 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Compression for Tabular Foundation Models
Feb 05, 2026The long-standing dominance of gradient-boosted decision trees for tabular data has recently been challenged by in-context learning tabular foundation models. In-context learning methods fit and predict in one forward pass without parameter updates by leveraging the training data as context for predicting on query test points. While recent tabular foundation models achieve state-of-the-art performance, their transformer architecture based on the attention mechanism has quadratic complexity regarding dataset size, which in turn increases the overhead on training and inference time, and limits the capacity of the models to handle large-scale datasets. In this work, we propose TACO, an end-to-end tabular compression model that compresses the training dataset in a latent space. We test our method on the TabArena benchmark, where our proposed method is up to 94x faster in inference time, while consuming up to 97\% less memory compared to the state-of-the-art tabular transformer architecture, all while retaining performance without significant degradation. Lastly, our method not only scales better with increased dataset sizes, but it also achieves better performance compared to other baselines.
SHAining on Process Mining: Explaining Event Log Characteristics Impact on Algorithms
Sep 10, 2025Process mining aims to extract and analyze insights from event logs, yet algorithm metric results vary widely depending on structural event log characteristics. Existing work often evaluates algorithms on a fixed set of real-world event logs but lacks a systematic analysis of how event log characteristics impact algorithms individually. Moreover, since event logs are generated from processes, where characteristics co-occur, we focus on associational rather than causal effects to assess how strong the overlapping individual characteristic affects evaluation metrics without assuming isolated causal effects, a factor often neglected by prior work. We introduce SHAining, the first approach to quantify the marginal contribution of varying event log characteristics to process mining algorithms' metrics. Using process discovery as a downstream task, we analyze over 22,000 event logs covering a wide span of characteristics to uncover which affect algorithms across metrics (e.g., fitness, precision, complexity) the most. Furthermore, we offer novel insights about how the value of event log characteristics correlates with their contributed impact, assessing the algorithm's robustness.
DiffusAL: Coupling Active Learning with Graph Diffusion for Label-Efficient Node Classification
Jul 31, 2023Node classification is one of the core tasks on attributed graphs, but successful graph learning solutions require sufficiently labeled data. To keep annotation costs low, active graph learning focuses on selecting the most qualitative subset of nodes that maximizes label efficiency. However, deciding which heuristic is best suited for an unlabeled graph to increase label efficiency is a persistent challenge. Existing solutions either neglect aligning the learned model and the sampling method or focus only on limited selection aspects. They are thus sometimes worse or only equally good as random sampling. In this work, we introduce a novel active graph learning approach called DiffusAL, showing significant robustness in diverse settings. Toward better transferability between different graph structures, we combine three independent scoring functions to identify the most informative node samples for labeling in a parameter-free way: i) Model Uncertainty, ii) Diversity Component, and iii) Node Importance computed via graph diffusion heuristics. Most of our calculations for acquisition and training can be pre-processed, making DiffusAL more efficient compared to approaches combining diverse selection criteria and similarly fast as simpler heuristics. Our experiments on various benchmark datasets show that, unlike previous methods, our approach significantly outperforms random selection in 100% of all datasets and labeling budgets tested.
V-Coder: Adaptive AutoEncoder for Semantic Disclosure in Knowledge Graphs
Jul 22, 2022

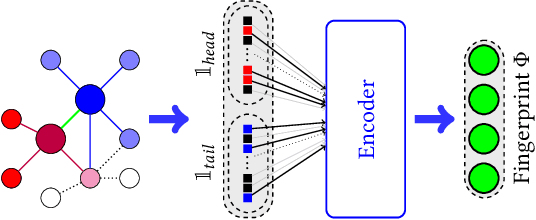
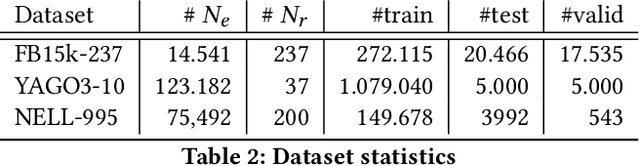
Semantic Web or Knowledge Graphs (KG) emerged to one of the most important information source for intelligent systems requiring access to structured knowledge. One of the major challenges is the extraction and processing of unambiguous information from textual data. Following the human perception, overlapping semantic linkages between two named entities become clear due to our common-sense about the context a relationship lives in which is not the case when we look at it from an automatically driven process of a machine. In this work, we are interested in the problem of Relational Resolution within the scope of KGs, i.e, we are investigating the inherent semantic of relationships between entities within a network. We propose a new adaptive AutoEncoder, called V-Coder, to identify relations inherently connecting entities from different domains. Those relations can be considered as being ambiguous and are candidates for disentanglement. Likewise to the Adaptive Learning Theory (ART), our model learns new patterns from the KG by increasing units in a competitive layer without discarding the previous observed patterns whilst learning the quality of each relation separately. The evaluation on real-world datasets of Freebase, Yago and NELL shows that the V-Coder is not only able to recover links from corrupted input data, but also shows that the semantic disclosure of relations in a KG show the tendency to improve link prediction. A semantic evaluation wraps the evaluation up.
MIRA: Multihop Relation Prediction in Temporal Knowledge Graphs
Oct 27, 2021
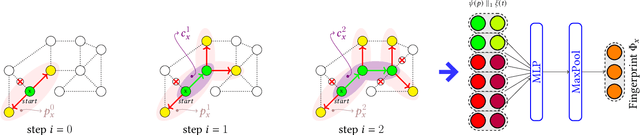
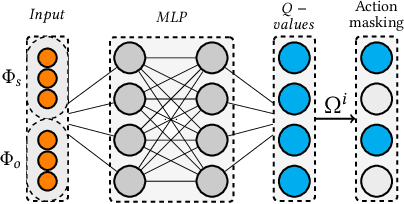
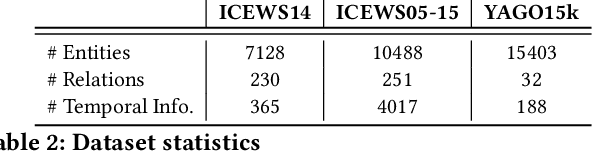
In knowledge graph reasoning, we observe a trend to analyze temporal data evolving over time. The additional temporal dimension is attached to facts in a knowledge base resulting in quadruples between entities such as (Nintendo, released, Super Mario, Sep-13-1985), where the relation between two entities is associated to a specific time interval or point in time. Multi-hop reasoning on inferred subgraphs connecting entities within a knowledge graph can be formulated as a reinforcement learning task where the agent sequentially performs inference upon the explored subgraph. The task in this work is to infer the predicate between a subject and an object entity, i.e., (subject, ?, object, time), being valid at a certain timestamp or time interval. Given query entities, our agent starts to gather temporal relevant information about the neighborhood of the subject and object. The encoding of information about the explored graph structures is referred to as fingerprints. Subsequently, we use the two fingerprints as input to a Q-Network. Our agent decides sequentially which relational type needs to be explored next expanding the local subgraphs of the query entities in order to find promising paths between them. The evaluation shows that the proposed method not only yields results being in line with state-of-the-art embedding algorithms for temporal Knowledge Graphs (tKG), but we also gain information about the relevant structures between subjects and objects.
SEA: Graph Shell Attention in Graph Neural Networks
Oct 20, 2021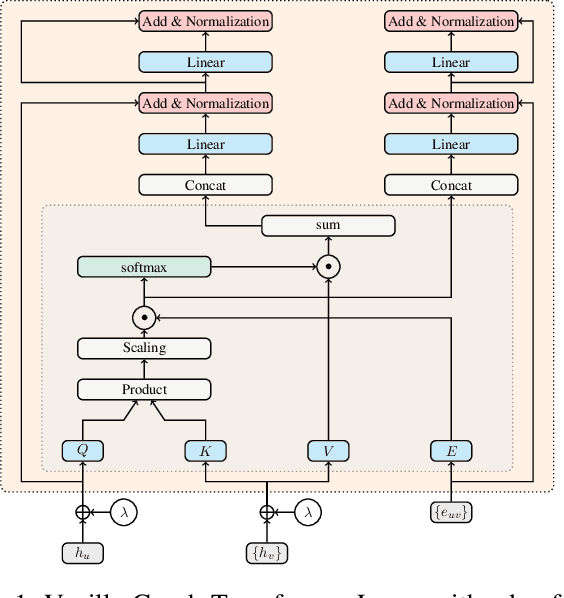


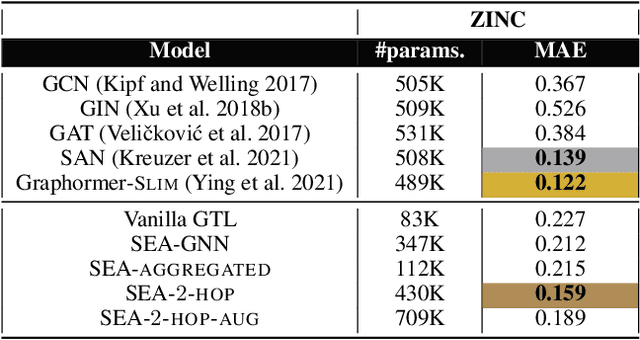
A common issue in Graph Neural Networks (GNNs) is known as over-smoothing. By increasing the number of iterations within the message-passing of GNNs, the nodes' representations of the input graph align with each other and become indiscernible. Recently, it has been shown that increasing a model's complexity by integrating an attention mechanism yields more expressive architectures. This is majorly contributed to steering the nodes' representations only towards nodes that are more informative than others. Transformer models in combination with GNNs result in architectures including Graph Transformer Layers (GTL), where layers are entirely based on the attention operation. However, the calculation of a node's representation is still restricted to the computational working flow of a GNN. In our work, we relax the GNN architecture by means of implementing a routing heuristic. Specifically, the nodes' representations are routed to dedicated experts. Each expert calculates the representations according to their respective GNN workflow. The definitions of distinguishable GNNs result from k-localized views starting from the central node. We call this procedure Graph Shell Attention (SEA), where experts process different subgraphs in a transformer-motivated fashion. Intuitively, by increasing the number of experts, the models gain in expressiveness such that a node's representation is solely based on nodes that are located within the receptive field of an expert. We evaluate our architecture on various benchmark datasets showing competitive results compared to state-of-the-art models.