor-intensive and requires extensive domain expertise. LLM-based curriculum generation has only recently emerged as a potential solution, but was limited to operate in static, offline modes without leveraging real-time feedback from the optimizer. Here we propose an interactive LLM-assisted framework for online curriculum generation, where the LLM adaptively designs training cases based on real-time feedback from the evolutionary optimization process. We investigate how different feedback modalities, ranging from numeric metrics alone to combinations with plots and behavior visualizations, influence the LLM ability to generate meaningful curricula. Through a 2D robot navigation case study, tackled with genetic programming as optimizer, we evaluate our approach against static LLM-generated curricula and expert-designed baselines. We show that interactive curriculum generation outperforms static approaches, with multimodal feedback incorporating both progression plots and behavior visualizations yielding performance competitive with expert-designed curricula. This work contributes to understanding how LLMs can serve as interactive curriculum designers for embodied AI systems, with potential extensions to broader evolutionary robotics applications.
Problem-oriented AutoML in Clustering
Sep 24, 2024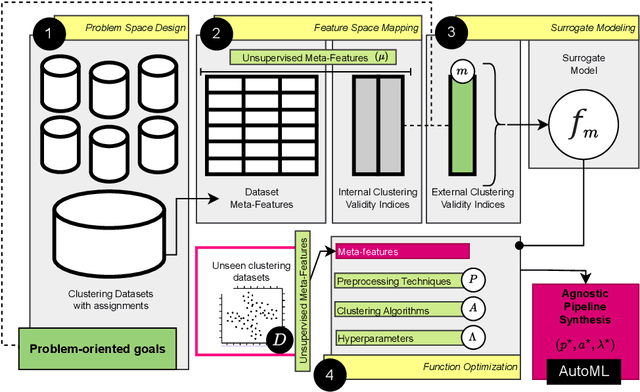

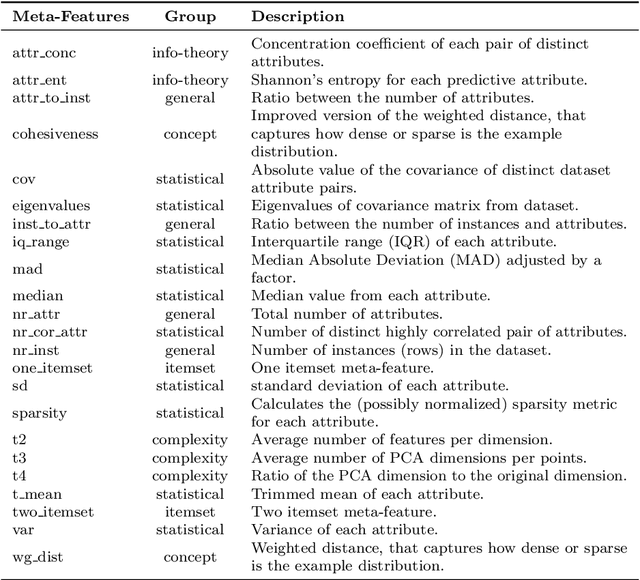
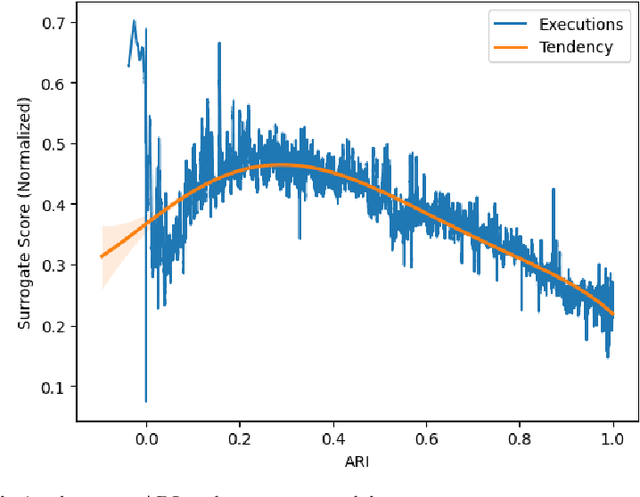
The Problem-oriented AutoML in Clustering (PoAC) framework introduces a novel, flexible approach to automating clustering tasks by addressing the shortcomings of traditional AutoML solutions. Conventional methods often rely on predefined internal Clustering Validity Indexes (CVIs) and static meta-features, limiting their adaptability and effectiveness across diverse clustering tasks. In contrast, PoAC establishes a dynamic connection between the clustering problem, CVIs, and meta-features, allowing users to customize these components based on the specific context and goals of their task. At its core, PoAC employs a surrogate model trained on a large meta-knowledge base of previous clustering datasets and solutions, enabling it to infer the quality of new clustering pipelines and synthesize optimal solutions for unseen datasets. Unlike many AutoML frameworks that are constrained by fixed evaluation metrics and algorithm sets, PoAC is algorithm-agnostic, adapting seamlessly to different clustering problems without requiring additional data or retraining. Experimental results demonstrate that PoAC not only outperforms state-of-the-art frameworks on a variety of datasets but also excels in specific tasks such as data visualization, and highlight its ability to dynamically adjust pipeline configurations based on dataset complexity.
Generating Realistic Synthetic Relational Data through Graph Variational Autoencoders
Nov 30, 2022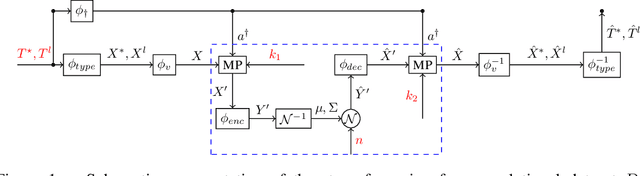
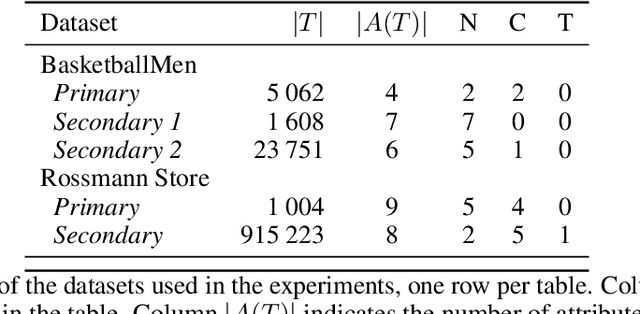

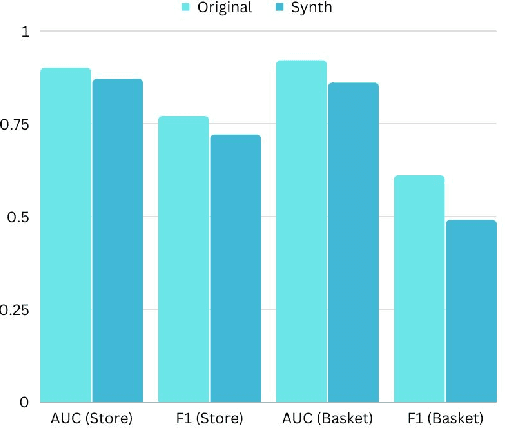
Synthetic data generation has recently gained widespread attention as a more reliable alternative to traditional data anonymization. The involved methods are originally developed for image synthesis. Hence, their application to the typically tabular and relational datasets from healthcare, finance and other industries is non-trivial. While substantial research has been devoted to the generation of realistic tabular datasets, the study of synthetic relational databases is still in its infancy. In this paper, we combine the variational autoencoder framework with graph neural networks to generate realistic synthetic relational databases. We then apply the obtained method to two publicly available databases in computational experiments. The results indicate that real databases' structures are accurately preserved in the resulting synthetic datasets, even for large datasets with advanced data types.
Evolving Modular Soft Robots without Explicit Inter-Module Communication using Local Self-Attention
Apr 13, 2022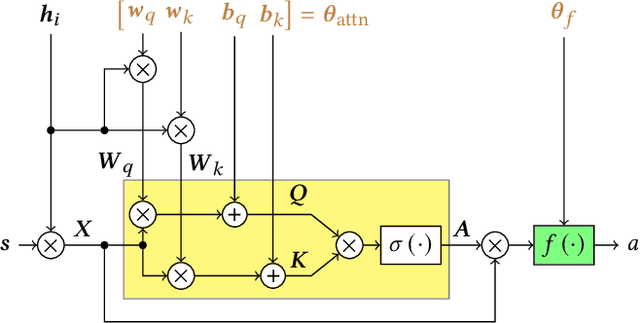
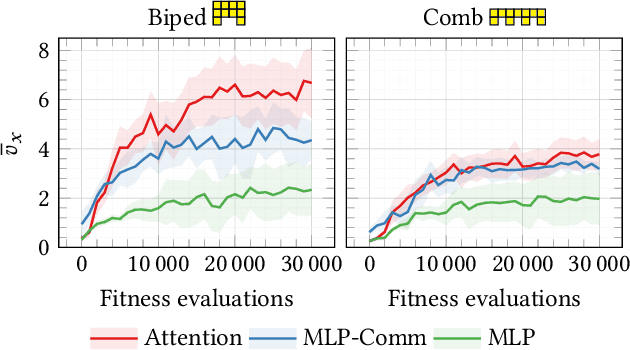
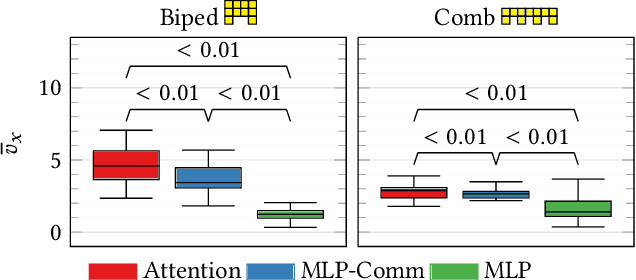
Modularity in robotics holds great potential. In principle, modular robots can be disassembled and reassembled in different robots, and possibly perform new tasks. Nevertheless, actually exploiting modularity is yet an unsolved problem: controllers usually rely on inter-module communication, a practical requirement that makes modules not perfectly interchangeable and thus limits their flexibility. Here, we focus on Voxel-based Soft Robots (VSRs), aggregations of mechanically identical elastic blocks. We use the same neural controller inside each voxel, but without any inter-voxel communication, hence enabling ideal conditions for modularity: modules are all equal and interchangeable. We optimize the parameters of the neural controller-shared among the voxels-by evolutionary computation. Crucially, we use a local self-attention mechanism inside the controller to overcome the absence of inter-module communication channels, thus enabling our robots to truly be driven by the collective intelligence of their modules. We show experimentally that the evolved robots are effective in the task of locomotion: thanks to self-attention, instances of the same controller embodied in the same robot can focus on different inputs. We also find that the evolved controllers generalize to unseen morphologies, after a short fine-tuning, suggesting that an inductive bias related to the task arises from true modularity.
Collective control of modular soft robots via embodied Spiking Neural Cellular Automata
Apr 05, 2022
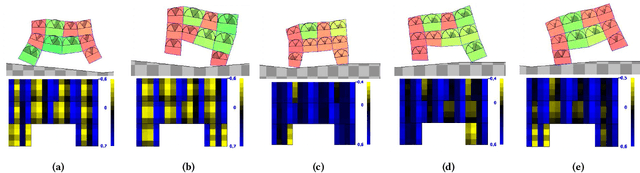
Voxel-based Soft Robots (VSRs) are a form of modular soft robots, composed of several deformable cubes, i.e., voxels. Each VSR is thus an ensemble of simple agents, namely the voxels, which must cooperate to give rise to the overall VSR behavior. Within this paradigm, collective intelligence plays a key role in enabling the emerge of coordination, as each voxel is independently controlled, exploiting only the local sensory information together with some knowledge passed from its direct neighbors (distributed or collective control). In this work, we propose a novel form of collective control, influenced by Neural Cellular Automata (NCA) and based on the bio-inspired Spiking Neural Networks: the embodied Spiking NCA (SNCA). We experiment with different variants of SNCA, and find them to be competitive with the state-of-the-art distributed controllers for the task of locomotion. In addition, our findings show significant improvement with respect to the baseline in terms of adaptability to unforeseen environmental changes, which could be a determining factor for physical practicability of VSRs.
Less is More: A Call to Focus on Simpler Models in Genetic Programming for Interpretable Machine Learning
Apr 05, 2022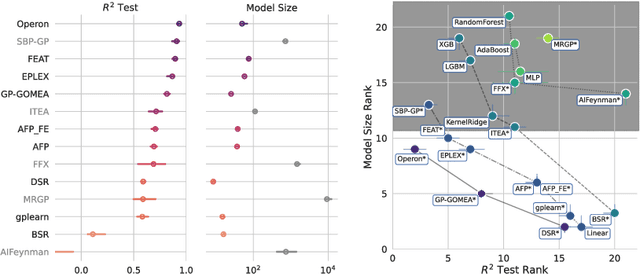
Interpretability can be critical for the safe and responsible use of machine learning models in high-stakes applications. So far, evolutionary computation (EC), in particular in the form of genetic programming (GP), represents a key enabler for the discovery of interpretable machine learning (IML) models. In this short paper, we argue that research in GP for IML needs to focus on searching in the space of low-complexity models, by investigating new kinds of search strategies and recombination methods. Moreover, based on our experience of bringing research into clinical practice, we believe that research should strive to design better ways of modeling and pursuing interpretability, for the obtained solutions to ultimately be most useful.
Model Learning with Personalized Interpretability Estimation (ML-PIE)
Apr 27, 2021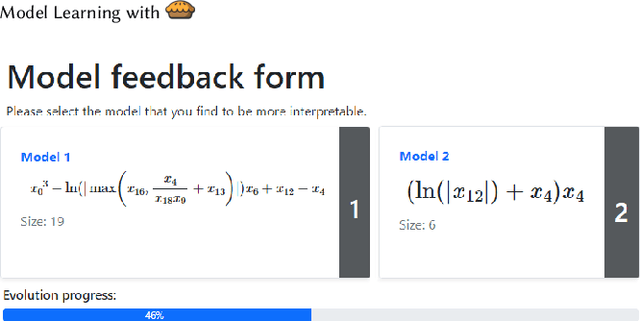
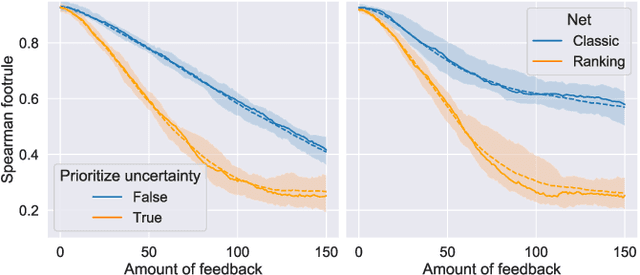
High-stakes applications require AI-generated models to be interpretable. Current algorithms for the synthesis of potentially interpretable models rely on objectives or regularization terms that represent interpretability only coarsely (e.g., model size) and are not designed for a specific user. Yet, interpretability is intrinsically subjective. In this paper, we propose an approach for the synthesis of models that are tailored to the user by enabling the user to steer the model synthesis process according to her or his preferences. We use a bi-objective evolutionary algorithm to synthesize models with trade-offs between accuracy and a user-specific notion of interpretability. The latter is estimated by a neural network that is trained concurrently to the evolution using the feedback of the user, which is collected using uncertainty-based active learning. To maximize usability, the user is only asked to tell, given two models at the time, which one is less complex. With experiments on two real-world datasets involving 61 participants, we find that our approach is capable of learning estimations of interpretability that can be very different for different users. Moreover, the users tend to prefer models found using the proposed approach over models found using non-personalized interpretability indices.
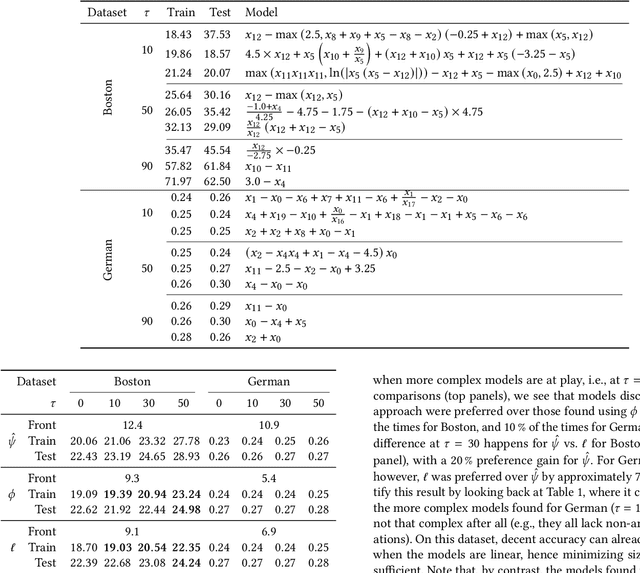
Learning a Formula of Interpretability to Learn Interpretable Formulas
May 28, 2020

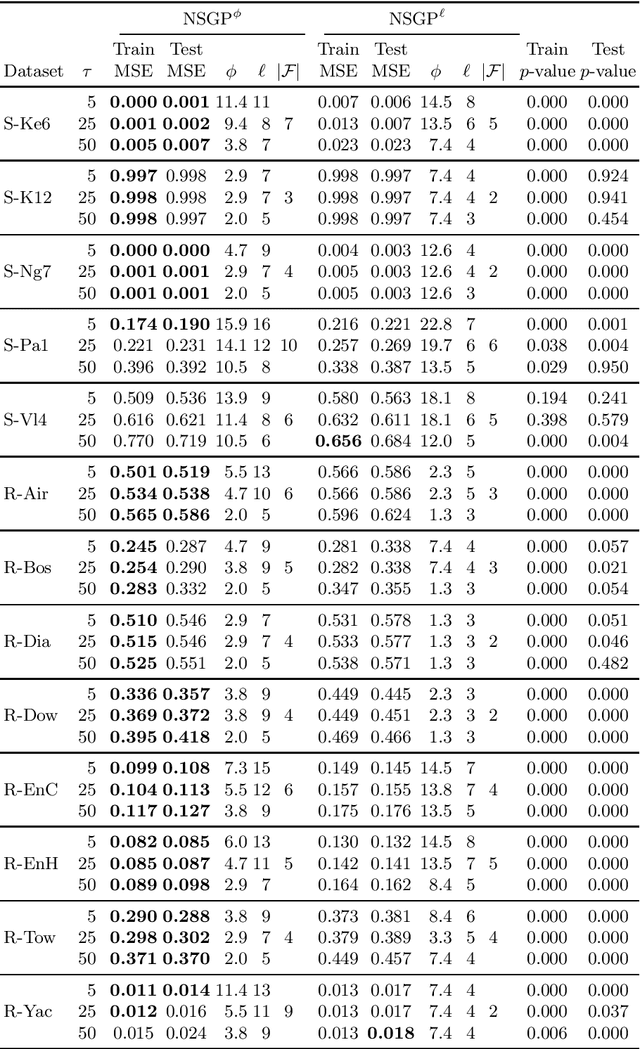
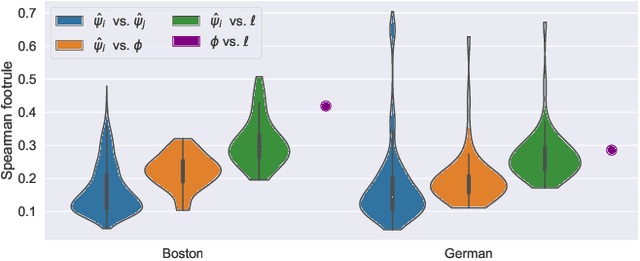
Many risk-sensitive applications require Machine Learning (ML) models to be interpretable. Attempts to obtain interpretable models typically rely on tuning, by trial-and-error, hyper-parameters of model complexity that are only loosely related to interpretability. We show that it is instead possible to take a meta-learning approach: an ML model of non-trivial Proxies of Human Interpretability (PHIs) can be learned from human feedback, then this model can be incorporated within an ML training process to directly optimize for interpretability. We show this for evolutionary symbolic regression. We first design and distribute a survey finalized at finding a link between features of mathematical formulas and two established PHIs, simulatability and decomposability. Next, we use the resulting dataset to learn an ML model of interpretability. Lastly, we query this model to estimate the interpretability of evolving solutions within bi-objective genetic programming. We perform experiments on five synthetic and eight real-world symbolic regression problems, comparing to the traditional use of solution size minimization. The results show that the use of our model leads to formulas that are, for a same level of accuracy-interpretability trade-off, either significantly more or equally accurate. Moreover, the formulas are also arguably more interpretable. Given the very positive results, we believe that our approach represents an important stepping stone for the design of next-generation interpretable (evolutionary) ML algorithms.
Design, Validation, and Case Studies of 2D-VSR-Sim, an Optimization-friendly Simulator of 2-D Voxel-based Soft Robots
Jan 27, 2020
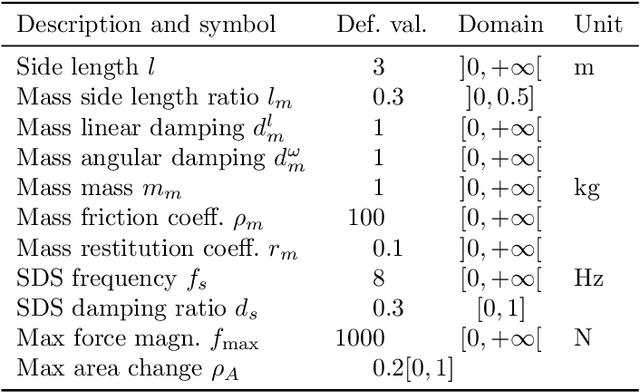
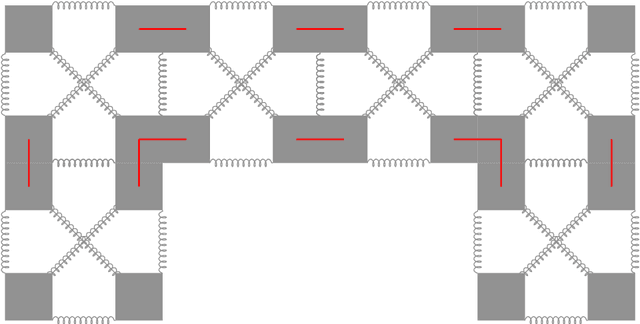

Voxel-based soft robots (VSRs) are aggregations of soft blocks whose design is amenable to optimization. We here present a software, 2D-VSR-Sim, for facilitating research concerning the optimization of VSRs body and brain. The software, written in Java, provides consistent interfaces for all the VSRs aspects suitable for optimization and considers by design the presence of sensing, i.e., the possibility of exploiting the feedback from the environment for controlling the VSR. We experimentally characterize, from a mechanical point of view, the VSRs that can be simulated with 2D-VSR-Sim and we discuss the computational burden of the simulation. Finally, we show how 2D-VSR-Sim can be used to repeat the experiments of significant previous studies and, in perspective, to provide experimental answers to a variety of research questions.