 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Red Queen: Adversarial Program Evolution in Core War with LLMs
Jan 06, 2026Large language models (LLMs) are increasingly being used to evolve solutions to problems in many domains, in a process inspired by biological evolution. However, unlike biological evolution, most LLM-evolution frameworks are formulated as static optimization problems, overlooking the open-ended adversarial dynamics that characterize real-world evolutionary processes. Here, we study Digital Red Queen (DRQ), a simple self-play algorithm that embraces these so-called "Red Queen" dynamics via continual adaptation to a changing objective. DRQ uses an LLM to evolve assembly-like programs, called warriors, which compete against each other for control of a virtual machine in the game of Core War, a Turing-complete environment studied in artificial life and connected to cybersecurity. In each round of DRQ, the model evolves a new warrior to defeat all previous ones, producing a sequence of adapted warriors. Over many rounds, we observe that warriors become increasingly general (relative to a set of held-out human warriors). Interestingly, warriors also become less behaviorally diverse across independent runs, indicating a convergence pressure toward a general-purpose behavioral strategy, much like convergent evolution in nature. This result highlights a potential value of shifting from static objectives to dynamic Red Queen objectives. Our work positions Core War as a rich, controllable sandbox for studying adversarial adaptation in artificial systems and for evaluating LLM-based evolution methods. More broadly, the simplicity and effectiveness of DRQ suggest that similarly minimal self-play approaches could prove useful in other more practical multi-agent adversarial domains, like real-world cybersecurity or combating drug resistance.
Bridging Past and Future: Distribution-Aware Alignment for Time Series Forecasting
Sep 17, 2025Representation learning techniques like contrastive learning have long been explored in time series forecasting, mirroring their success in computer vision and natural language processing. Yet recent state-of-the-art (SOTA) forecasters seldom adopt these representation approaches because they have shown little performance advantage. We challenge this view and demonstrate that explicit representation alignment can supply critical information that bridges the distributional gap between input histories and future targets. To this end, we introduce TimeAlign, a lightweight, plug-and-play framework that learns auxiliary features via a simple reconstruction task and feeds them back to any base forecaster. Extensive experiments across eight benchmarks verify its superior performance. Further studies indicate that the gains arises primarily from correcting frequency mismatches between historical inputs and future outputs. We also provide a theoretical justification for the effectiveness of TimeAlign in increasing the mutual information between learned representations and predicted targets. As it is architecture-agnostic and incurs negligible overhead, TimeAlign can serve as a general alignment module for modern deep learning time-series forecasting systems. The code is available at https://github.com/TROUBADOUR000/TimeAlign.
Reinforcement Learning Teachers of Test Time Scaling
Jun 10, 2025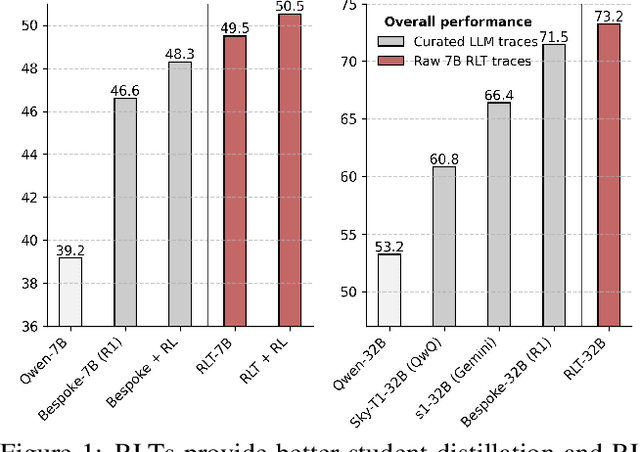
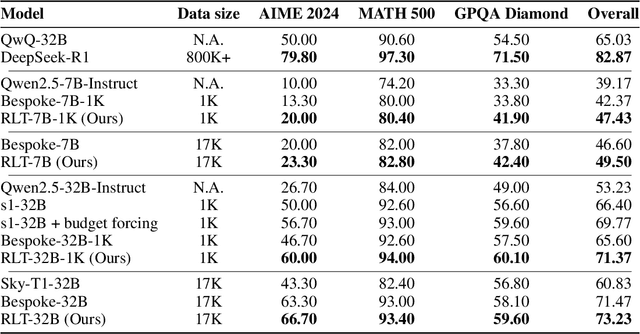

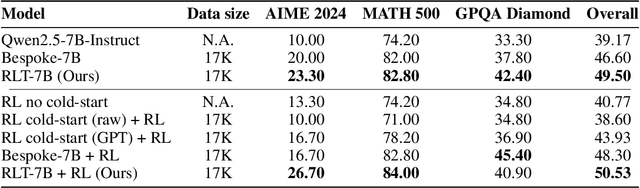
Training reasoning language models (LMs) with reinforcement learning (RL) for one-hot correctness inherently relies on the LM being able to explore and solve its task with some chance at initialization. Furthermore, a key use case of reasoning LMs is to act as teachers for distilling new students and cold-starting future RL iterations rather than being deployed themselves. From these considerations, we introduce a new framework that avoids RL's exploration challenge by training a new class of Reinforcement-Learned Teachers (RLTs) focused on yielding the most effective downstream distillation. RLTs are prompted with both the question and solution to each problem, and tasked to simply "connect-the-dots" with detailed explanations tailored for their students. We train RLTs with dense rewards obtained by feeding each explanation to the student and testing its understanding of the problem's solution. In practice, the raw outputs of a 7B RLT provide higher final performance on competition and graduate-level tasks than existing distillation and cold-starting pipelines that collect and postprocess the reasoning traces of orders of magnitude larger LMs. Furthermore, RLTs maintain their effectiveness when training larger students and when applied zero-shot to out-of-distribution tasks, unlocking new levels of efficiency and re-usability for the RL reasoning framework.
Text-to-LoRA: Instant Transformer Adaption
Jun 06, 2025While Foundation Models provide a general tool for rapid content creation, they regularly require task-specific adaptation. Traditionally, this exercise involves careful curation of datasets and repeated fine-tuning of the underlying model. Fine-tuning techniques enable practitioners to adapt foundation models for many new applications but require expensive and lengthy training while being notably sensitive to hyper-parameter choices. To overcome these limitations, we introduce Text-to-LoRA (T2L), a model capable of adapting Large Language Models on the fly solely based on a natural language description of the target task. T2L is a hypernetwork trained to construct LoRAs in a single inexpensive forward pass. After training T2L on a suite of 9 pre-trained LoRA adapters (GSM8K, Arc, etc.), we show that the ad-hoc reconstructed LoRA instances match the performance of task-specific adapters across the corresponding test sets. Furthermore, T2L can compress hundreds of LoRA instances and zero-shot generalize to entirely unseen tasks. This approach provides a significant step towards democratizing the specialization of foundation models and enables language-based adaptation with minimal compute requirements. Our code is available at https://github.com/SakanaAI/text-to-lora
Mamba-Adaptor: State Space Model Adaptor for Visual Recognition
May 19, 2025Recent State Space Models (SSM), especially Mamba, have demonstrated impressive performance in visual modeling and possess superior model efficiency. However, the application of Mamba to visual tasks suffers inferior performance due to three main constraints existing in the sequential model: 1) Casual computing is incapable of accessing global context; 2) Long-range forgetting when computing the current hidden states; 3) Weak spatial structural modeling due to the transformed sequential input. To address these issues, we investigate a simple yet powerful vision task Adaptor for Mamba models, which consists of two functional modules: Adaptor-T and Adaptor-S. When solving the hidden states for SSM, we apply a lightweight prediction module Adaptor-T to select a set of learnable locations as memory augmentations to ease long-range forgetting issues. Moreover, we leverage Adapator-S, composed of multi-scale dilated convolutional kernels, to enhance the spatial modeling and introduce the image inductive bias into the feature output. Both modules can enlarge the context modeling in casual computing, as the output is enhanced by the inaccessible features. We explore three usages of Mamba-Adaptor: A general visual backbone for various vision tasks; A booster module to raise the performance of pretrained backbones; A highly efficient fine-tuning module that adapts the base model for transfer learning tasks. Extensive experiments verify the effectiveness of Mamba-Adaptor in three settings. Notably, our Mamba-Adaptor achieves state-of the-art performance on the ImageNet and COCO benchmarks.
Two Heads are Better Than One: Test-time Scaling of Multi-agent Collaborative Reasoning
Apr 14, 2025Multi-agent systems (MAS) built on large language models (LLMs) offer a promising path toward solving complex, real-world tasks that single-agent systems often struggle to manage. While recent advancements in test-time scaling (TTS) have significantly improved single-agent performance on challenging reasoning tasks, how to effectively scale collaboration and reasoning in MAS remains an open question. In this work, we introduce an adaptive multi-agent framework designed to enhance collaborative reasoning through both model-level training and system-level coordination. We construct M500, a high-quality dataset containing 500 multi-agent collaborative reasoning traces, and fine-tune Qwen2.5-32B-Instruct on this dataset to produce M1-32B, a model optimized for multi-agent collaboration. To further enable adaptive reasoning, we propose a novel CEO agent that dynamically manages the discussion process, guiding agent collaboration and adjusting reasoning depth for more effective problem-solving. Evaluated in an open-source MAS across a range of tasks-including general understanding, mathematical reasoning, and coding-our system significantly outperforms strong baselines. For instance, M1-32B achieves 12% improvement on GPQA-Diamond, 41% on AIME2024, and 10% on MBPP-Sanitized, matching the performance of state-of-the-art models like DeepSeek-R1 on some tasks. These results highlight the importance of both learned collaboration and adaptive coordination in scaling multi-agent reasoning. Code is available at https://github.com/jincan333/MAS-TTS
Large Language Models to Diffusion Finetuning
Jan 27, 2025



We propose a new finetuning method to provide pre-trained large language models (LMs) the ability to scale test-time compute through the diffusion framework. By increasing the number of diffusion steps, we show our finetuned models achieve monotonically increasing accuracy, directly translating to improved performance across downstream tasks. Furthermore, our finetuned models can expertly answer questions on specific topics by integrating powerful guidance techniques, and autonomously determine the compute required for a given problem by leveraging adaptive ODE solvers. Our method is universally applicable to any foundation model pre-trained with a cross-entropy loss and does not modify any of its original weights, fully preserving its strong single-step generation capabilities. We show our method is more effective and fully compatible with traditional finetuning approaches, introducing an orthogonal new direction to unify the strengths of the autoregressive and diffusion frameworks.
$\text{Transformer}^2$: Self-adaptive LLMs
Jan 14, 2025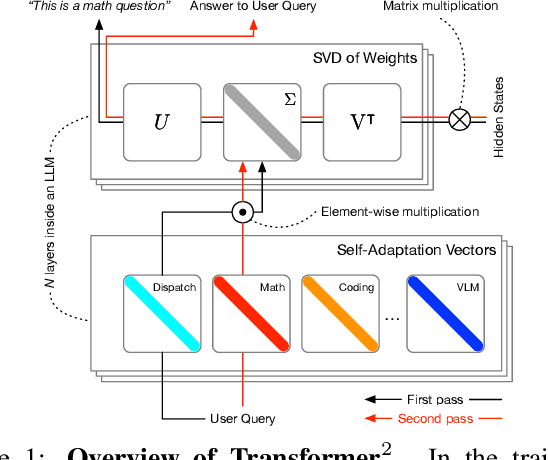
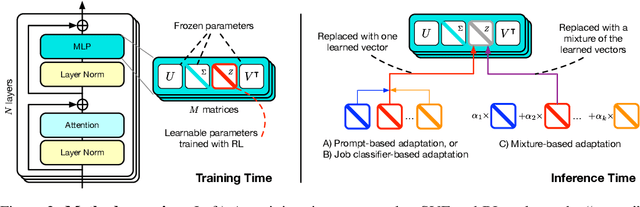
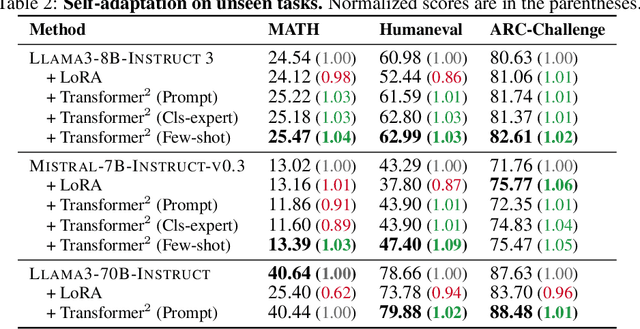

Self-adaptive large language models (LLMs) aim to solve the challenges posed by traditional fine-tuning methods, which are often computationally intensive and static in their ability to handle diverse tasks. We introduce $\text{Transformer}^2$, a novel self-adaptation framework that adapts LLMs for unseen tasks in real-time by selectively adjusting only the singular components of their weight matrices. During inference, $\text{Transformer}^2$ employs a two-pass mechanism: first, a dispatch system identifies the task properties, and then task-specific "expert" vectors, trained using reinforcement learning, are dynamically mixed to obtain targeted behavior for the incoming prompt. Our method outperforms ubiquitous approaches such as LoRA, with fewer parameters and greater efficiency. $\text{Transformer}^2$ demonstrates versatility across different LLM architectures and modalities, including vision-language tasks. $\text{Transformer}^2$ represents a significant leap forward, offering a scalable, efficient solution for enhancing the adaptability and task-specific performance of LLMs, paving the way for truly dynamic, self-organizing AI systems.
Automating the Search for Artificial Life with Foundation Models
Dec 23, 2024



With the recent Nobel Prize awarded for radical advances in protein discovery, foundation models (FMs) for exploring large combinatorial spaces promise to revolutionize many scientific fields. Artificial Life (ALife) has not yet integrated FMs, thus presenting a major opportunity for the field to alleviate the historical burden of relying chiefly on manual design and trial-and-error to discover the configurations of lifelike simulations. This paper presents, for the first time, a successful realization of this opportunity using vision-language FMs. The proposed approach, called Automated Search for Artificial Life (ASAL), (1) finds simulations that produce target phenomena, (2) discovers simulations that generate temporally open-ended novelty, and (3) illuminates an entire space of interestingly diverse simulations. Because of the generality of FMs, ASAL works effectively across a diverse range of ALife substrates including Boids, Particle Life, Game of Life, Lenia, and Neural Cellular Automata. A major result highlighting the potential of this technique is the discovery of previously unseen Lenia and Boids lifeforms, as well as cellular automata that are open-ended like Conway's Game of Life. Additionally, the use of FMs allows for the quantification of previously qualitative phenomena in a human-aligned way. This new paradigm promises to accelerate ALife research beyond what is possible through human ingenuity alone.
Evolution of Collective AI Beyond Individual Optimization
Dec 03, 2024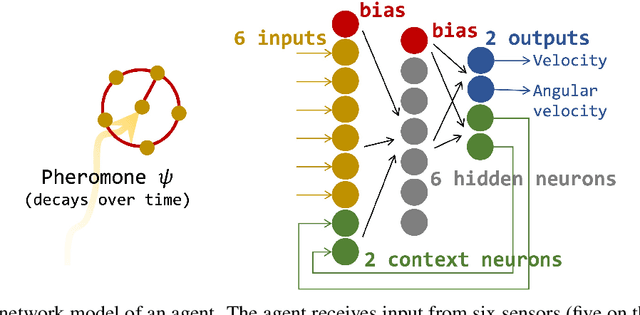

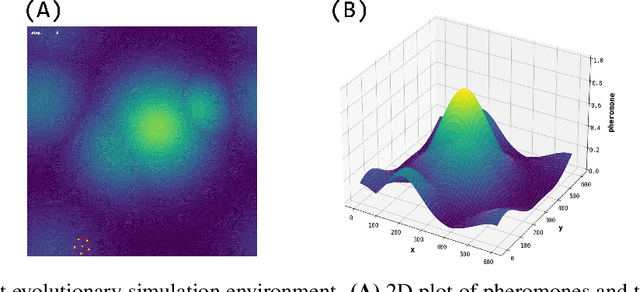
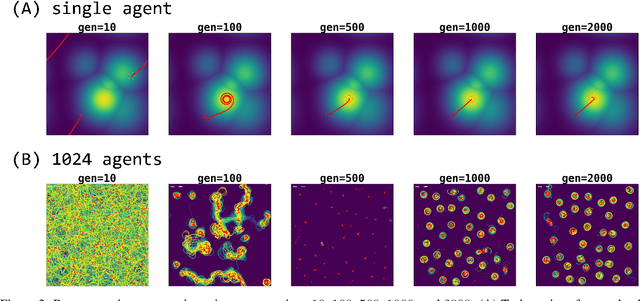
This study investigates collective behaviors that emerge from a group of homogeneous individuals optimized for a specific capability. We created a group of simple, identical neural network based agents modeled after chemotaxis-driven vehicles that follow pheromone trails and examined multi-agent simulations using clones of these evolved individuals. Our results show that the evolution of individuals led to population differentiation. Surprisingly, we observed that collective fitness significantly changed during later evolutionary stages, despite maintained high individual performance and simplified neural architectures. This decline occurred when agents developed reduced sensor-motor coupling, suggesting that over-optimization of individual agents almost always lead to less effective group behavior. Our research investigates how individual differentiation can evolve through what evolutionary pathways.