 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProblem-oriented AutoML in Clustering
Paper and Code
Sep 24, 2024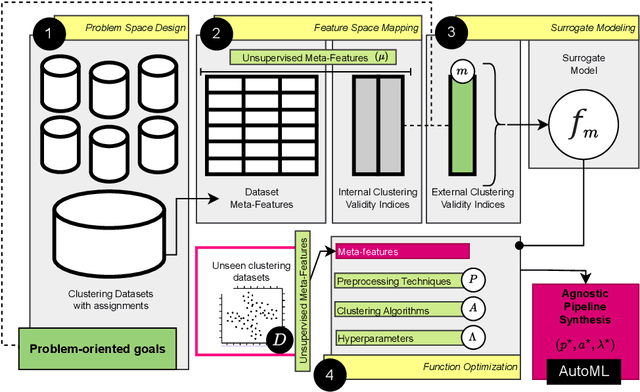

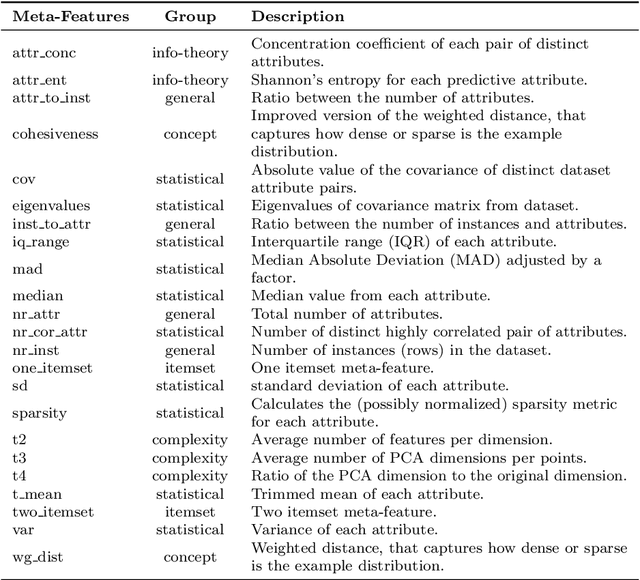
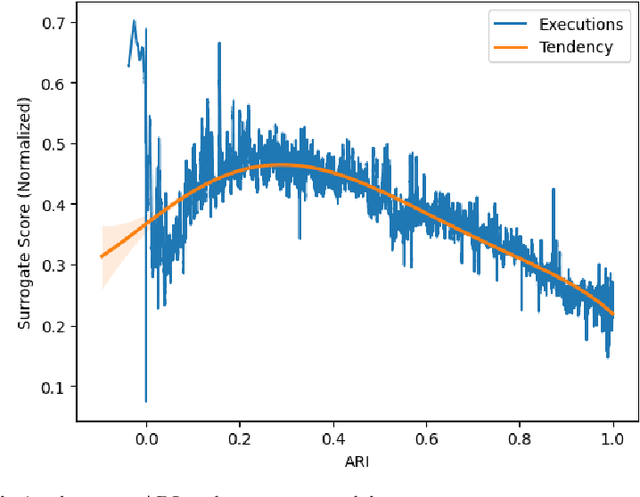
The Problem-oriented AutoML in Clustering (PoAC) framework introduces a novel, flexible approach to automating clustering tasks by addressing the shortcomings of traditional AutoML solutions. Conventional methods often rely on predefined internal Clustering Validity Indexes (CVIs) and static meta-features, limiting their adaptability and effectiveness across diverse clustering tasks. In contrast, PoAC establishes a dynamic connection between the clustering problem, CVIs, and meta-features, allowing users to customize these components based on the specific context and goals of their task. At its core, PoAC employs a surrogate model trained on a large meta-knowledge base of previous clustering datasets and solutions, enabling it to infer the quality of new clustering pipelines and synthesize optimal solutions for unseen datasets. Unlike many AutoML frameworks that are constrained by fixed evaluation metrics and algorithm sets, PoAC is algorithm-agnostic, adapting seamlessly to different clustering problems without requiring additional data or retraining. Experimental results demonstrate that PoAC not only outperforms state-of-the-art frameworks on a variety of datasets but also excels in specific tasks such as data visualization, and highlight its ability to dynamically adjust pipeline configurations based on dataset complexity.