 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable Deep Clustering for Time Series Data
Jul 28, 2025
Deep clustering uncovers hidden patterns and groups in complex time series data, yet its opaque decision-making limits use in safety-critical settings. This survey offers a structured overview of explainable deep clustering for time series, collecting current methods and their real-world applications. We thoroughly discuss and compare peer-reviewed and preprint papers through application domains across healthcare, finance, IoT, and climate science. Our analysis reveals that most work relies on autoencoder and attention architectures, with limited support for streaming, irregularly sampled, or privacy-preserved series, and interpretability is still primarily treated as an add-on. To push the field forward, we outline six research opportunities: (1) combining complex networks with built-in interpretability; (2) setting up clear, faithfulness-focused evaluation metrics for unsupervised explanations; (3) building explainers that adapt to live data streams; (4) crafting explanations tailored to specific domains; (5) adding human-in-the-loop methods that refine clusters and explanations together; and (6) improving our understanding of how time series clustering models work internally. By making interpretability a primary design goal rather than an afterthought, we propose the groundwork for the next generation of trustworthy deep clustering time series analytics.
Problem-oriented AutoML in Clustering
Sep 24, 2024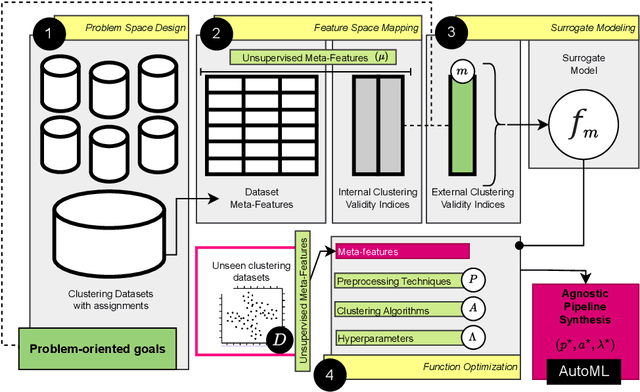

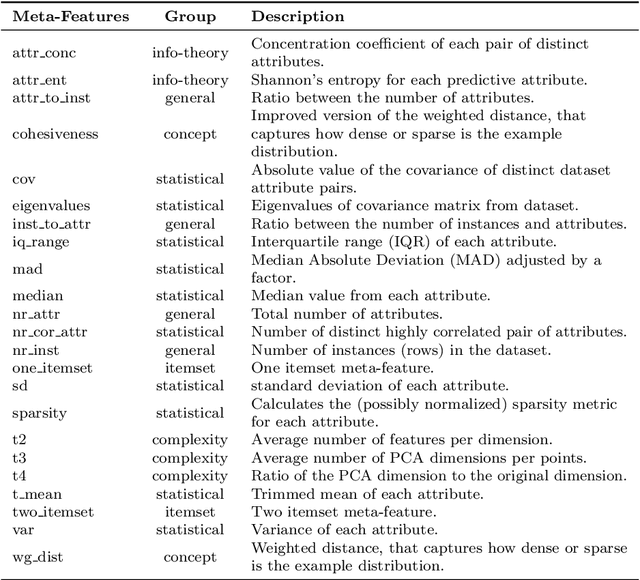
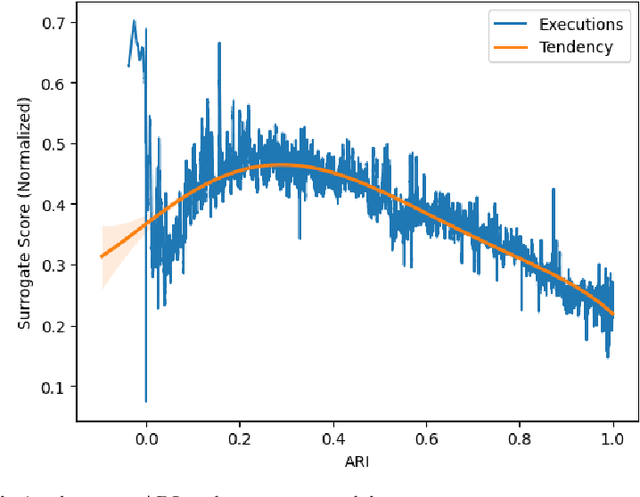
The Problem-oriented AutoML in Clustering (PoAC) framework introduces a novel, flexible approach to automating clustering tasks by addressing the shortcomings of traditional AutoML solutions. Conventional methods often rely on predefined internal Clustering Validity Indexes (CVIs) and static meta-features, limiting their adaptability and effectiveness across diverse clustering tasks. In contrast, PoAC establishes a dynamic connection between the clustering problem, CVIs, and meta-features, allowing users to customize these components based on the specific context and goals of their task. At its core, PoAC employs a surrogate model trained on a large meta-knowledge base of previous clustering datasets and solutions, enabling it to infer the quality of new clustering pipelines and synthesize optimal solutions for unseen datasets. Unlike many AutoML frameworks that are constrained by fixed evaluation metrics and algorithm sets, PoAC is algorithm-agnostic, adapting seamlessly to different clustering problems without requiring additional data or retraining. Experimental results demonstrate that PoAC not only outperforms state-of-the-art frameworks on a variety of datasets but also excels in specific tasks such as data visualization, and highlight its ability to dynamically adjust pipeline configurations based on dataset complexity.
ALPBench: A Benchmark for Active Learning Pipelines on Tabular Data
Jun 25, 2024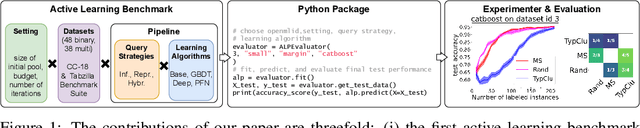

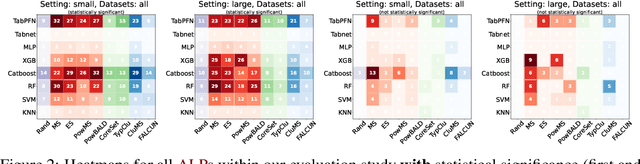

In settings where only a budgeted amount of labeled data can be afforded, active learning seeks to devise query strategies for selecting the most informative data points to be labeled, aiming to enhance learning algorithms' efficiency and performance. Numerous such query strategies have been proposed and compared in the active learning literature. However, the community still lacks standardized benchmarks for comparing the performance of different query strategies. This particularly holds for the combination of query strategies with different learning algorithms into active learning pipelines and examining the impact of the learning algorithm choice. To close this gap, we propose ALPBench, which facilitates the specification, execution, and performance monitoring of active learning pipelines. It has built-in measures to ensure evaluations are done reproducibly, saving exact dataset splits and hyperparameter settings of used algorithms. In total, ALPBench consists of 86 real-world tabular classification datasets and 5 active learning settings, yielding 430 active learning problems. To demonstrate its usefulness and broad compatibility with various learning algorithms and query strategies, we conduct an exemplary study evaluating 9 query strategies paired with 8 learning algorithms in 2 different settings. We provide ALPBench here: https://github.com/ValentinMargraf/ActiveLearningPipelines.
Decision Predicate Graphs: Enhancing Interpretability in Tree Ensembles
Apr 03, 2024Understanding the decisions of tree-based ensembles and their relationships is pivotal for machine learning model interpretation. Recent attempts to mitigate the human-in-the-loop interpretation challenge have explored the extraction of the decision structure underlying the model taking advantage of graph simplification and path emphasis. However, while these efforts enhance the visualisation experience, they may either result in a visually complex representation or compromise the interpretability of the original ensemble model. In addressing this challenge, especially in complex scenarios, we introduce the Decision Predicate Graph (DPG) as a model-agnostic tool to provide a global interpretation of the model. DPG is a graph structure that captures the tree-based ensemble model and learned dataset details, preserving the relations among features, logical decisions, and predictions towards emphasising insightful points. Leveraging well-known graph theory concepts, such as the notions of centrality and community, DPG offers additional quantitative insights into the model, complementing visualisation techniques, expanding the problem space descriptions, and offering diverse possibilities for extensions. Empirical experiments demonstrate the potential of DPG in addressing traditional benchmarks and complex classification scenarios.
Selecting Optimal Trace Clustering Pipelines with AutoML
Sep 01, 2021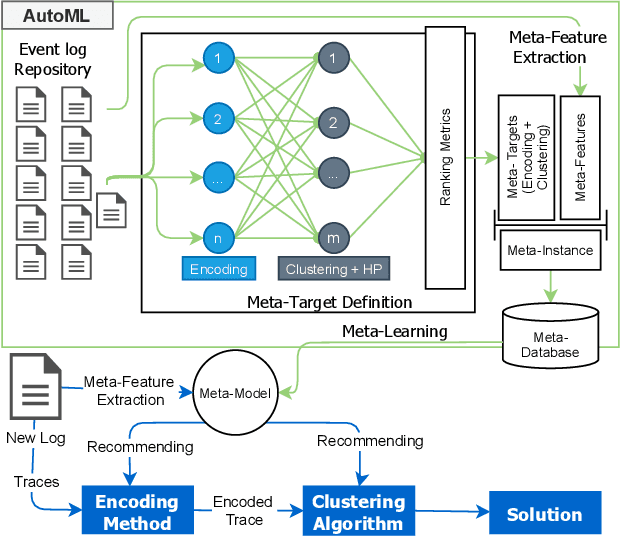


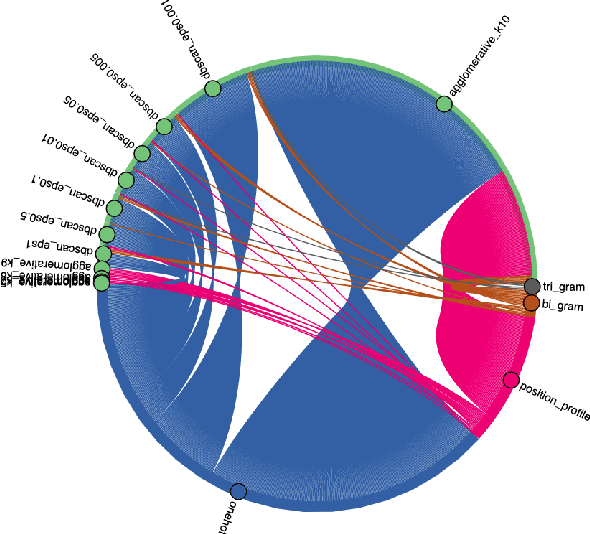
Trace clustering has been extensively used to preprocess event logs. By grouping similar behavior, these techniques guide the identification of sub-logs, producing more understandable models and conformance analytics. Nevertheless, little attention has been posed to the relationship between event log properties and clustering quality. In this work, we propose an Automatic Machine Learning (AutoML) framework to recommend the most suitable pipeline for trace clustering given an event log, which encompasses the encoding method, clustering algorithm, and its hyperparameters. Our experiments were conducted using a thousand event logs, four encoding techniques, and three clustering methods. Results indicate that our framework sheds light on the trace clustering problem and can assist users in choosing the best pipeline considering their scenario.
Using Meta-learning to Recommend Process Discovery Methods
Mar 23, 2021
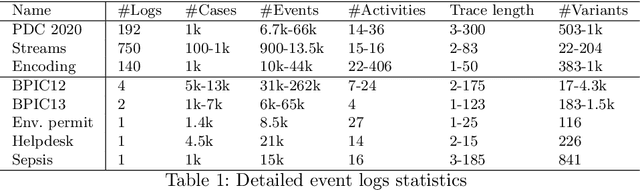
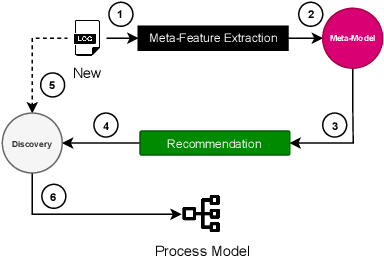

Process discovery methods have obtained remarkable achievements in Process Mining, delivering comprehensible process models to enhance management capabilities. However, selecting the suitable method for a specific event log highly relies on human expertise, hindering its broad application. Solutions based on Meta-learning (MtL) have been promising for creating systems with reduced human assistance. This paper presents a MtL solution for recommending process discovery methods that maximize model quality according to complementary dimensions. Thanks to our MtL pipeline, it was possible to recommend a discovery method with 92% of accuracy using light-weight features that describe the event log. Our experimental analysis also provided significant insights on the importance of log features in generating recommendations, paving the way to a deeper understanding of the discovery algorithms.