 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning-Based privacy metrics in Tabular Synthetic Datasets
Feb 19, 2025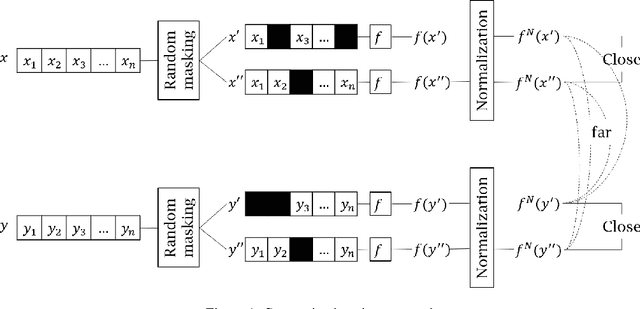
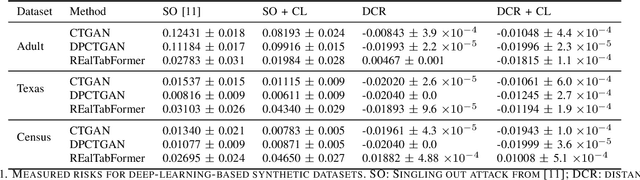
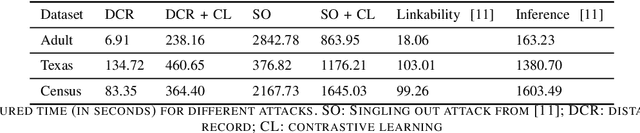
Synthetic data has garnered attention as a Privacy Enhancing Technology (PET) in sectors such as healthcare and finance. When using synthetic data in practical applications, it is important to provide protection guarantees. In the literature, two family of approaches are proposed for tabular data: on the one hand, Similarity-based methods aim at finding the level of similarity between training and synthetic data. Indeed, a privacy breach can occur if the generated data is consistently too similar or even identical to the train data. On the other hand, Attack-based methods conduce deliberate attacks on synthetic datasets. The success rates of these attacks reveal how secure the synthetic datasets are. In this paper, we introduce a contrastive method that improves privacy assessment of synthetic datasets by embedding the data in a more representative space. This overcomes obstacles surrounding the multitude of data types and attributes. It also makes the use of intuitive distance metrics possible for similarity measurements and as an attack vector. In a series of experiments with publicly available datasets, we compare the performances of similarity-based and attack-based methods, both with and without use of the contrastive learning-based embeddings. Our results show that relatively efficient, easy to implement privacy metrics can perform equally well as more advanced metrics explicitly modeling conditions for privacy referred to by the GDPR.
Generating Realistic Synthetic Relational Data through Graph Variational Autoencoders
Nov 30, 2022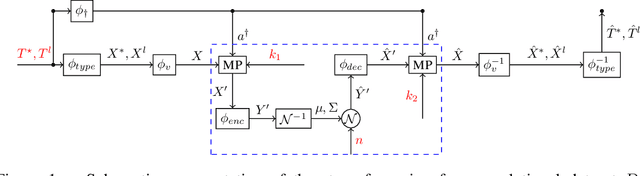
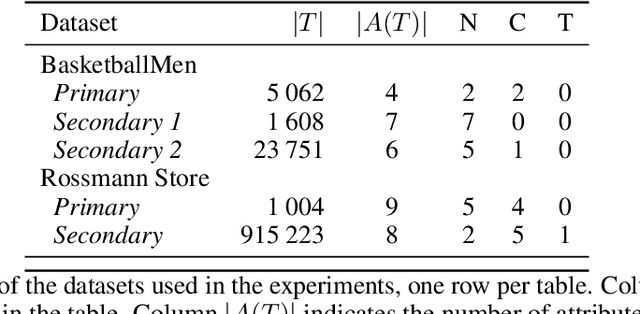

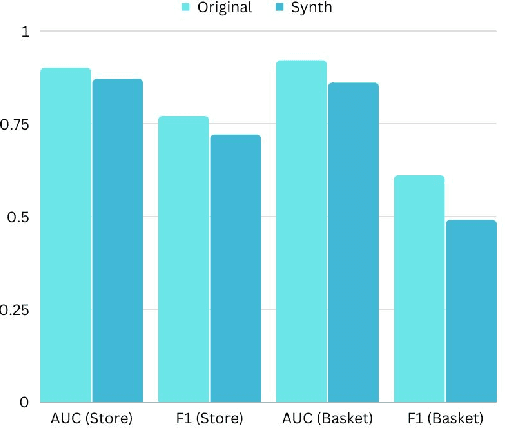
Synthetic data generation has recently gained widespread attention as a more reliable alternative to traditional data anonymization. The involved methods are originally developed for image synthesis. Hence, their application to the typically tabular and relational datasets from healthcare, finance and other industries is non-trivial. While substantial research has been devoted to the generation of realistic tabular datasets, the study of synthetic relational databases is still in its infancy. In this paper, we combine the variational autoencoder framework with graph neural networks to generate realistic synthetic relational databases. We then apply the obtained method to two publicly available databases in computational experiments. The results indicate that real databases' structures are accurately preserved in the resulting synthetic datasets, even for large datasets with advanced data types.