 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDying Clusters Is All You Need -- Deep Clustering With an Unknown Number of Clusters
Paper and Code

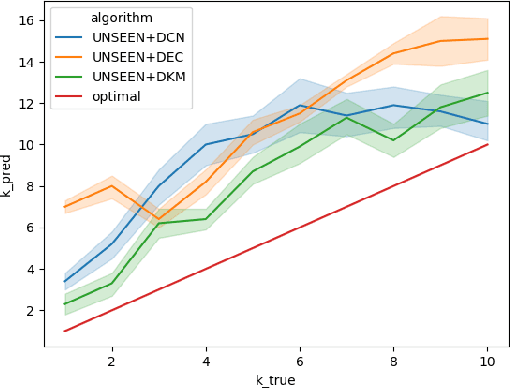


Finding meaningful groups, i.e., clusters, in high-dimensional data such as images or texts without labeled data at hand is an important challenge in data mining. In recent years, deep clustering methods have achieved remarkable results in these tasks. However, most of these methods require the user to specify the number of clusters in advance. This is a major limitation since the number of clusters is typically unknown if labeled data is unavailable. Thus, an area of research has emerged that addresses this problem. Most of these approaches estimate the number of clusters separated from the clustering process. This results in a strong dependency of the clustering result on the quality of the initial embedding. Other approaches are tailored to specific clustering processes, making them hard to adapt to other scenarios. In this paper, we propose UNSEEN, a general framework that, starting from a given upper bound, is able to estimate the number of clusters. To the best of our knowledge, it is the first method that can be easily combined with various deep clustering algorithms. We demonstrate the applicability of our approach by combining UNSEEN with the popular deep clustering algorithms DCN, DEC, and DKM and verify its effectiveness through an extensive experimental evaluation on several image and tabular datasets. Moreover, we perform numerous ablations to analyze our approach and show the importance of its components. The code is available at: https://github.com/collinleiber/UNSEEN