 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-aware PINNs for Turbulent Flow Prediction
Dec 02, 2024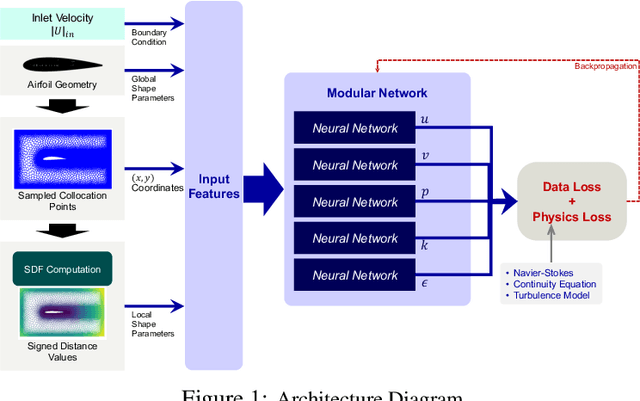
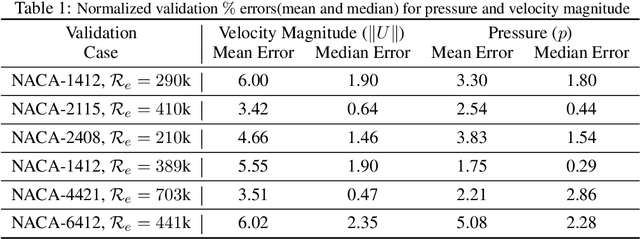
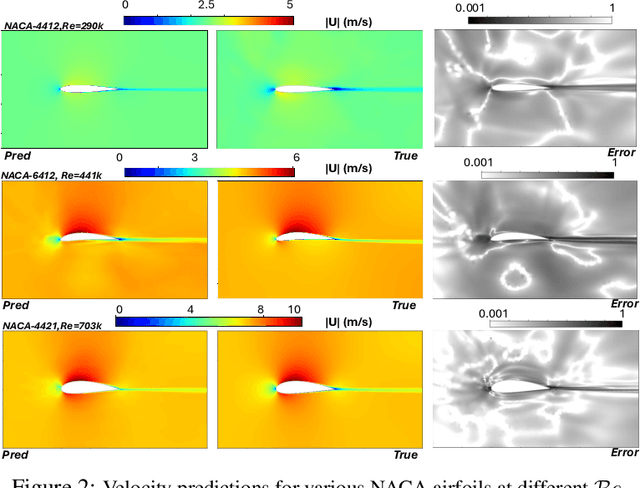
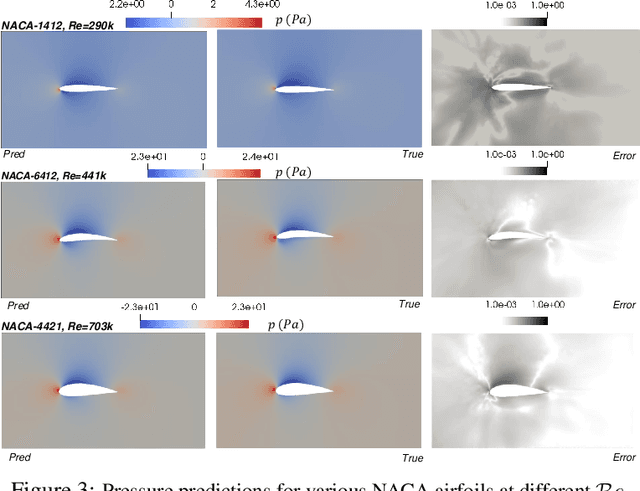
Design exploration or optimization using computational fluid dynamics (CFD) is commonly used in the industry. Geometric variation is a key component of such design problems, especially in turbulent flow scenarios, which involves running costly simulations at every design iteration. While parametric RANS-PINN type approaches have been proven to make effective turbulent surrogates, as a means of predicting unknown Reynolds number flows for a given geometry at near real-time, geometry aware physics informed surrogates with the ability to predict varying geometries are a relatively less studied topic. A novel geometry aware parametric PINN surrogate model has been created, which can predict flow fields for NACA 4 digit airfoils in turbulent conditions, for unseen shapes as well as inlet flow conditions. A local+global approach for embedding has been proposed, where known global design parameters for an airfoil as well as local SDF values can be used as inputs to the model along with velocity inlet/Reynolds number ($\mathcal{R}_e$) to predict the flow fields. A RANS formulation of the Navier-Stokes equations with a 2-equation k-epsilon turbulence model has been used for the PDE losses, in addition to limited CFD data from 8 different NACA airfoils for training. The models have then been validated with unknown NACA airfoils at unseen Reynolds numbers.
DiffusAL: Coupling Active Learning with Graph Diffusion for Label-Efficient Node Classification
Jul 31, 2023Node classification is one of the core tasks on attributed graphs, but successful graph learning solutions require sufficiently labeled data. To keep annotation costs low, active graph learning focuses on selecting the most qualitative subset of nodes that maximizes label efficiency. However, deciding which heuristic is best suited for an unlabeled graph to increase label efficiency is a persistent challenge. Existing solutions either neglect aligning the learned model and the sampling method or focus only on limited selection aspects. They are thus sometimes worse or only equally good as random sampling. In this work, we introduce a novel active graph learning approach called DiffusAL, showing significant robustness in diverse settings. Toward better transferability between different graph structures, we combine three independent scoring functions to identify the most informative node samples for labeling in a parameter-free way: i) Model Uncertainty, ii) Diversity Component, and iii) Node Importance computed via graph diffusion heuristics. Most of our calculations for acquisition and training can be pre-processed, making DiffusAL more efficient compared to approaches combining diverse selection criteria and similarly fast as simpler heuristics. Our experiments on various benchmark datasets show that, unlike previous methods, our approach significantly outperforms random selection in 100% of all datasets and labeling budgets tested.
NF-GNN: Network Flow Graph Neural Networks for Malware Detection and Classification
Apr 04, 2021

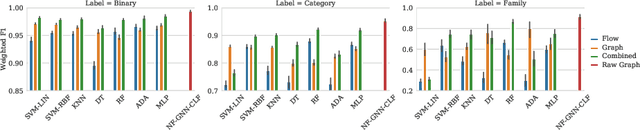

Malicious software (malware) poses an increasing threat to the security of communication systems, as the number of interconnected mobile devices increases exponentially. While some existing malware detection and classification approaches successfully leverage network traffic data, they treat network flows between pairs of endpoints independently and thus fail to leverage the rich structural dependencies in the complete network. Our approach first extracts flow graphs and subsequently classifies them using a novel graph neural network model. We present three variants of our base model, which all support malware detection and classification in supervised and unsupervised settings. We evaluate our approach on flow graphs that we extract from a recently published dataset for mobile malware detection that addresses several issues with previously available datasets. Experiments on four different prediction tasks consistently demonstrate the advantages of our approach and show that our graph neural network model can boost detection performance by a significant margin.
Learning Self-Expression Metrics for Scalable and Inductive Subspace Clustering
Sep 27, 2020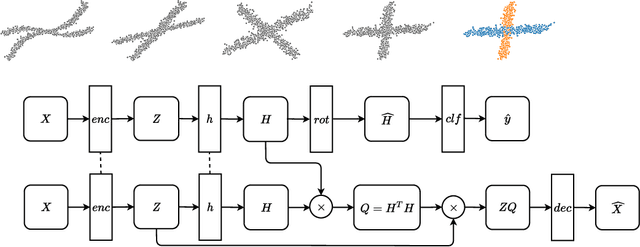

Subspace clustering has established itself as a state-of-the-art approach to clustering high-dimensional data. In particular, methods relying on the self-expressiveness property have recently proved especially successful. However, they suffer from two major shortcomings: First, a quadratic-size coefficient matrix is learned directly, preventing these methods from scaling beyond small datasets. Secondly, the trained models are transductive and thus cannot be used to cluster out-of-sample data unseen during training. Instead of learning self-expression coefficients directly, we propose a novel metric learning approach to learn instead a subspace affinity function using a siamese neural network architecture. Consequently, our model benefits from a constant number of parameters and a constant-size memory footprint, allowing it to scale to considerably larger datasets. In addition, we can formally show that out model is still able to exactly recover subspace clusters given an independence assumption. The siamese architecture in combination with a novel geometric classifier further makes our model inductive, allowing it to cluster out-of-sample data. Additionally, non-linear clusters can be detected by simply adding an auto-encoder module to the architecture. The whole model can then be trained end-to-end in a self-supervised manner. This work in progress reports promising preliminary results on the MNIST dataset. In the spirit of reproducible research, me make all code publicly available. In future work we plan to investigate several extensions of our model and to expand experimental evaluation.
PushNet: Efficient and Adaptive Neural Message Passing
Mar 05, 2020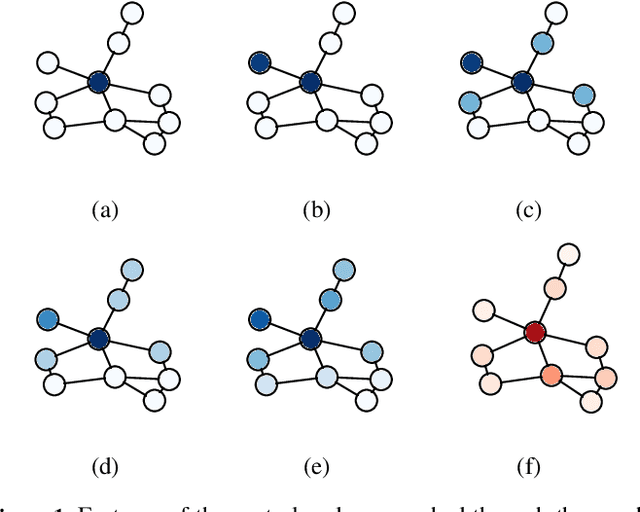
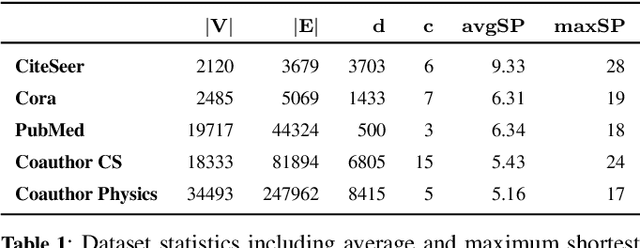


Message passing neural networks have recently evolved into a state-of-the-art approach to representation learning on graphs. Existing methods perform synchronous message passing along all edges in multiple subsequent rounds and consequently suffer from various shortcomings: Propagation schemes are inflexible since they are restricted to $k$-hop neighborhoods and insensitive to actual demands of information propagation. Further, long-range dependencies cannot be modeled adequately and learned representations are based on correlations of fixed locality. These issues prevent existing methods from reaching their full potential in terms of prediction performance. Instead, we consider a novel asynchronous message passing approach where information is pushed only along the most relevant edges until convergence. Our proposed algorithm can equivalently be formulated as a single synchronous message passing iteration using a suitable neighborhood function, thus sharing the advantages of existing methods while addressing their central issues. The resulting neural network utilizes a node-adaptive receptive field derived from meaningful sparse node neighborhoods. In addition, by learning and combining node representations over differently sized neighborhoods, our model is able to capture correlations on multiple scales. We further propose variants of our base model with different inductive bias. Empirical results are provided for semi-supervised node classification on five real-world datasets following a rigorous evaluation protocol. We find that our models outperform competitors on all datasets in terms of accuracy with statistical significance. In some cases, our models additionally provide faster runtime.
Semi-Supervised Learning on Graphs Based on Local Label Distributions
May 22, 2018
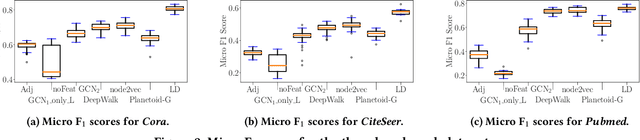
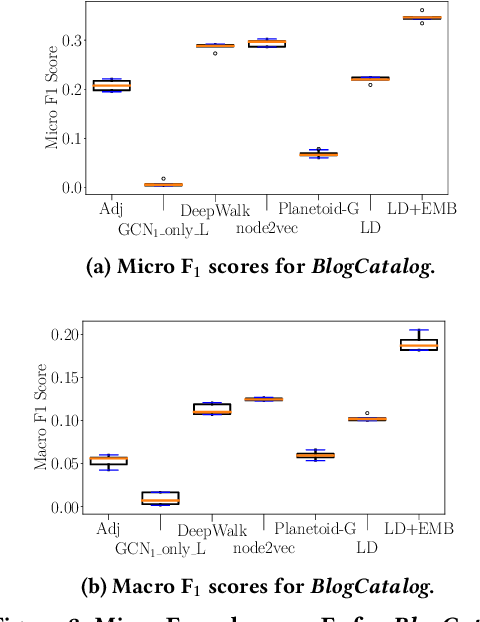
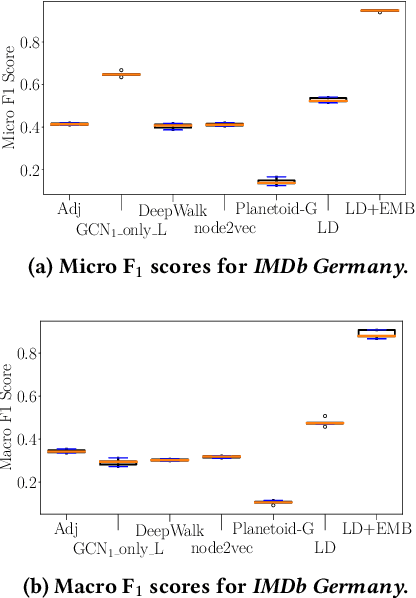
Most approaches that tackle the problem of node classification consider nodes to be similar, if they have shared neighbors or are close to each other in the graph. Recent methods for attributed graphs additionally take attributes of neighboring nodes into account. We argue that the class labels of the neighbors bear important information and considering them helps to improve classification quality. Two nodes which are similar based on class labels in their neighborhood do not need to be close-by in the graph and may even belong to different connected components. In this work, we propose a novel approach for the semi-supervised node classification. Precisely, we propose a new node embedding which is based on the class labels in the local neighborhood of a node. We show that this is a different setting from attribute-based embeddings and thus, we propose a new method to learn label-based node embeddings which can mirror a variety of relations between the class labels of neighboring nodes. Our experimental evaluation demonstrates that our new methods can significantly improve the prediction quality on real world data sets.