 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEA: Graph Shell Attention in Graph Neural Networks
Paper and Code
Oct 20, 2021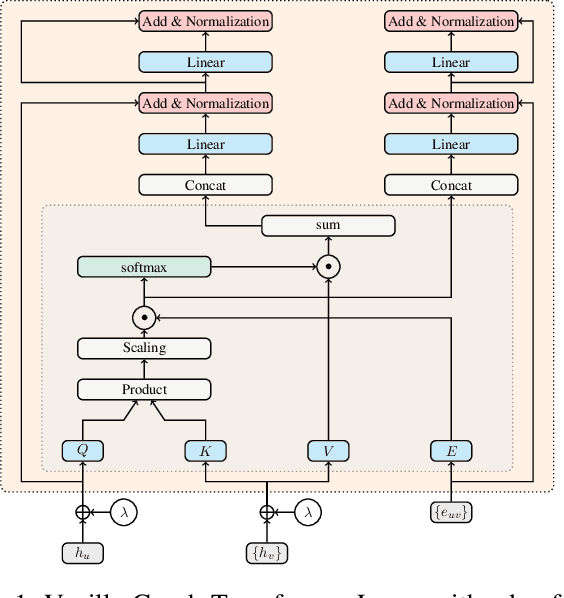


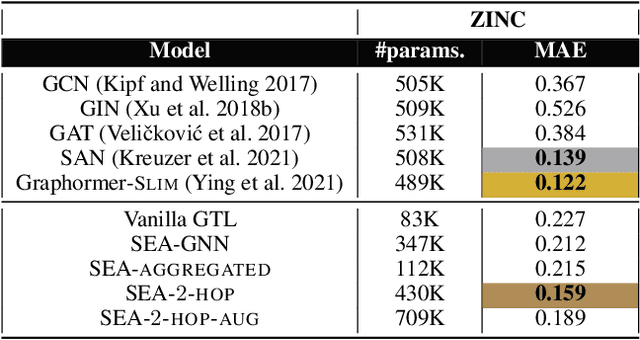
A common issue in Graph Neural Networks (GNNs) is known as over-smoothing. By increasing the number of iterations within the message-passing of GNNs, the nodes' representations of the input graph align with each other and become indiscernible. Recently, it has been shown that increasing a model's complexity by integrating an attention mechanism yields more expressive architectures. This is majorly contributed to steering the nodes' representations only towards nodes that are more informative than others. Transformer models in combination with GNNs result in architectures including Graph Transformer Layers (GTL), where layers are entirely based on the attention operation. However, the calculation of a node's representation is still restricted to the computational working flow of a GNN. In our work, we relax the GNN architecture by means of implementing a routing heuristic. Specifically, the nodes' representations are routed to dedicated experts. Each expert calculates the representations according to their respective GNN workflow. The definitions of distinguishable GNNs result from k-localized views starting from the central node. We call this procedure Graph Shell Attention (SEA), where experts process different subgraphs in a transformer-motivated fashion. Intuitively, by increasing the number of experts, the models gain in expressiveness such that a node's representation is solely based on nodes that are located within the receptive field of an expert. We evaluate our architecture on various benchmark datasets showing competitive results compared to state-of-the-art models.