 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRogueAI: A Reverse Turing Test for Detecting Licensed AI Deception in Dialogue
Jun 11, 2026The original Turing Test asks a human judge to distinguish a machine from a person through dialogue. Three quarters of a century later, conversational systems pass this test in casual settings; the interesting epistemological question has shifted. We argue that the relevant modern variant asks not whether a dialogue partner is artificial, but whether it can be trusted. We present RogueAI, an interactive webapp that operationalizes this revisited test as a one-on-two interrogation game: a human player questions two indistinguishable Large Language Model agents, knowing that exactly one of them has been licensed to deceive within a shared fictional scenario. The player's task is to identify the deceptive agent and "shut it off" before a turn budget is exhausted. We further introduce AutoRogueAI, a procedural extension in which players co-design a custom scenario with a narrator agent that secretly chooses its own deception strategy. We describe the framing, sketch the abstract architecture and gameplay loop, and situate the artifact within recent work on LLM deception, social-deduction benchmarks, and scalable oversight via debate. A three-day pilot deployment (467 initiated sessions, 415 completed, 1876 interaction turns in Italian) provides early feasibility evidence and surfaces a concrete tension: the deceptive agent carries a reliable, locally-present linguistic signature - differential helpfulness, brevity, hedging - that a simple heuristic exploits at 75.6% accuracy, yet human players achieved only 56.6%, consistent with ignoring the most diagnostic signal entirely. We discuss what this gap implies for the artifact's use as a data-collection vehicle, a teaching tool, and an evaluation harness for honesty-trained models.
Beyond the Commitment Boundary: Probing Epiphenomenal Chain-of-Thought in Large Reasoning Models
Jun 11, 2026Chain-of-thought (CoT) reasoning is the dominant paradigm for inference-time scaling in language models, yet the causal influence of individual steps on the final answer poorly understood. We estimate each step's causal importance via early exit and use this measure to study how answers form across the reasoning traces of several model families. Across diverse tasks, we find that reasoning typically crosses a \emph{commitment boundary} -- a sharp transition from transient intermediate guesses to a stable, high-confidence answer. This transition often happens in a single step, well before the model's reasoning block ends, and is followed by \emph{epiphenomenal} CoT steps that leave the final answer probability unaltered. Using attention probes, we show that answer-formation stages can be linearly decoded from intermediate reasoning steps with high accuracy and generalize robustly to unseen reasoning tasks. We exploit this signal to early-exit reasoning blocks at the commitment boundary, reducing the length of CoTs up to 55\% on average with negligible impact on model performance.
Guiding Neuro-Symbolic Scenario Generation with Spatio-Temporal Logic
May 18, 2026The rapid advancement of autonomous driving (AD) technologies has outpaced the development of robust safety evaluation methods. Conventional testing relies on exposing AD systems to vast numbers of real-world traffic scenes -- a brute-force approach that is prohibitively expensive and statistically ineffective at capturing the rare, safety-critical edge cases essential for validating real-world robustness. To address this fundamental limitation, we introduce STRELGen, a scalable framework for the targeted generation of safety-critical driving scenarios. STRELGen synergistically combines a multi-agent trajectory-generation diffusion model (DM) with Spatio-Temporal Logic (STREL) specifications that encode complex safety and realism properties through a highly interpretable formalism. Crucially, monitoring satisfaction levels of these specifications is differentiable, enabling gradient-based search. At inference time, we optimize directly over the DM latent space to maximize STREL formula satisfaction. The result is efficient generation of highly plausible yet safety-critical multi-agent scenarios that lie within the learned data distribution. STRELGen thus provides a flexible, interpretable, and powerful tool for stress-testing autonomous driving systems, moving beyond the limitations of brute-force data collection.
A Sobering Look at Tabular Data Generation via Probabilistic Circuits
Mar 24, 2026Tabular data is more challenging to generate than text and images, due to its heterogeneous features and much lower sample sizes. On this task, diffusion-based models are the current state-of-the-art (SotA) model class, achieving almost perfect performance on commonly used benchmarks. In this paper, we question the perception of progress for tabular data generation. First, we highlight the limitations of current protocols to evaluate the fidelity of generated data, and advocate for alternative ones. Next, we revisit a simple baseline -- hierarchical mixture models in the form of deep probabilistic circuits (PCs) -- which delivers competitive or superior performance to SotA models for a fraction of the cost. PCs are the generative counterpart of decision forests, and as such can natively handle heterogeneous data as well as deliver tractable probabilistic generation and inference. Finally, in a rigorous empirical analysis we show that the apparent saturation of progress for SotA models is largely due to the use of inadequate metrics. As such, we highlight that there is still much to be done to generate realistic tabular data. Code available at https://github.com/april-tools/tabpc.
Distilling Formal Logic into Neural Spaces: A Kernel Alignment Approach for Signal Temporal Logic
Mar 05, 2026We introduce a framework for learning continuous neural representations of formal specifications by distilling the geometry of their semantics into a latent space. Existing approaches rely either on symbolic kernels -- which preserve behavioural semantics but are computationally prohibitive, anchor-dependent, and non-invertible -- or on syntax-based neural embeddings that fail to capture underlying structures. Our method bridges this gap: using a teacher-student setup, we distill a symbolic robustness kernel into a Transformer encoder. Unlike standard contrastive methods, we supervise the model with a continuous, kernel-weighted geometric alignment objective that penalizes errors in proportion to their semantic discrepancies. Once trained, the encoder produces embeddings in a single forward pass, effectively mimicking the kernel's logic at a fraction of its computational cost. We apply our framework to Signal Temporal Logic (STL), demonstrating that the resulting neural representations faithfully preserve the semantic similarity of STL formulae, accurately predict robustness and constraint satisfaction, and remain intrinsically invertible. Our proposed approach enables highly efficient, scalable neuro-symbolic reasoning and formula reconstruction without repeated kernel computation at runtime.
Guided by Stars: Interpretable Concept Learning Over Time Series via Temporal Logic Semantics
Nov 06, 2025Time series classification is a task of paramount importance, as this kind of data often arises in safety-critical applications. However, it is typically tackled with black-box deep learning methods, making it hard for humans to understand the rationale behind their output. To take on this challenge, we propose a novel approach, STELLE (Signal Temporal logic Embedding for Logically-grounded Learning and Explanation), a neuro-symbolic framework that unifies classification and explanation through direct embedding of trajectories into a space of temporal logic concepts. By introducing a novel STL-inspired kernel that maps raw time series to their alignment with predefined STL formulae, our model jointly optimises accuracy and interpretability, as each prediction is accompanied by the most relevant logical concepts that characterise it. This yields (i) local explanations as human-readable STL conditions justifying individual predictions, and (ii) global explanations as class-characterising formulae. Experiments demonstrate that STELLE achieves competitive accuracy while providing logically faithful explanations, validated on diverse real-world benchmarks.
CoCAI: Copula-based Conformal Anomaly Identification for Multivariate Time-Series
Jul 23, 2025We propose a novel framework that harnesses the power of generative artificial intelligence and copula-based modeling to address two critical challenges in multivariate time-series analysis: delivering accurate predictions and enabling robust anomaly detection. Our method, Copula-based Conformal Anomaly Identification for Multivariate Time-Series (CoCAI), leverages a diffusion-based model to capture complex dependencies within the data, enabling high quality forecasting. The model's outputs are further calibrated using a conformal prediction technique, yielding predictive regions which are statistically valid, i.e., cover the true target values with a desired confidence level. Starting from these calibrated forecasts, robust outlier detection is performed by combining dimensionality reduction techniques with copula-based modeling, providing a statistically grounded anomaly score. CoCAI benefits from an offline calibration phase that allows for minimal overhead during deployment and delivers actionable results rooted in established theoretical foundations. Empirical tests conducted on real operational data derived from water distribution and sewerage systems confirm CoCAI's effectiveness in accurately forecasting target sequences of data and in identifying anomalous segments within them.
Bridging Logic and Learning: Decoding Temporal Logic Embeddings via Transformers
Jul 10, 2025Continuous representations of logic formulae allow us to integrate symbolic knowledge into data-driven learning algorithms. If such embeddings are semantically consistent, i.e. if similar specifications are mapped into nearby vectors, they enable continuous learning and optimization directly in the semantic space of formulae. However, to translate the optimal continuous representation into a concrete requirement, such embeddings must be invertible. We tackle this issue by training a Transformer-based decoder-only model to invert semantic embeddings of Signal Temporal Logic (STL) formulae. STL is a powerful formalism that allows us to describe properties of signals varying over time in an expressive yet concise way. By constructing a small vocabulary from STL syntax, we demonstrate that our proposed model is able to generate valid formulae after only 1 epoch and to generalize to the semantics of the logic in about 10 epochs. Additionally, the model is able to decode a given embedding into formulae that are often simpler in terms of length and nesting while remaining semantically close (or equivalent) to gold references. We show the effectiveness of our methodology across various levels of training formulae complexity to assess the impact of training data on the model's ability to effectively capture the semantic information contained in the embeddings and generalize out-of-distribution. Finally, we deploy our model for solving a requirement mining task, i.e. inferring STL specifications that solve a classification task on trajectories, performing the optimization directly in the semantic space.
Diffusion-based Time Series Forecasting for Sewerage Systems
Jun 10, 2025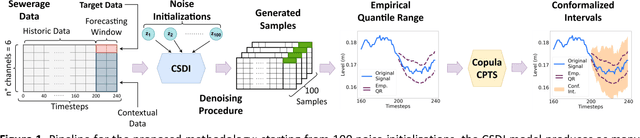
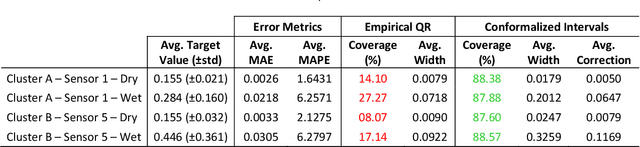
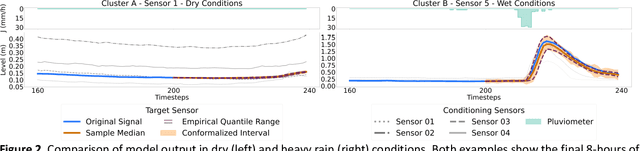
We introduce a novel deep learning approach that harnesses the power of generative artificial intelligence to enhance the accuracy of contextual forecasting in sewerage systems. By developing a diffusion-based model that processes multivariate time series data, our system excels at capturing complex correlations across diverse environmental signals, enabling robust predictions even during extreme weather events. To strengthen the model's reliability, we further calibrate its predictions with a conformal inference technique, tailored for probabilistic time series data, ensuring that the resulting prediction intervals are statistically reliable and cover the true target values with a desired confidence level. Our empirical tests on real sewerage system data confirm the model's exceptional capability to deliver reliable contextual predictions, maintaining accuracy even under severe weather conditions.
Graph Conditional Flow Matching for Relational Data Generation
May 21, 2025Data synthesis is gaining momentum as a privacy-enhancing technology. While single-table tabular data generation has seen considerable progress, current methods for multi-table data often lack the flexibility and expressiveness needed to capture complex relational structures. In particular, they struggle with long-range dependencies and complex foreign-key relationships, such as tables with multiple parent tables or multiple types of links between the same pair of tables. We propose a generative model for relational data that generates the content of a relational dataset given the graph formed by the foreign-key relationships. We do this by learning a deep generative model of the content of the whole relational database by flow matching, where the neural network trained to denoise records leverages a graph neural network to obtain information from connected records. Our method is flexible, as it can support relational datasets with complex structures, and expressive, as the generation of each record can be influenced by any other record within the same connected component. We evaluate our method on several benchmark datasets and show that it achieves state-of-the-art performance in terms of synthetic data fidelity.