 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioning Score-Based Generative Models by Neuro-Symbolic Constraints
Aug 31, 2023
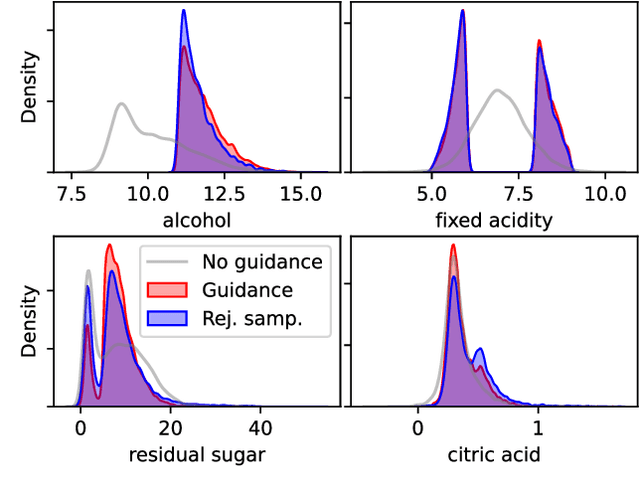
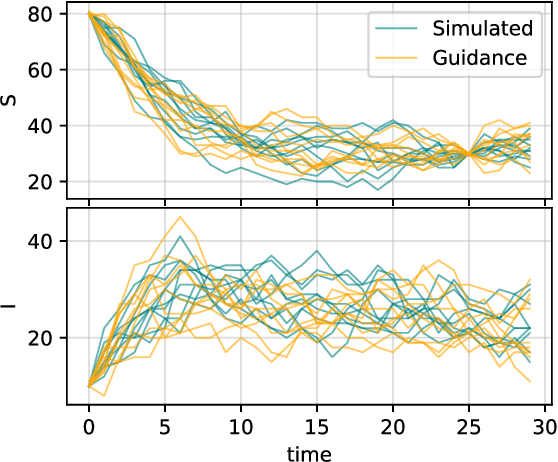

Score-based and diffusion models have emerged as effective approaches for both conditional and unconditional generation. Still conditional generation is based on either a specific training of a conditional model or classifier guidance, which requires training a noise-dependent classifier, even when the classifier for uncorrupted data is given. We propose an approach to sample from unconditional score-based generative models enforcing arbitrary logical constraints, without any additional training. Firstly, we show how to manipulate the learned score in order to sample from an un-normalized distribution conditional on a user-defined constraint. Then, we define a flexible and numerically stable neuro-symbolic framework for encoding soft logical constraints. Combining these two ingredients we obtain a general, but approximate, conditional sampling algorithm. We further developed effective heuristics aimed at improving the approximation. Finally, we show the effectiveness of our approach for various types of constraints and data: tabular data, images and time series.
On the Robustness of Bayesian Neural Networks to Adversarial Attacks
Jul 13, 2022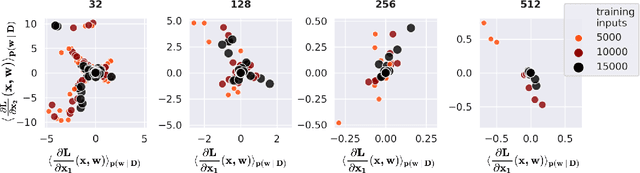
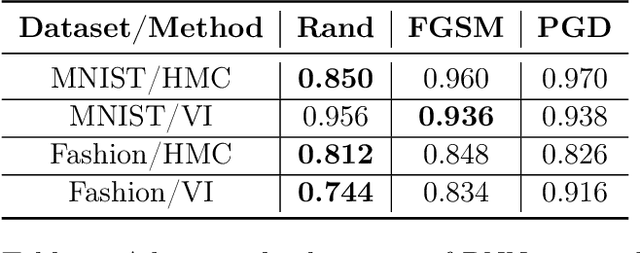
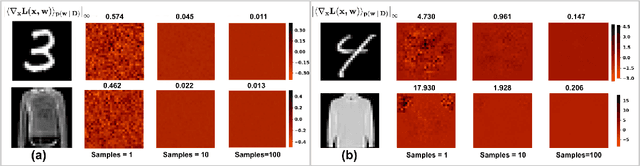
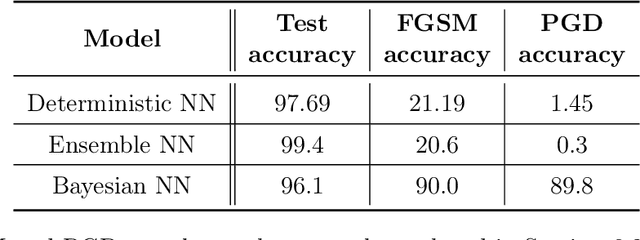
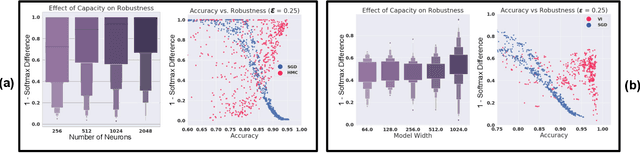
Vulnerability to adversarial attacks is one of the principal hurdles to the adoption of deep learning in safety-critical applications. Despite significant efforts, both practical and theoretical, training deep learning models robust to adversarial attacks is still an open problem. In this paper, we analyse the geometry of adversarial attacks in the large-data, overparameterized limit for Bayesian Neural Networks (BNNs). We show that, in the limit, vulnerability to gradient-based attacks arises as a result of degeneracy in the data distribution, i.e., when the data lies on a lower-dimensional submanifold of the ambient space. As a direct consequence, we demonstrate that in this limit BNN posteriors are robust to gradient-based adversarial attacks. Crucially, we prove that the expected gradient of the loss with respect to the BNN posterior distribution is vanishing, even when each neural network sampled from the posterior is vulnerable to gradient-based attacks. Experimental results on the MNIST, Fashion MNIST, and half moons datasets, representing the finite data regime, with BNNs trained with Hamiltonian Monte Carlo and Variational Inference, support this line of arguments, showing that BNNs can display both high accuracy on clean data and robustness to both gradient-based and gradient-free based adversarial attacks.
Stochastic Variational Smoothed Model Checking
May 11, 2022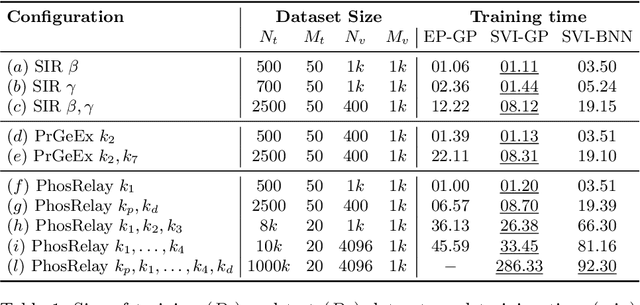

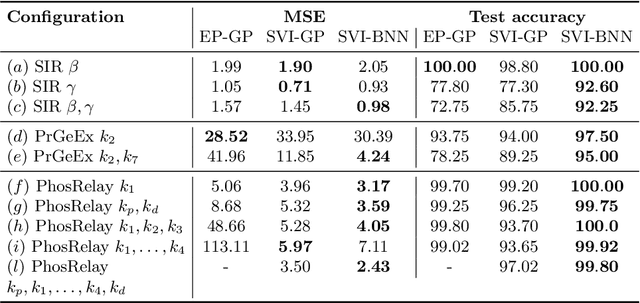

Model-checking for parametric stochastic models can be expressed as checking the satisfaction probability of a certain property as a function of the parameters of the model. Smoothed model checking (smMC) leverages Gaussian Processes (GP) to infer the satisfaction function over the entire parameter space from a limited set of observations obtained via simulation. This approach provides accurate reconstructions with statistically sound quantification of the uncertainty. However, it inherits the scalability issues of GP. In this paper, we exploit recent advances in probabilistic machine learning to push this limitation forward, making Bayesian inference of smMC scalable to larger datasets, enabling its application to larger models in terms of the dimension of the parameter set. We propose Stochastic Variational Smoothed Model Checking (SV-smMC), a solution that exploits stochastic variational inference (SVI) to approximate the posterior distribution of the smMC problem. The strength and flexibility of SVI make SV-smMC applicable to two alternative probabilistic models: Gaussian Processes (GP) and Bayesian Neural Networks (BNN). Moreover, SVI makes inference easily parallelizable and it enables GPU acceleration. In this paper, we compare the performances of smMC against those of SV-smMC by looking at the scalability, the computational efficiency and at the accuracy of the reconstructed satisfaction function.
Abstraction of Markov Population Dynamics via Generative Adversarial Nets
Jun 24, 2021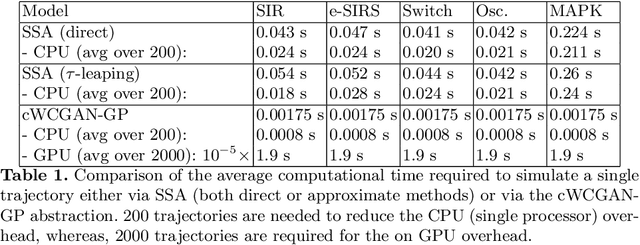
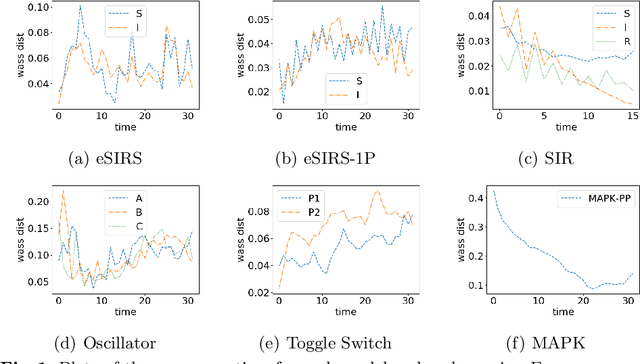
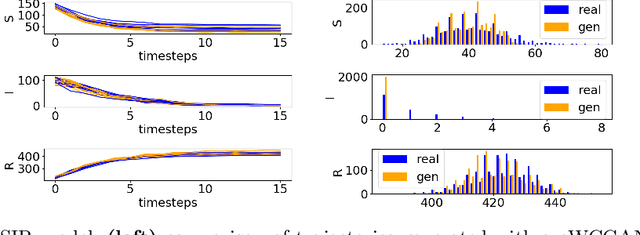
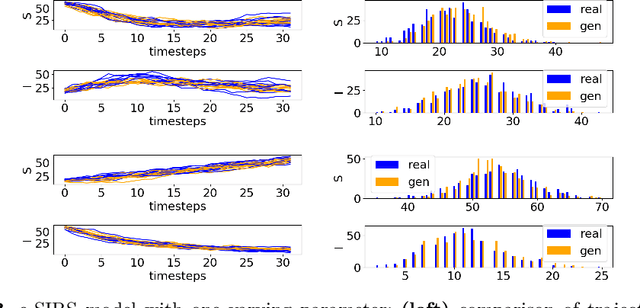
Markov Population Models are a widespread formalism used to model the dynamics of complex systems, with applications in Systems Biology and many other fields. The associated Markov stochastic process in continuous time is often analyzed by simulation, which can be costly for large or stiff systems, particularly when a massive number of simulations has to be performed (e.g. in a multi-scale model). A strategy to reduce computational load is to abstract the population model, replacing it with a simpler stochastic model, faster to simulate. Here we pursue this idea, building on previous works and constructing a generator capable of producing stochastic trajectories in continuous space and discrete time. This generator is learned automatically from simulations of the original model in a Generative Adversarial setting. Compared to previous works, which rely on deep neural networks and Dirichlet processes, we explore the use of state of the art generative models, which are flexible enough to learn a full trajectory rather than a single transition kernel.
Resilience of Bayesian Layer-Wise Explanations under Adversarial Attacks
Feb 22, 2021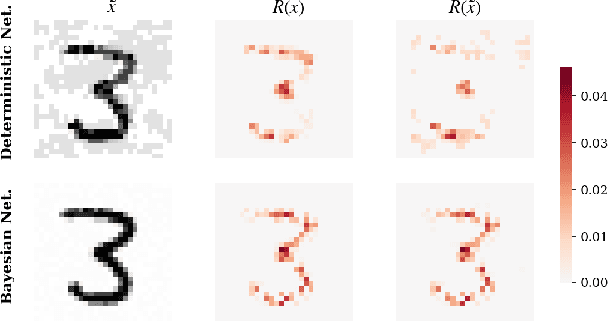
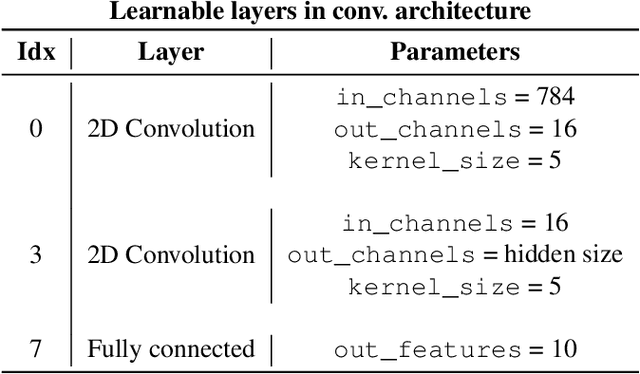

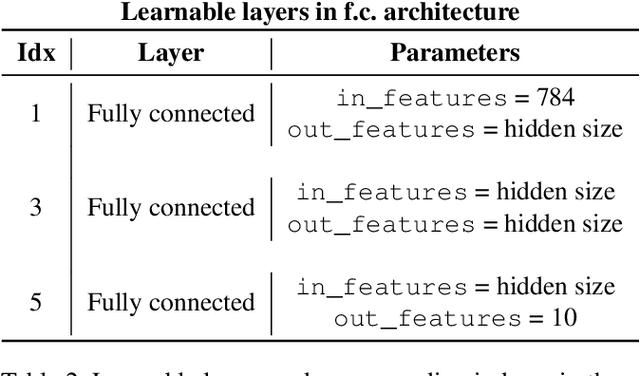
We consider the problem of the stability of saliency-based explanations of Neural Network predictions under adversarial attacks in a classification task. We empirically show that, for deterministic Neural Networks, saliency interpretations are remarkably brittle even when the attacks fail, i.e. for attacks that do not change the classification label. By leveraging recent results, we provide a theoretical explanation of this result in terms of the geometry of adversarial attacks. Based on these theoretical considerations, we suggest and demonstrate empirically that saliency explanations provided by Bayesian Neural Networks are considerably more stable under adversarial perturbations. Our results not only confirm that Bayesian Neural Networks are more robust to adversarial attacks, but also demonstrate that Bayesian methods have the potential to provide more stable and interpretable assessments of Neural Network predictions.
Random Projections for Improved Adversarial Robustness
Feb 18, 2021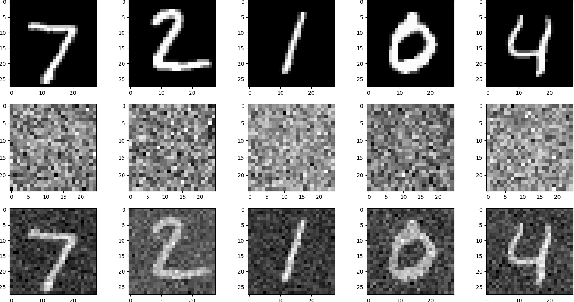
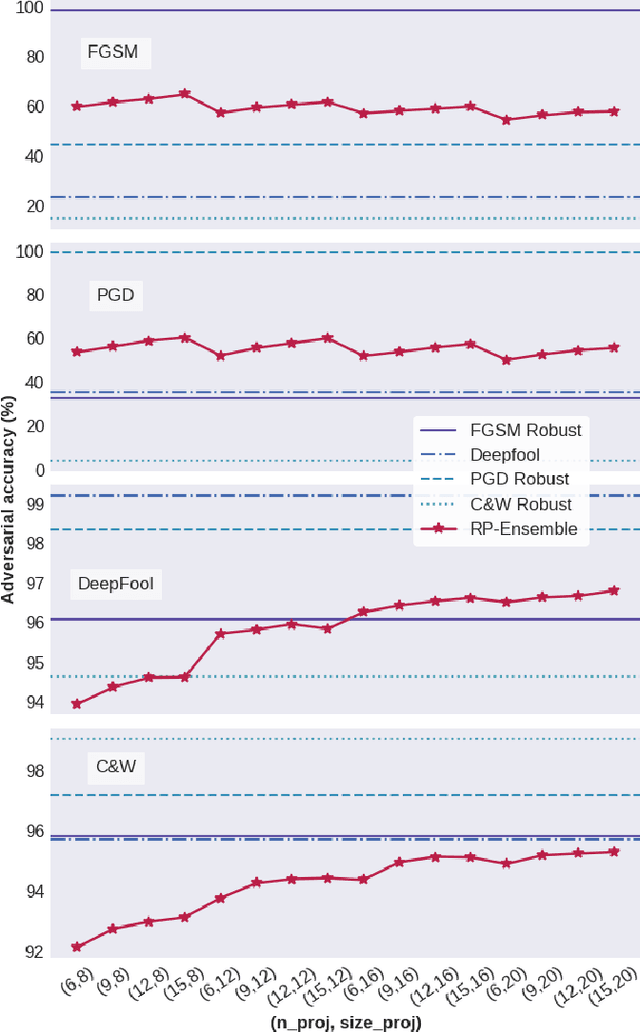
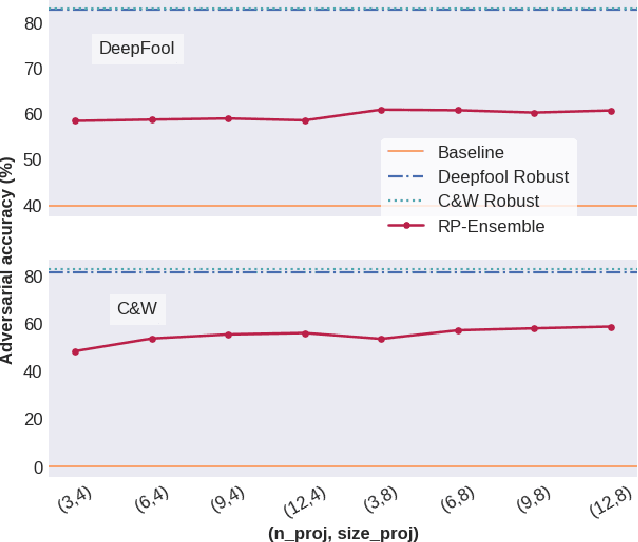

We propose two training techniques for improving the robustness of Neural Networks to adversarial attacks, i.e. manipulations of the inputs that are maliciously crafted to fool networks into incorrect predictions. Both methods are independent of the chosen attack and leverage random projections of the original inputs, with the purpose of exploiting both dimensionality reduction and some characteristic geometrical properties of adversarial perturbations. The first technique is called RP-Ensemble and consists of an ensemble of networks trained on multiple projected versions of the original inputs. The second one, named RP-Regularizer, adds instead a regularization term to the training objective.
ETC-NLG: End-to-end Topic-Conditioned Natural Language Generation
Aug 25, 2020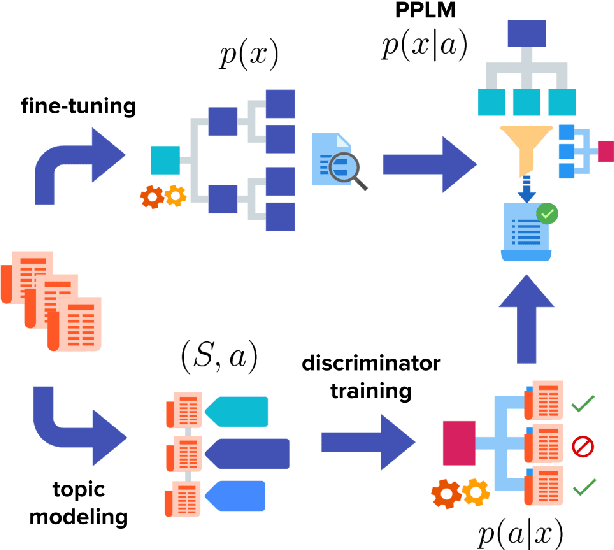

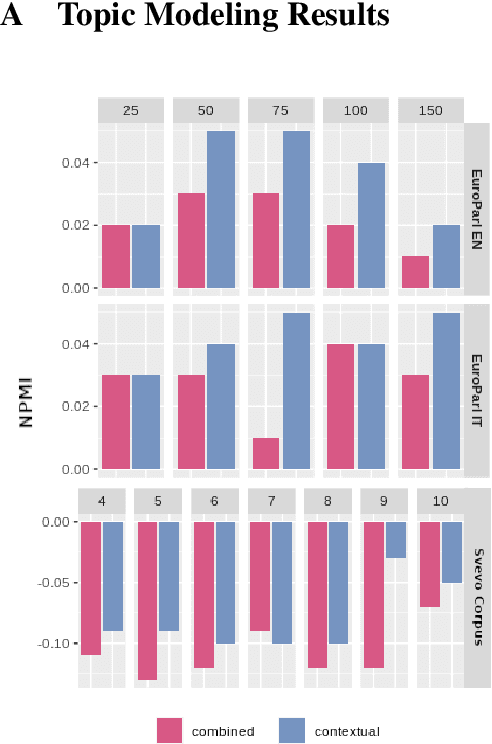
Plug-and-play language models (PPLMs) enable topic-conditioned natural language generation by pairing large pre-trained generators with attribute models used to steer the predicted token distribution towards the selected topic. Despite their computational efficiency, PPLMs require large amounts of labeled texts to effectively balance generation fluency and proper conditioning, making them unsuitable for low-resource settings. We present ETC-NLG, an approach leveraging topic modeling annotations to enable fully-unsupervised End-to-end Topic-Conditioned Natural Language Generation over emergent topics in unlabeled document collections. We first test the effectiveness of our approach in a low-resource setting for Italian, evaluating the conditioning for both topic models and gold annotations. We then perform a comparative evaluation of ETC-NLG for Italian and English using a parallel corpus. Finally, we propose an automatic approach to estimate the effectiveness of conditioning on the generated utterances.
Robustness of Bayesian Neural Networks to Gradient-Based Attacks
Feb 12, 2020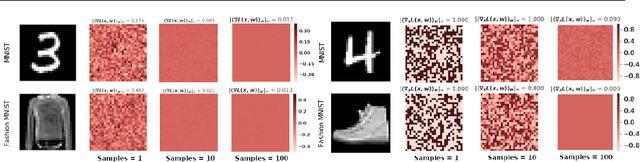
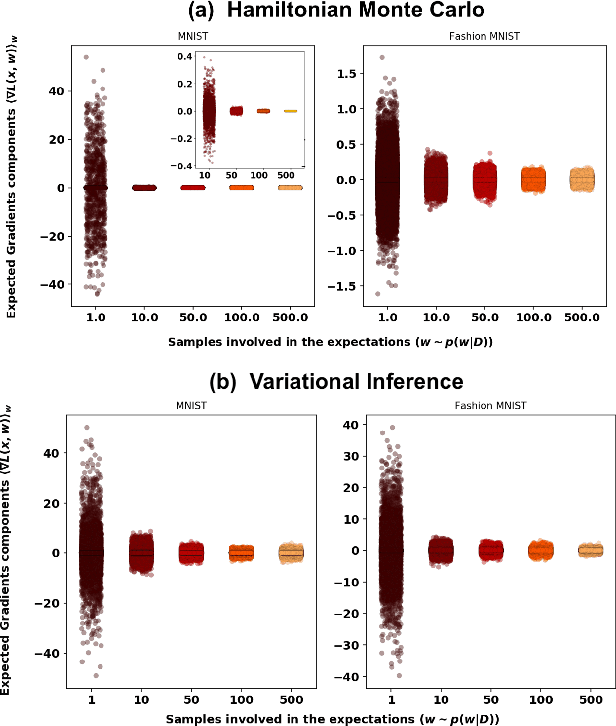
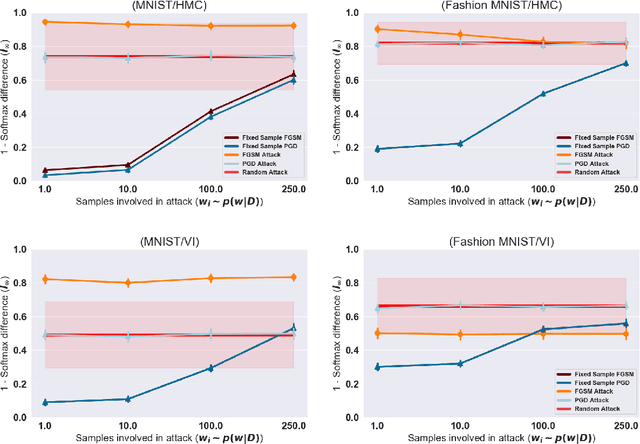
Vulnerability to adversarial attacks is one of the principal hurdles to the adoption of deep learning in safety-critical applications. Despite significant efforts, both practical and theoretical, the problem remains open. In this paper, we analyse the geometry of adversarial attacks in the large-data, overparametrized limit for Bayesian Neural Networks (BNNs). We show that, in the limit, vulnerability to gradient-based attacks arises as a result of degeneracy in the data distribution, i.e., when the data lies on a lower-dimensional submanifold of the ambient space. As a direct consequence, we demonstrate that in the limit BNN posteriors are robust to gradient-based adversarial attacks. Experimental results on the MNIST and Fashion MNIST datasets with BNNs trained with Hamiltonian Monte Carlo and Variational Inference support this line of argument, showing that BNNs can display both high accuracy and robustness to gradient based adversarial attacks.