 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMIA: a Powerful and Efficient Alternative to Membership Inference Attacks against Synthetic Data Generators
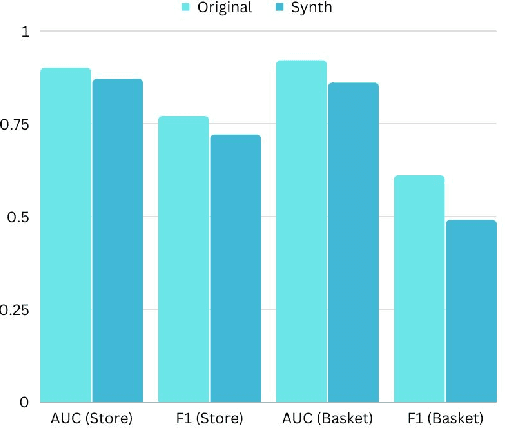
May 14, 2026Tabular data sharing under privacy constraints is increasingly important for research and collaboration. Synthetic data generators (SDGs) are a promising solution, but synthetic data remains vulnerable to attacks, such as membership inference attacks (MIAs), which aim to determine whether a specific record was part of the training data. State-of-the-art MIAs are powerful but impractical: they rely on shadow modeling, requiring hundreds of SDG training runs, and need auxiliary data several times larger than the original training set. Fast proxy metrics like distance to closest record (DCR) are efficient but have limited sensitivity to MIA risk. We introduce ReMIA (Relative Membership Inference Attack), a practical privacy metric that requires only two SDG training runs and additional data no larger than the original training set. Rather than predicting whether a record was in the training set, ReMIA generates two synthetic datasets from two source datasets and measures whether a classifier can identify which source a record came from. Experiments across multiple tabular datasets and SDGs show that ReMIA has a sensitivity comparable to state-of-the-art MIAs while being substantially more practical. We further observe that SDGs can achieve privacy-utility trade-offs that traditional noise-based anonymization methods do not match. Code is available at https://github.com/aindo-com/remia.
A Sobering Look at Tabular Data Generation via Probabilistic Circuits
Mar 24, 2026Tabular data is more challenging to generate than text and images, due to its heterogeneous features and much lower sample sizes. On this task, diffusion-based models are the current state-of-the-art (SotA) model class, achieving almost perfect performance on commonly used benchmarks. In this paper, we question the perception of progress for tabular data generation. First, we highlight the limitations of current protocols to evaluate the fidelity of generated data, and advocate for alternative ones. Next, we revisit a simple baseline -- hierarchical mixture models in the form of deep probabilistic circuits (PCs) -- which delivers competitive or superior performance to SotA models for a fraction of the cost. PCs are the generative counterpart of decision forests, and as such can natively handle heterogeneous data as well as deliver tractable probabilistic generation and inference. Finally, in a rigorous empirical analysis we show that the apparent saturation of progress for SotA models is largely due to the use of inadequate metrics. As such, we highlight that there is still much to be done to generate realistic tabular data. Code available at https://github.com/april-tools/tabpc.
Graph Conditional Flow Matching for Relational Data Generation
May 21, 2025Data synthesis is gaining momentum as a privacy-enhancing technology. While single-table tabular data generation has seen considerable progress, current methods for multi-table data often lack the flexibility and expressiveness needed to capture complex relational structures. In particular, they struggle with long-range dependencies and complex foreign-key relationships, such as tables with multiple parent tables or multiple types of links between the same pair of tables. We propose a generative model for relational data that generates the content of a relational dataset given the graph formed by the foreign-key relationships. We do this by learning a deep generative model of the content of the whole relational database by flow matching, where the neural network trained to denoise records leverages a graph neural network to obtain information from connected records. Our method is flexible, as it can support relational datasets with complex structures, and expressive, as the generation of each record can be influenced by any other record within the same connected component. We evaluate our method on several benchmark datasets and show that it achieves state-of-the-art performance in terms of synthetic data fidelity.
Contrastive Learning-Based privacy metrics in Tabular Synthetic Datasets
Feb 19, 2025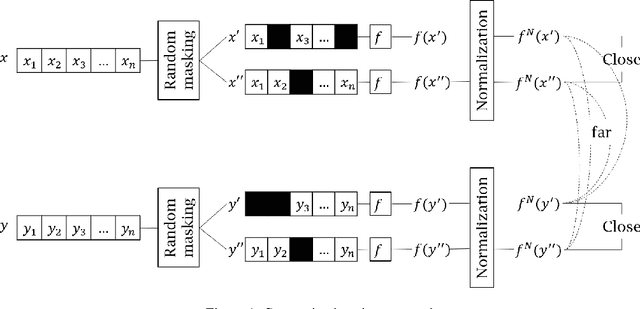
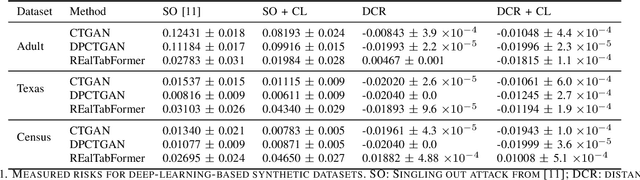
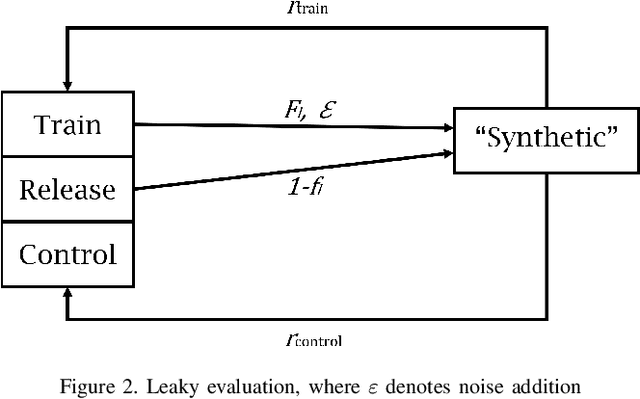
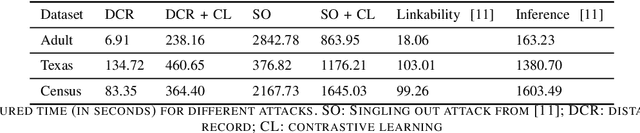
Synthetic data has garnered attention as a Privacy Enhancing Technology (PET) in sectors such as healthcare and finance. When using synthetic data in practical applications, it is important to provide protection guarantees. In the literature, two family of approaches are proposed for tabular data: on the one hand, Similarity-based methods aim at finding the level of similarity between training and synthetic data. Indeed, a privacy breach can occur if the generated data is consistently too similar or even identical to the train data. On the other hand, Attack-based methods conduce deliberate attacks on synthetic datasets. The success rates of these attacks reveal how secure the synthetic datasets are. In this paper, we introduce a contrastive method that improves privacy assessment of synthetic datasets by embedding the data in a more representative space. This overcomes obstacles surrounding the multitude of data types and attributes. It also makes the use of intuitive distance metrics possible for similarity measurements and as an attack vector. In a series of experiments with publicly available datasets, we compare the performances of similarity-based and attack-based methods, both with and without use of the contrastive learning-based embeddings. Our results show that relatively efficient, easy to implement privacy metrics can perform equally well as more advanced metrics explicitly modeling conditions for privacy referred to by the GDPR.
Conditioning Score-Based Generative Models by Neuro-Symbolic Constraints
Aug 31, 2023
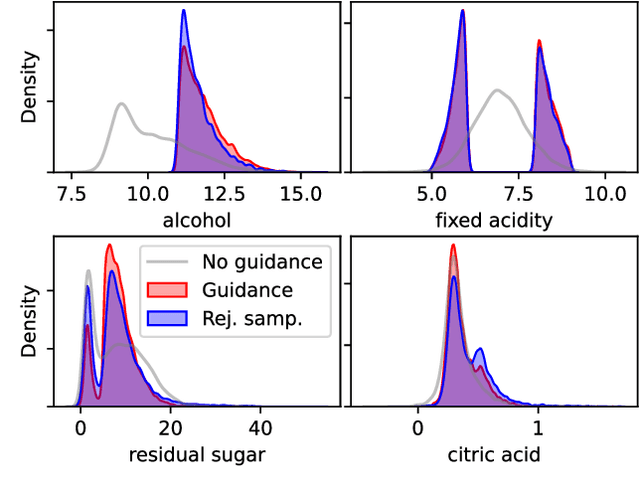
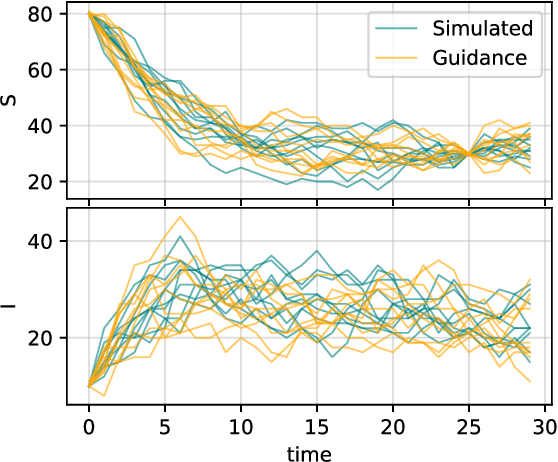

Score-based and diffusion models have emerged as effective approaches for both conditional and unconditional generation. Still conditional generation is based on either a specific training of a conditional model or classifier guidance, which requires training a noise-dependent classifier, even when the classifier for uncorrupted data is given. We propose an approach to sample from unconditional score-based generative models enforcing arbitrary logical constraints, without any additional training. Firstly, we show how to manipulate the learned score in order to sample from an un-normalized distribution conditional on a user-defined constraint. Then, we define a flexible and numerically stable neuro-symbolic framework for encoding soft logical constraints. Combining these two ingredients we obtain a general, but approximate, conditional sampling algorithm. We further developed effective heuristics aimed at improving the approximation. Finally, we show the effectiveness of our approach for various types of constraints and data: tabular data, images and time series.
Generating Realistic Synthetic Relational Data through Graph Variational Autoencoders
Nov 30, 2022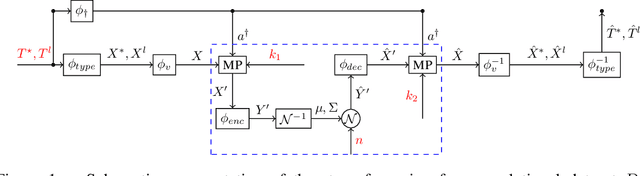
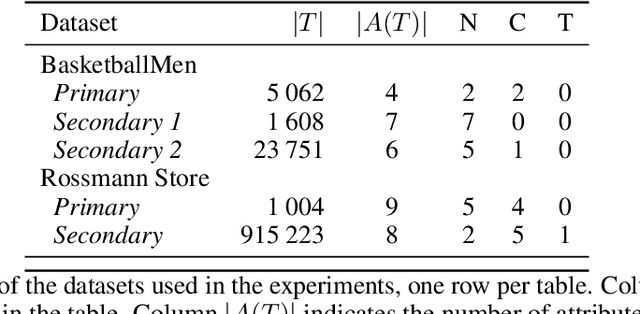

Synthetic data generation has recently gained widespread attention as a more reliable alternative to traditional data anonymization. The involved methods are originally developed for image synthesis. Hence, their application to the typically tabular and relational datasets from healthcare, finance and other industries is non-trivial. While substantial research has been devoted to the generation of realistic tabular datasets, the study of synthetic relational databases is still in its infancy. In this paper, we combine the variational autoencoder framework with graph neural networks to generate realistic synthetic relational databases. We then apply the obtained method to two publicly available databases in computational experiments. The results indicate that real databases' structures are accurately preserved in the resulting synthetic datasets, even for large datasets with advanced data types.