 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Reward Steering: An Adaptive Inference-Time Framework that Implicitly Promotes Cognitive Behaviors in Reasoning LLMs
May 30, 2026Strong reasoning depends not only on model knowledge but also on how effectively cognitive behaviors are deployed during generation. Existing methods often rely on explicit behavior-level control, making them insufficiently adaptive when failures and required corrections vary across reasoning states, tasks, and models. To this end, we propose Latent Reward Steering (LRS), an adaptive inference-time framework that promotes cognitive behaviors by optimizing the sparse-autoencoder (SAE) latent states that implicitly carry them. Rather than relying on predefined cognitive behaviors or steering directions derived from them, LRS trains a latent reward model on reasoning traces by final answer correctness to estimate the quality of intermediate latent states. During inference, reward gradients provide state-specific correction directions for fragile latent states, while a reward and confidence gate restricts intervention to states the reward signal flags as fragile. Experiments on multiple reasoning LLM backbones and benchmarks show that \ours consistently improves performance over various baselines, and post-hoc analyses further indicate that \ours implicitly promotes good cognitive behaviors that fix the original reasoning errors. Code is available at: https://github.com/jiakanglee/Latent-Reward-Steering.
Weak Critics Make Strong Learners: On-Policy Critique Distillation for Scalable Oversight
May 29, 2026As large language models become stronger, weak supervisors may fail to provide reliable labels, preferences, or final judgments for complex outputs, limiting both weak-to-strong generalization and scalable oversight. We study a more tractable form of weak supervision: using a weak model as a critic rather than as a labeler or judge. Instead of solving the task or selecting the correct answer, the weak critic only needs to provide a non-misleading revision direction that helps the strong model better use its own knowledge. We call this setting *weak-critic strong oversight*. We first show that weak critiques can improve frozen strong models at inference time, and that critique quality is key to this improvement. We then propose progressive on-policy critique distillation (**OPCD**), which filters high-quality critiques and distills critic-guided behavior into the strong model through adaptive self-teacher signals. Experiments on reasoning and alignment benchmarks show that our method improves strong models over training epochs, suggesting an effective path for scalable oversight with weak supervision.
DARE: Difficulty-Adaptive Reinforcement Learning with Co-Evolved Difficulty Estimation
May 09, 2026Reinforcement learning improves the reasoning ability of large language models but remains costly and sample-inefficient, as many rollouts provide weak learning signals. Difficulty-aware data selection methods attempt to address this by prioritizing moderately difficult prompts, yet our analysis reveals three limitations: difficulty estimates become inaccurate under policy drift, data selection alone yields limited final-performance gains, and inference efficiency remains largely unchanged. These findings suggest that efficient and effective RL requires more than filtering by difficulty: the policy should learn to solve hard tasks while producing concise responses for easy ones. To this end, we propose **Dare**, a unified framework that co-evolves difficulty estimation with the policy via self-normalized importance sampling, maintains diverse difficulty coverage through a symmetric Beta sampling distribution, and applies tailored training strategies across difficulty tiers with adaptive compute allocation. Extensive experiments across multiple models and domains demonstrate that **Dare** consistently outperforms existing methods in training efficiency, final effectiveness, and inference efficiency, producing more concise responses on easy tasks while improving correctness on hard ones. Code is available at https://github.com/EtaYang10th/DARE.
Evidence Over Plans: Online Trajectory Verification for Skill Distillation
May 09, 2026Agent skills can remarkably improve task success rates by using human-written procedural documents, but their quality is difficult to assess without environment-grounded verification. Existing skill generation methods heavily rely on preference logs rather than direct environment interaction, often yielding negligible or even degraded gains. We identify that it is a fundamental timing bottleneck: robust skills should be posterior-based, distilled from empirical environment interaction rather than prior plans. In this study, we introduce the Posterior Distillation Index (PDI), a trajectory-level metric that quantifies how well a distilled skill is grounded in the task-environment evidence. To operationalize PDI, we present SPARK (Structured Pipelines for Autonomous Runnable tasKs and sKill generation) for preserving task execution evidence towards full trajectory-level analysis. SPARK generates environment-verified trajectories used to compute PDI, and it applies PDI as an online diagnostic and intervention signal to ensure posterior skill formation. Across 86 runnable tasks, SPARK-generated skills consistently surpass no-skill baselines and outperform human-written skills on student models (inference cost up to 1,000x cheaper than teacher models). These findings show that PDI-guided distillation produces efficient and transferable skills grounded in the task-environment interaction. We release our code at https://github.com/EtaYang10th/spark-skills .
Evaluating LLMs When They Do Not Know the Answer: Statistical Evaluation of Mathematical Reasoning via Comparative Signals
Feb 03, 2026Evaluating mathematical reasoning in LLMs is constrained by limited benchmark sizes and inherent model stochasticity, yielding high-variance accuracy estimates and unstable rankings across platforms. On difficult problems, an LLM may fail to produce a correct final answer, yet still provide reliable pairwise comparison signals indicating which of two candidate solutions is better. We leverage this observation to design a statistically efficient evaluation framework that combines standard labeled outcomes with pairwise comparison signals obtained by having models judge auxiliary reasoning chains. Treating these comparison signals as control variates, we develop a semiparametric estimator based on the efficient influence function (EIF) for the setting where auxiliary reasoning chains are observed. This yields a one-step estimator that achieves the semiparametric efficiency bound, guarantees strict variance reduction over naive sample averaging, and admits asymptotic normality for principled uncertainty quantification. Across simulations, our one-step estimator substantially improves ranking accuracy, with gains increasing as model output noise grows. Experiments on GPQA Diamond, AIME 2025, and GSM8K further demonstrate more precise performance estimation and more reliable model rankings, especially in small-sample regimes where conventional evaluation is pretty unstable.
Reasoning over Precedents Alongside Statutes: Case-Augmented Deliberative Alignment for LLM Safety
Jan 12, 2026Ensuring that Large Language Models (LLMs) adhere to safety principles without refusing benign requests remains a significant challenge. While OpenAI introduces deliberative alignment (DA) to enhance the safety of its o-series models through reasoning over detailed ``code-like'' safety rules, the effectiveness of this approach in open-source LLMs, which typically lack advanced reasoning capabilities, is understudied. In this work, we systematically evaluate the impact of explicitly specifying extensive safety codes versus demonstrating them through illustrative cases. We find that referencing explicit codes inconsistently improves harmlessness and systematically degrades helpfulness, whereas training on case-augmented simple codes yields more robust and generalized safety behaviors. By guiding LLMs with case-augmented reasoning instead of extensive code-like safety rules, we avoid rigid adherence to narrowly enumerated rules and enable broader adaptability. Building on these insights, we propose CADA, a case-augmented deliberative alignment method for LLMs utilizing reinforcement learning on self-generated safety reasoning chains. CADA effectively enhances harmlessness, improves robustness against attacks, and reduces over-refusal while preserving utility across diverse benchmarks, offering a practical alternative to rule-only DA for improving safety while maintaining helpfulness.
Sparsity-Controllable Dynamic Top-p MoE for Large Foundation Model Pre-training
Dec 16, 2025Sparse Mixture-of-Experts (MoE) architectures effectively scale model capacity by activating only a subset of experts for each input token. However, the standard Top-k routing strategy imposes a uniform sparsity pattern that ignores the varying difficulty of tokens. While Top-p routing offers a flexible alternative, existing implementations typically rely on a fixed global probability threshold, which results in uncontrolled computational costs and sensitivity to hyperparameter selection. In this paper, we propose DTop-p MoE, a sparsity-controllable dynamic Top-p routing mechanism. To resolve the challenge of optimizing a non-differentiable threshold, we utilize a Proportional-Integral (PI) Controller that dynamically adjusts the probability threshold to align the running activated-expert sparsity with a specified target. Furthermore, we introduce a dynamic routing normalization mechanism that adapts layer-wise routing logits, allowing different layers to learn distinct expert-selection patterns while utilizing a global probability threshold. Extensive experiments on Large Language Models and Diffusion Transformers demonstrate that DTop-p consistently outperforms both Top-k and fixed-threshold Top-p baselines. Our analysis confirms that DTop-p maintains precise control over the number of activated experts while adaptively allocating resources across different tokens and layers. Furthermore, DTop-p exhibits strong scaling properties with respect to expert granularity, expert capacity, model size, and dataset size, offering a robust framework for large-scale MoE pre-training.
Mitigating Forgetting Between Supervised and Reinforcement Learning Yields Stronger Reasoners
Oct 06, 2025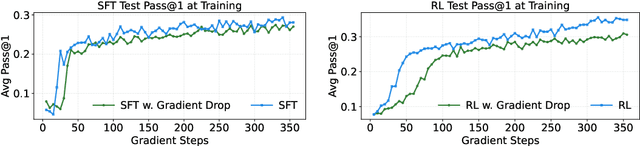
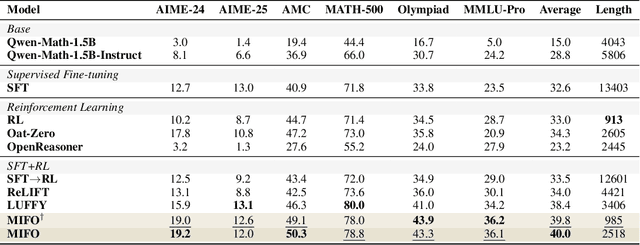
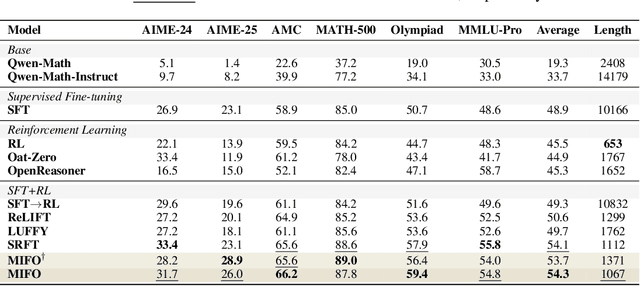

Large Language Models (LLMs) show strong reasoning abilities, often amplified by Chain-of-Thought (CoT) prompting and reinforcement learning (RL). Although RL algorithms can substantially improve reasoning, they struggle to expand reasoning boundaries because they learn from their own reasoning trajectories rather than acquiring external knowledge. Supervised fine-tuning (SFT) offers complementary benefits but typically requires large-scale data and risks overfitting. Recent attempts to combine SFT and RL face three main challenges: data inefficiency, algorithm-specific designs, and catastrophic forgetting. We propose a plug-and-play framework that dynamically integrates SFT into RL by selecting challenging examples for SFT. This approach reduces SFT data requirements and remains agnostic to the choice of RL or SFT algorithm. To mitigate catastrophic forgetting of RL-acquired skills during SFT, we select high-entropy tokens for loss calculation and freeze parameters identified as critical for RL. Our method achieves state-of-the-art (SoTA) reasoning performance using only 1.5% of the SFT data and 20.4% of the RL data used by prior SoTA, providing an efficient and plug-and-play solution for combining SFT and RL in reasoning post-training.
Effective Policy Learning for Multi-Agent Online Coordination Beyond Submodular Objectives
Sep 26, 2025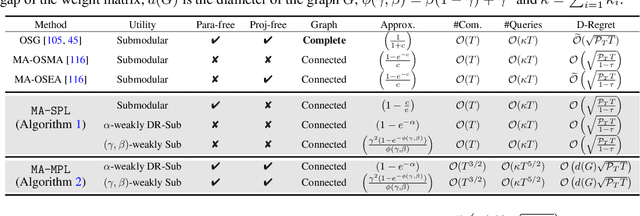

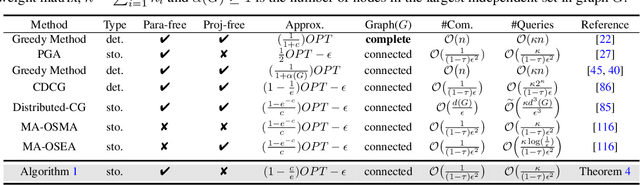
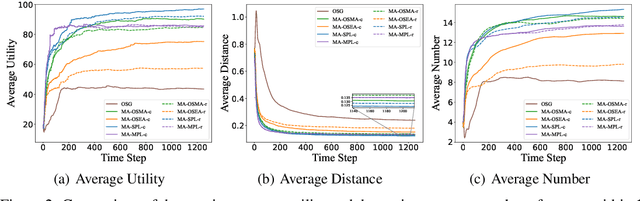
In this paper, we present two effective policy learning algorithms for multi-agent online coordination(MA-OC) problem. The first one, \texttt{MA-SPL}, not only can achieve the optimal $(1-\frac{c}{e})$-approximation guarantee for the MA-OC problem with submodular objectives but also can handle the unexplored $\alpha$-weakly DR-submodular and $(\gamma,\beta)$-weakly submodular scenarios, where $c$ is the curvature of the investigated submodular functions, $\alpha$ denotes the diminishing-return(DR) ratio and the tuple $(\gamma,\beta)$ represents the submodularity ratios. Subsequently, in order to reduce the reliance on the unknown parameters $\alpha,\gamma,\beta$ inherent in the \texttt{MA-SPL} algorithm, we further introduce the second online algorithm named \texttt{MA-MPL}. This \texttt{MA-MPL} algorithm is entirely \emph{parameter-free} and simultaneously can maintain the same approximation ratio as the first \texttt{MA-SPL} algorithm. The core of our \texttt{MA-SPL} and \texttt{MA-MPL} algorithms is a novel continuous-relaxation technique termed as \emph{policy-based continuous extension}. Compared with the well-established \emph{multi-linear extension}, a notable advantage of this new \emph{policy-based continuous extension} is its ability to provide a lossless rounding scheme for any set function, thereby enabling us to tackle the challenging weakly submodular objectives. Finally, extensive simulations are conducted to validate the effectiveness of our proposed algorithms.
Your Reward Function for RL is Your Best PRM for Search: Unifying RL and Search-Based TTS
Aug 19, 2025Test-time scaling (TTS) for large language models (LLMs) has thus far fallen into two largely separate paradigms: (1) reinforcement learning (RL) methods that optimize sparse outcome-based rewards, yet suffer from instability and low sample efficiency; and (2) search-based techniques guided by independently trained, static process reward models (PRMs), which require expensive human- or LLM-generated labels and often degrade under distribution shifts. In this paper, we introduce AIRL-S, the first natural unification of RL-based and search-based TTS. Central to AIRL-S is the insight that the reward function learned during RL training inherently represents the ideal PRM for guiding downstream search. Specifically, we leverage adversarial inverse reinforcement learning (AIRL) combined with group relative policy optimization (GRPO) to learn a dense, dynamic PRM directly from correct reasoning traces, entirely eliminating the need for labeled intermediate process data. At inference, the resulting PRM simultaneously serves as the critic for RL rollouts and as a heuristic to effectively guide search procedures, facilitating robust reasoning chain extension, mitigating reward hacking, and enhancing cross-task generalization. Experimental results across eight benchmarks, including mathematics, scientific reasoning, and code generation, demonstrate that our unified approach improves performance by 9 % on average over the base model, matching GPT-4o. Furthermore, when integrated into multiple search algorithms, our PRM consistently outperforms all baseline PRMs trained with labeled data. These results underscore that, indeed, your reward function for RL is your best PRM for search, providing a robust and cost-effective solution to complex reasoning tasks in LLMs.