 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALPBench: A Benchmark for Active Learning Pipelines on Tabular Data
Paper and Code
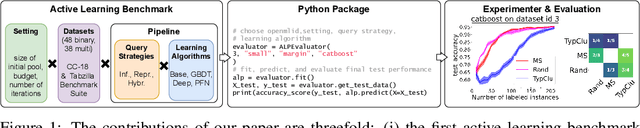

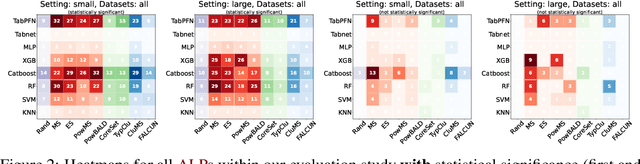

In settings where only a budgeted amount of labeled data can be afforded, active learning seeks to devise query strategies for selecting the most informative data points to be labeled, aiming to enhance learning algorithms' efficiency and performance. Numerous such query strategies have been proposed and compared in the active learning literature. However, the community still lacks standardized benchmarks for comparing the performance of different query strategies. This particularly holds for the combination of query strategies with different learning algorithms into active learning pipelines and examining the impact of the learning algorithm choice. To close this gap, we propose ALPBench, which facilitates the specification, execution, and performance monitoring of active learning pipelines. It has built-in measures to ensure evaluations are done reproducibly, saving exact dataset splits and hyperparameter settings of used algorithms. In total, ALPBench consists of 86 real-world tabular classification datasets and 5 active learning settings, yielding 430 active learning problems. To demonstrate its usefulness and broad compatibility with various learning algorithms and query strategies, we conduct an exemplary study evaluating 9 query strategies paired with 8 learning algorithms in 2 different settings. We provide ALPBench here: https://github.com/ValentinMargraf/ActiveLearningPipelines.