 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALPBench: A Benchmark for Active Learning Pipelines on Tabular Data
Jun 25, 2024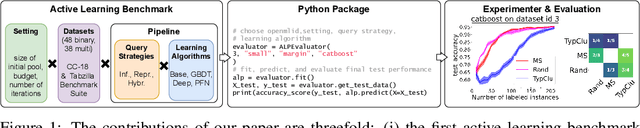

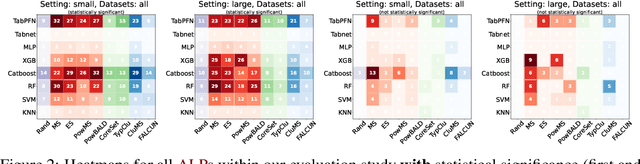

In settings where only a budgeted amount of labeled data can be afforded, active learning seeks to devise query strategies for selecting the most informative data points to be labeled, aiming to enhance learning algorithms' efficiency and performance. Numerous such query strategies have been proposed and compared in the active learning literature. However, the community still lacks standardized benchmarks for comparing the performance of different query strategies. This particularly holds for the combination of query strategies with different learning algorithms into active learning pipelines and examining the impact of the learning algorithm choice. To close this gap, we propose ALPBench, which facilitates the specification, execution, and performance monitoring of active learning pipelines. It has built-in measures to ensure evaluations are done reproducibly, saving exact dataset splits and hyperparameter settings of used algorithms. In total, ALPBench consists of 86 real-world tabular classification datasets and 5 active learning settings, yielding 430 active learning problems. To demonstrate its usefulness and broad compatibility with various learning algorithms and query strategies, we conduct an exemplary study evaluating 9 query strategies paired with 8 learning algorithms in 2 different settings. We provide ALPBench here: https://github.com/ValentinMargraf/ActiveLearningPipelines.
How To Overcome Confirmation Bias in Semi-Supervised Image Classification By Active Learning
Aug 16, 2023Do we need active learning? The rise of strong deep semi-supervised methods raises doubt about the usability of active learning in limited labeled data settings. This is caused by results showing that combining semi-supervised learning (SSL) methods with a random selection for labeling can outperform existing active learning (AL) techniques. However, these results are obtained from experiments on well-established benchmark datasets that can overestimate the external validity. However, the literature lacks sufficient research on the performance of active semi-supervised learning methods in realistic data scenarios, leaving a notable gap in our understanding. Therefore we present three data challenges common in real-world applications: between-class imbalance, within-class imbalance, and between-class similarity. These challenges can hurt SSL performance due to confirmation bias. We conduct experiments with SSL and AL on simulated data challenges and find that random sampling does not mitigate confirmation bias and, in some cases, leads to worse performance than supervised learning. In contrast, we demonstrate that AL can overcome confirmation bias in SSL in these realistic settings. Our results provide insights into the potential of combining active and semi-supervised learning in the presence of common real-world challenges, which is a promising direction for robust methods when learning with limited labeled data in real-world applications.
DiffusAL: Coupling Active Learning with Graph Diffusion for Label-Efficient Node Classification
Jul 31, 2023Node classification is one of the core tasks on attributed graphs, but successful graph learning solutions require sufficiently labeled data. To keep annotation costs low, active graph learning focuses on selecting the most qualitative subset of nodes that maximizes label efficiency. However, deciding which heuristic is best suited for an unlabeled graph to increase label efficiency is a persistent challenge. Existing solutions either neglect aligning the learned model and the sampling method or focus only on limited selection aspects. They are thus sometimes worse or only equally good as random sampling. In this work, we introduce a novel active graph learning approach called DiffusAL, showing significant robustness in diverse settings. Toward better transferability between different graph structures, we combine three independent scoring functions to identify the most informative node samples for labeling in a parameter-free way: i) Model Uncertainty, ii) Diversity Component, and iii) Node Importance computed via graph diffusion heuristics. Most of our calculations for acquisition and training can be pre-processed, making DiffusAL more efficient compared to approaches combining diverse selection criteria and similarly fast as simpler heuristics. Our experiments on various benchmark datasets show that, unlike previous methods, our approach significantly outperforms random selection in 100% of all datasets and labeling budgets tested.