 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaRaFFusion: Improving 2D Semantic Segmentation with Camera-Radar Point Cloud Fusion and Zero-Shot Image Inpainting
May 06, 2025Segmenting objects in an environment is a crucial task for autonomous driving and robotics, as it enables a better understanding of the surroundings of each agent. Although camera sensors provide rich visual details, they are vulnerable to adverse weather conditions. In contrast, radar sensors remain robust under such conditions, but often produce sparse and noisy data. Therefore, a promising approach is to fuse information from both sensors. In this work, we propose a novel framework to enhance camera-only baselines by integrating a diffusion model into a camera-radar fusion architecture. We leverage radar point features to create pseudo-masks using the Segment-Anything model, treating the projected radar points as point prompts. Additionally, we propose a noise reduction unit to denoise these pseudo-masks, which are further used to generate inpainted images that complete the missing information in the original images. Our method improves the camera-only segmentation baseline by 2.63% in mIoU and enhances our camera-radar fusion architecture by 1.48% in mIoU on the Waterscenes dataset. This demonstrates the effectiveness of our approach for semantic segmentation using camera-radar fusion under adverse weather conditions.
Dying Clusters Is All You Need -- Deep Clustering With an Unknown Number of Clusters
Oct 12, 2024
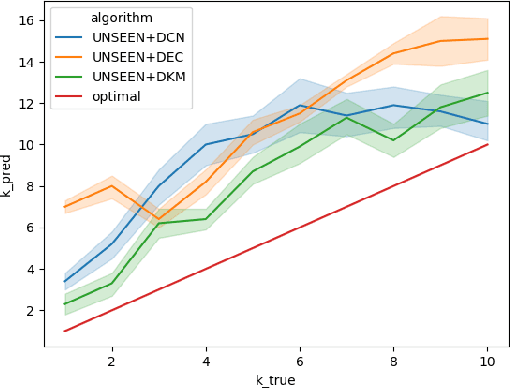


Finding meaningful groups, i.e., clusters, in high-dimensional data such as images or texts without labeled data at hand is an important challenge in data mining. In recent years, deep clustering methods have achieved remarkable results in these tasks. However, most of these methods require the user to specify the number of clusters in advance. This is a major limitation since the number of clusters is typically unknown if labeled data is unavailable. Thus, an area of research has emerged that addresses this problem. Most of these approaches estimate the number of clusters separated from the clustering process. This results in a strong dependency of the clustering result on the quality of the initial embedding. Other approaches are tailored to specific clustering processes, making them hard to adapt to other scenarios. In this paper, we propose UNSEEN, a general framework that, starting from a given upper bound, is able to estimate the number of clusters. To the best of our knowledge, it is the first method that can be easily combined with various deep clustering algorithms. We demonstrate the applicability of our approach by combining UNSEEN with the popular deep clustering algorithms DCN, DEC, and DKM and verify its effectiveness through an extensive experimental evaluation on several image and tabular datasets. Moreover, we perform numerous ablations to analyze our approach and show the importance of its components. The code is available at: https://github.com/collinleiber/UNSEEN
Autoregressive Policy Optimization for Constrained Allocation Tasks
Sep 27, 2024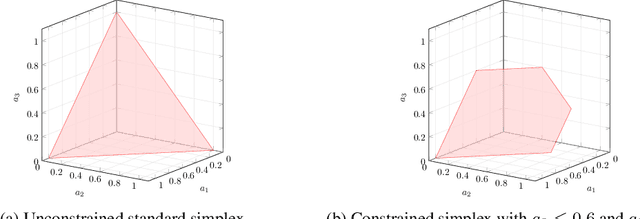
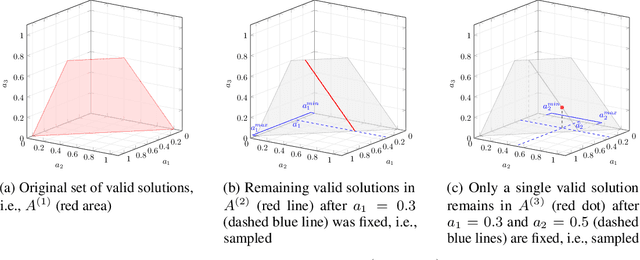
Allocation tasks represent a class of problems where a limited amount of resources must be allocated to a set of entities at each time step. Prominent examples of this task include portfolio optimization or distributing computational workloads across servers. Allocation tasks are typically bound by linear constraints describing practical requirements that have to be strictly fulfilled at all times. In portfolio optimization, for example, investors may be obligated to allocate less than 30\% of the funds into a certain industrial sector in any investment period. Such constraints restrict the action space of allowed allocations in intricate ways, which makes learning a policy that avoids constraint violations difficult. In this paper, we propose a new method for constrained allocation tasks based on an autoregressive process to sequentially sample allocations for each entity. In addition, we introduce a novel de-biasing mechanism to counter the initial bias caused by sequential sampling. We demonstrate the superior performance of our approach compared to a variety of Constrained Reinforcement Learning (CRL) methods on three distinct constrained allocation tasks: portfolio optimization, computational workload distribution, and a synthetic allocation benchmark. Our code is available at: https://github.com/niklasdbs/paspo
Context Matters: Leveraging Spatiotemporal Metadata for Semi-Supervised Learning on Remote Sensing Images
Apr 29, 2024Remote sensing projects typically generate large amounts of imagery that can be used to train powerful deep neural networks. However, the amount of labeled images is often small, as remote sensing applications generally require expert labelers. Thus, semi-supervised learning (SSL), i.e., learning with a small pool of labeled and a larger pool of unlabeled data, is particularly useful in this domain. Current SSL approaches generate pseudo-labels from model predictions for unlabeled samples. As the quality of these pseudo-labels is crucial for performance, utilizing additional information to improve pseudo-label quality yields a promising direction. For remote sensing images, geolocation and recording time are generally available and provide a valuable source of information as semantic concepts, such as land cover, are highly dependent on spatiotemporal context, e.g., due to seasonal effects and vegetation zones. In this paper, we propose to exploit spatiotemporal metainformation in SSL to improve the quality of pseudo-labels and, therefore, the final model performance. We show that directly adding the available metadata to the input of the predictor at test time degenerates the prediction quality for metadata outside the spatiotemporal distribution of the training set. Thus, we propose a teacher-student SSL framework where only the teacher network uses metainformation to improve the quality of pseudo-labels on the training set. Correspondingly, our student network benefits from the improved pseudo-labels but does not receive metadata as input, making it invariant to spatiotemporal shifts at test time. Furthermore, we propose methods for encoding and injecting spatiotemporal information into the model and introduce a novel distillation mechanism to enhance the knowledge transfer between teacher and student. Our framework dubbed Spatiotemporal SSL can be easily combined with several stat...
A Time-Inhomogeneous Markov Model for Resource Availability under Sparse Observations
Apr 18, 2024Accurate spatio-temporal information about the current situation is crucial for smart city applications such as modern routing algorithms. Often, this information describes the state of stationary resources, e.g. the availability of parking bays, charging stations or the amount of people waiting for a vehicle to pick them up near a given location. To exploit this kind of information, predicting future states of the monitored resources is often mandatory because a resource might change its state within the time until it is needed. To train an accurate predictive model, it is often not possible to obtain a continuous time series on the state of the resource. For example, the information might be collected from traveling agents visiting the resource with an irregular frequency. Thus, it is necessary to develop methods which work on sparse observations for training and prediction. In this paper, we propose time-inhomogeneous discrete Markov models to allow accurate prediction even when the frequency of observation is very rare. Our new model is able to blend recent observations with historic data and also provide useful probabilistic estimates for future states. Since resources availability in a city is typically time-dependent, our Markov model is time-inhomogeneous and cyclic within a predefined time interval. To train our model, we propose a modified Baum-Welch algorithm. Evaluations on real-world datasets of parking bay availability show that our new method indeed yields good results compared to methods being trained on complete data and non-cyclic variants.
* 11 pages, long version of a paper published at 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (SIGSPATIAL 2018)
Efficient Parking Search using Shared Fleet Data
Apr 16, 2024Finding an available on-street parking spot is a relevant problem of day-to-day life. In recent years, cities such as Melbourne and San Francisco deployed sensors that provide real-time information about the occupation of parking spots. Finding a free parking spot in such a smart environment can be modeled and solved as a Markov decision process (MDP). The problem has to consider uncertainty as available parking spots might not remain available until arrival due to other vehicles also claiming spots in the meantime. Knowing the parking intention of every vehicle in the environment would eliminate this uncertainty. Unfortunately, it does currently not seem realistic to have such data from all vehicles. In contrast, acquiring data from a subset of vehicles or a vehicle fleet appears feasible and has the potential to reduce uncertainty. In this paper, we examine the question of how useful sharing data within a vehicle fleet might be for the search times of particular drivers. We use fleet data to better estimate the availability of parking spots at arrival. Since optimal solutions for large scenarios are infeasible, we base our method on approximate solutions, which have been shown to perform well in single-agent settings. Our experiments are conducted on a simulation using real-world and synthetic data from the city of Melbourne. The results indicate that fleet data can significantly reduce search times for an available parking spot.
* Long Version; published at 2021 22nd IEEE International Conference on Mobile Data Management (MDM)
Simplex Decomposition for Portfolio Allocation Constraints in Reinforcement Learning
Apr 16, 2024Portfolio optimization tasks describe sequential decision problems in which the investor's wealth is distributed across a set of assets. Allocation constraints are used to enforce minimal or maximal investments into particular subsets of assets to control for objectives such as limiting the portfolio's exposure to a certain sector due to environmental concerns. Although methods for constrained Reinforcement Learning (CRL) can optimize policies while considering allocation constraints, it can be observed that these general methods yield suboptimal results. In this paper, we propose a novel approach to handle allocation constraints based on a decomposition of the constraint action space into a set of unconstrained allocation problems. In particular, we examine this approach for the case of two constraints. For example, an investor may wish to invest at least a certain percentage of the portfolio into green technologies while limiting the investment in the fossil energy sector. We show that the action space of the task is equivalent to the decomposed action space, and introduce a new reinforcement learning (RL) approach CAOSD, which is built on top of the decomposition. The experimental evaluation on real-world Nasdaq-100 data demonstrates that our approach consistently outperforms state-of-the-art CRL benchmarks for portfolio optimization.
Spatial-Aware Deep Reinforcement Learning for the Traveling Officer Problem
Jan 11, 2024The traveling officer problem (TOP) is a challenging stochastic optimization task. In this problem, a parking officer is guided through a city equipped with parking sensors to fine as many parking offenders as possible. A major challenge in TOP is the dynamic nature of parking offenses, which randomly appear and disappear after some time, regardless of whether they have been fined. Thus, solutions need to dynamically adjust to currently fineable parking offenses while also planning ahead to increase the likelihood that the officer arrives during the offense taking place. Though various solutions exist, these methods often struggle to take the implications of actions on the ability to fine future parking violations into account. This paper proposes SATOP, a novel spatial-aware deep reinforcement learning approach for TOP. Our novel state encoder creates a representation of each action, leveraging the spatial relationships between parking spots, the agent, and the action. Furthermore, we propose a novel message-passing module for learning future inter-action correlations in the given environment. Thus, the agent can estimate the potential to fine further parking violations after executing an action. We evaluate our method using an environment based on real-world data from Melbourne. Our results show that SATOP consistently outperforms state-of-the-art TOP agents and is able to fine up to 22% more parking offenses.
GRAtt-VIS: Gated Residual Attention for Auto Rectifying Video Instance Segmentation
May 26, 2023Recent trends in Video Instance Segmentation (VIS) have seen a growing reliance on online methods to model complex and lengthy video sequences. However, the degradation of representation and noise accumulation of the online methods, especially during occlusion and abrupt changes, pose substantial challenges. Transformer-based query propagation provides promising directions at the cost of quadratic memory attention. However, they are susceptible to the degradation of instance features due to the above-mentioned challenges and suffer from cascading effects. The detection and rectification of such errors remain largely underexplored. To this end, we introduce \textbf{GRAtt-VIS}, \textbf{G}ated \textbf{R}esidual \textbf{Att}ention for \textbf{V}ideo \textbf{I}nstance \textbf{S}egmentation. Firstly, we leverage a Gumbel-Softmax-based gate to detect possible errors in the current frame. Next, based on the gate activation, we rectify degraded features from its past representation. Such a residual configuration alleviates the need for dedicated memory and provides a continuous stream of relevant instance features. Secondly, we propose a novel inter-instance interaction using gate activation as a mask for self-attention. This masking strategy dynamically restricts the unrepresentative instance queries in the self-attention and preserves vital information for long-term tracking. We refer to this novel combination of Gated Residual Connection and Masked Self-Attention as \textbf{GRAtt} block, which can easily be integrated into the existing propagation-based framework. Further, GRAtt blocks significantly reduce the attention overhead and simplify dynamic temporal modeling. GRAtt-VIS achieves state-of-the-art performance on YouTube-VIS and the highly challenging OVIS dataset, significantly improving over previous methods. Code is available at \url{https://github.com/Tanveer81/GRAttVIS}.
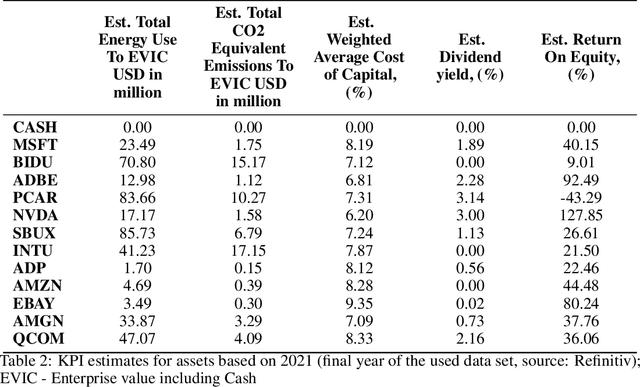
MapFormer: Boosting Change Detection by Using Pre-change Information
Mar 31, 2023
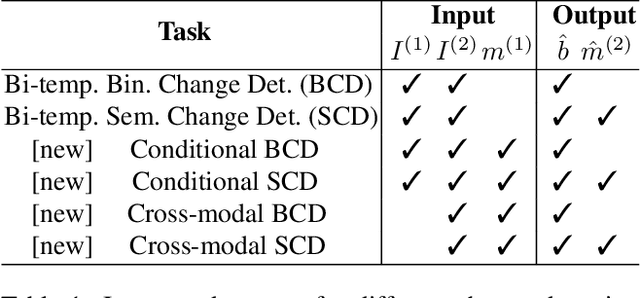

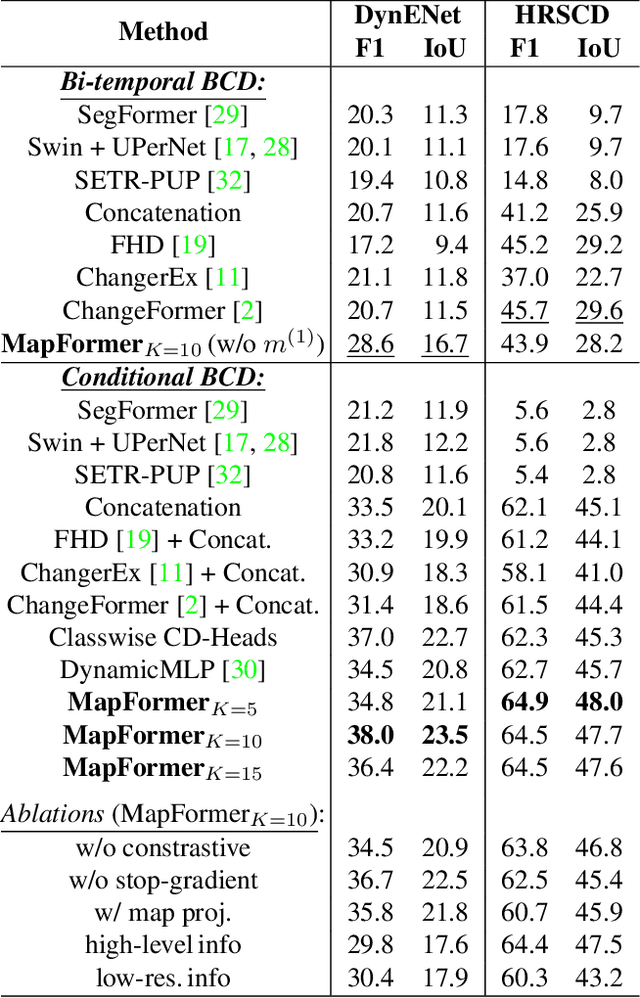
Change detection in remote sensing imagery is essential for a variety of applications such as urban planning, disaster management, and climate research. However, existing methods for identifying semantically changed areas overlook the availability of semantic information in the form of existing maps describing features of the earth's surface. In this paper, we leverage this information for change detection in bi-temporal images. We show that the simple integration of the additional information via concatenation of latent representations suffices to significantly outperform state-of-the-art change detection methods. Motivated by this observation, we propose the new task of Conditional Change Detection, where pre-change semantic information is used as input next to bi-temporal images. To fully exploit the extra information, we propose MapFormer, a novel architecture based on a multi-modal feature fusion module that allows for feature processing conditioned on the available semantic information. We further employ a supervised, cross-modal contrastive loss to guide the learning of visual representations. Our approach outperforms existing change detection methods by an absolute 11.7% and 18.4% in terms of binary change IoU on DynamicEarthNet and HRSCD, respectively. Furthermore, we demonstrate the robustness of our approach to the quality of the pre-change semantic information and the absence pre-change imagery. The code will be made publicly available.