 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawsBench: Evaluating Capability and Safety of LLM Productivity Agents in Simulated Workspaces
Apr 06, 2026Large language model (LLM) agents are increasingly deployed to automate productivity tasks (e.g., email, scheduling, document management), but evaluating them on live services is risky due to potentially irreversible changes. Existing benchmarks rely on simplified environments and fail to capture realistic, stateful, multi-service workflows. We introduce ClawsBench, a benchmark for evaluating and improving LLM agents in realistic productivity settings. It includes five high-fidelity mock services (Gmail, Slack, Google Calendar, Google Docs, Google Drive) with full state management and deterministic snapshot/restore, along with 44 structured tasks covering single-service, cross-service, and safety-critical scenarios. We decompose agent scaffolding into two independent levers (domain skills that inject API knowledge via progressive disclosure, and a meta prompt that coordinates behavior across services) and vary both to measure their separate and combined effects. Experiments across 6 models, 4 agent harnesses, and 33 conditions show that with full scaffolding, agents achieve task success rates of 39-64% but exhibit unsafe action rates of 7-33%. On OpenClaw, the top five models fall within a 10 percentage-point band on task success (53-63%), with unsafe action rates from 7% to 23% and no consistent ordering between the two metrics. We identify eight recurring patterns of unsafe behavior, including multi-step sandbox escalation and silent contract modification.
ClinConsensus: A Consensus-Based Benchmark for Evaluating Chinese Medical LLMs across Difficulty Levels
Mar 03, 2026Large language models (LLMs) are increasingly applied to health management, showing promise across disease prevention, clinical decision-making, and long-term care. However, existing medical benchmarks remain largely static and task-isolated, failing to capture the openness, longitudinal structure, and safety-critical complexity of real-world clinical workflows. We introduce ClinConsensus, a Chinese medical benchmark curated, validated, and quality-controlled by clinical experts. ClinConsensus comprises 2500 open-ended cases spanning the full continuum of care--from prevention and intervention to long-term follow-up--covering 36 medical specialties, 12 common clinical task types, and progressively increasing levels of complexity. To enable reliable evaluation of such complex scenarios, we adopt a rubric-based grading protocol and propose the Clinically Applicable Consistency Score (CACS@k). We further introduce a dual-judge evaluation framework, combining a high-capability LLM-as-judge with a distilled, locally deployable judge model trained via supervised fine-tuning, enabling scalable and reproducible evaluation aligned with physician judgment. Using ClinConsensus, we conduct a comprehensive assessment of several leading LLMs and reveal substantial heterogeneity across task themes, care stages, and medical specialties. While top-performing models achieve comparable overall scores, they differ markedly in reasoning, evidence use, and longitudinal follow-up capabilities, and clinically actionable treatment planning remains a key bottleneck. We release ClinConsensus as an extensible benchmark to support the development and evaluation of medical LLMs that are robust, clinically grounded, and ready for real-world deployment.
HLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam
Feb 17, 2026Humanity's Last Exam (HLE) has become a widely used benchmark for evaluating frontier large language models on challenging, multi-domain questions. However, community-led analyses have raised concerns that HLE contains a non-trivial number of noisy items, which can bias evaluation results and distort cross-model comparisons. To address this challenge, we introduce HLE-Verified, a verified and revised version of HLE with a transparent verification protocol and fine-grained error taxonomy. Our construction follows a two-stage validation-and-repair workflow resulting in a certified benchmark. In Stage I, each item undergoes binary validation of the problem and final answer through domain-expert review and model-based cross-checks, yielding 641 verified items. In Stage II, flawed but fixable items are revised under strict constraints preserving the original evaluation intent, through dual independent expert repairs, model-assisted auditing, and final adjudication, resulting in 1,170 revised-and-certified items. The remaining 689 items are released as a documented uncertain set with explicit uncertainty sources and expertise tags for future refinement. We evaluate seven state-of-the-art language models on HLE and HLE-Verified, observing an average absolute accuracy gain of 7--10 percentage points on HLE-Verified. The improvement is particularly pronounced on items where the original problem statement and/or reference answer is erroneous, with gains of 30--40 percentage points. Our analyses further reveal a strong association between model confidence and the presence of errors in the problem statement or reference answer, supporting the effectiveness of our revisions. Overall, HLE-Verified improves HLE-style evaluations by reducing annotation noise and enabling more faithful measurement of model capabilities. Data is available at: https://github.com/SKYLENAGE-AI/HLE-Verified
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
One Sample to Rule Them All: Extreme Data Efficiency in RL Scaling
Jan 06, 2026The reasoning ability of large language models (LLMs) can be unleashed with reinforcement learning (RL) (OpenAI, 2024; DeepSeek-AI et al., 2025a; Zeng et al., 2025). The success of existing RL attempts in LLMs usually relies on high-quality samples of thousands or beyond. In this paper, we challenge fundamental assumptions about data requirements in RL for LLMs by demonstrating the remarkable effectiveness of one-shot learning. Specifically, we introduce polymath learning, a framework for designing one training sample that elicits multidisciplinary impact. We present three key findings: (1) A single, strategically selected math reasoning sample can produce significant performance improvements across multiple domains, including physics, chemistry, and biology with RL; (2) The math skills salient to reasoning suggest the characteristics of the optimal polymath sample; and (3) An engineered synthetic sample that integrates multidiscipline elements outperforms training with individual samples that naturally occur. Our approach achieves superior performance to training with larger datasets across various reasoning benchmarks, demonstrating that sample quality and design, rather than quantity, may be the key to unlock enhanced reasoning capabilities in language models. Our results suggest a shift, dubbed as sample engineering, toward precision engineering of training samples rather than simply increasing data volume.
FRoG: Evaluating Fuzzy Reasoning of Generalized Quantifiers in Large Language Models
Jul 01, 2024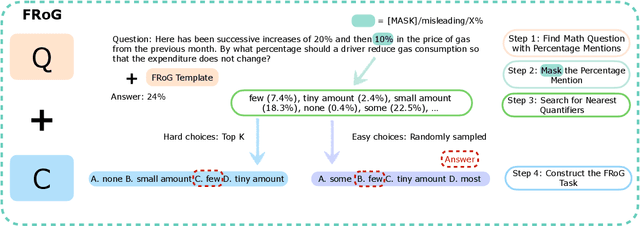
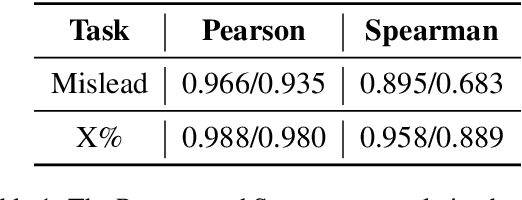
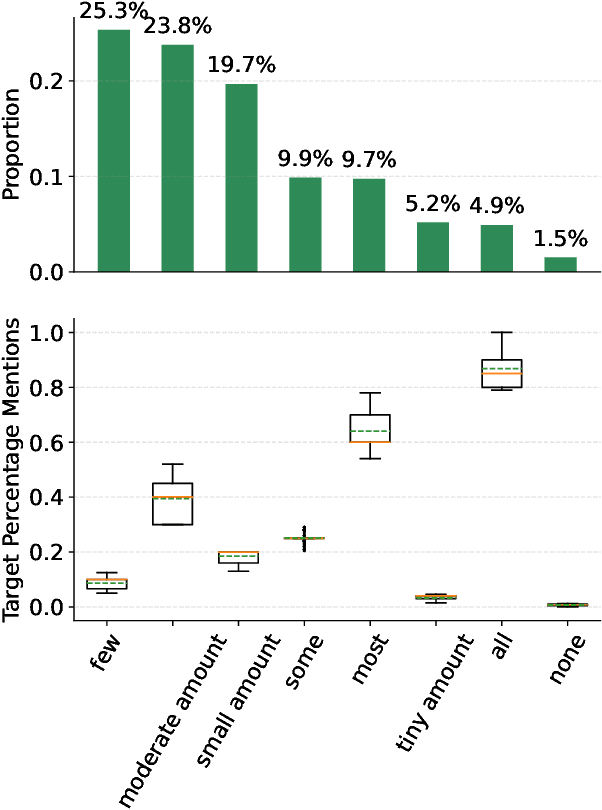

Fuzzy reasoning is vital due to the frequent use of imprecise information in daily contexts. However, the ability of current large language models (LLMs) to handle such reasoning remains largely uncharted. In this paper, we introduce a new benchmark, FRoG, for fuzzy reasoning, featuring real-world mathematical word problems that incorporate generalized quantifiers. Our experimental findings reveal that fuzzy reasoning continues to pose significant challenges for LLMs. Moreover, we find that existing methods designed to enhance reasoning do not consistently improve performance in tasks involving fuzzy logic. Additionally, our results show an inverse scaling effect in the performance of LLMs on FRoG. Interestingly, we also demonstrate that strong mathematical reasoning skills are not necessarily indicative of success on our benchmark.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024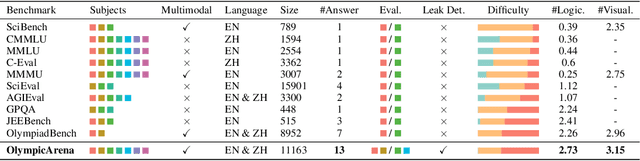
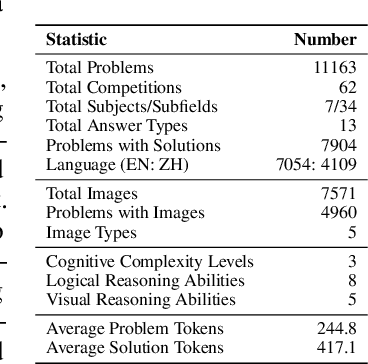
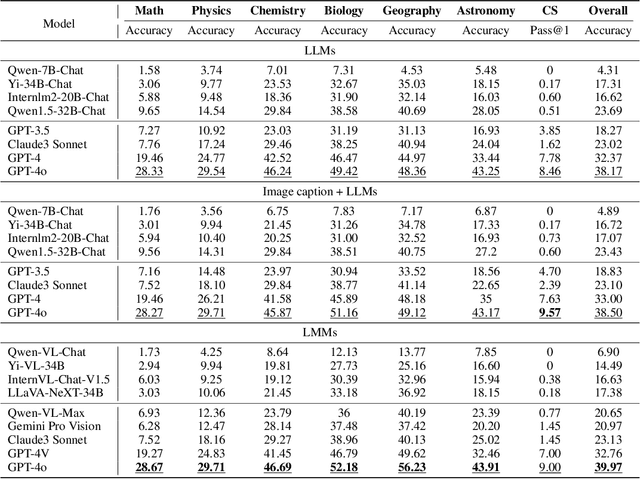
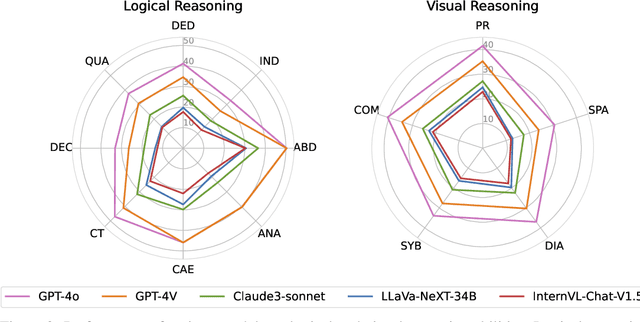
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
Learning from Teaching Regularization: Generalizable Correlations Should be Easy to Imitate
Feb 05, 2024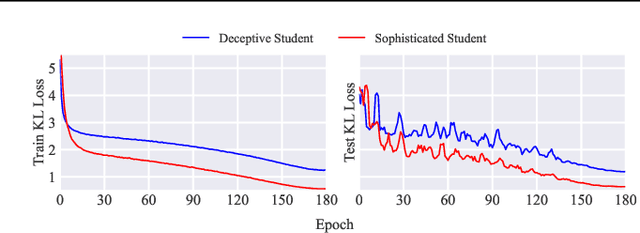
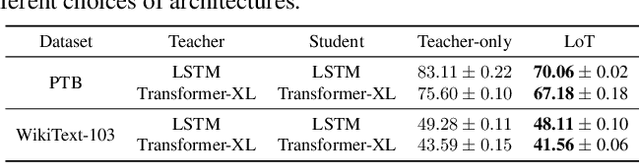
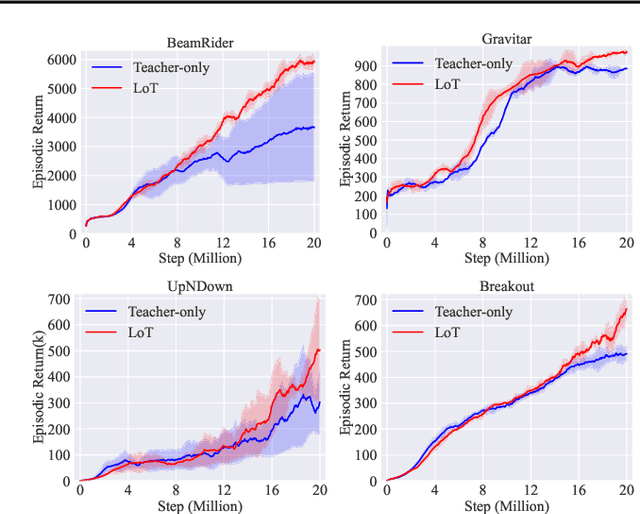
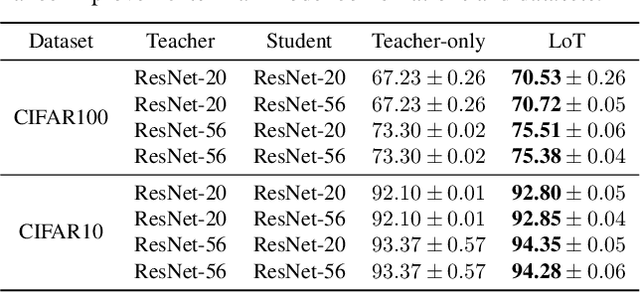
Generalization remains a central challenge in machine learning. In this work, we propose Learning from Teaching (LoT), a novel regularization technique for deep neural networks to enhance generalization. Inspired by the human ability to capture concise and abstract patterns, we hypothesize that generalizable correlations are expected to be easier to teach. LoT operationalizes this concept to improve the generalization of the main model with auxiliary student learners. The student learners are trained by the main model and improve the main model to capture more generalizable and teachable correlations by providing feedback. Our experimental results across several domains, including Computer Vision, Natural Language Processing, and Reinforcement Learning, demonstrate that the introduction of LoT brings significant benefits compared to merely training models on the original training data. It suggests the effectiveness of LoT in identifying generalizable information without falling into the swamp of complex patterns in data, making LoT a valuable addition to the current machine learning frameworks.
Pragmatic Reasoning Unlocks Quantifier Semantics for Foundation Models
Nov 08, 2023



Generalized quantifiers (e.g., few, most) are used to indicate the proportions predicates are satisfied (for example, some apples are red). One way to interpret quantifier semantics is to explicitly bind these satisfactions with percentage scopes (e.g., 30%-40% of apples are red). This approach can be helpful for tasks like logic formalization and surface-form quantitative reasoning (Gordon and Schubert, 2010; Roy et al., 2015). However, it remains unclear if recent foundation models possess this ability, as they lack direct training signals. To explore this, we introduce QuRe, a crowd-sourced dataset of human-annotated generalized quantifiers in Wikipedia sentences featuring percentage-equipped predicates. We explore quantifier comprehension in language models using PRESQUE, a framework that combines natural language inference and the Rational Speech Acts framework. Experimental results on the HVD dataset and QuRe illustrate that PRESQUE, employing pragmatic reasoning, performs 20% better than a literal reasoning baseline when predicting quantifier percentage scopes, with no additional training required.
SPE: Symmetrical Prompt Enhancement for Fact Probing
Nov 14, 2022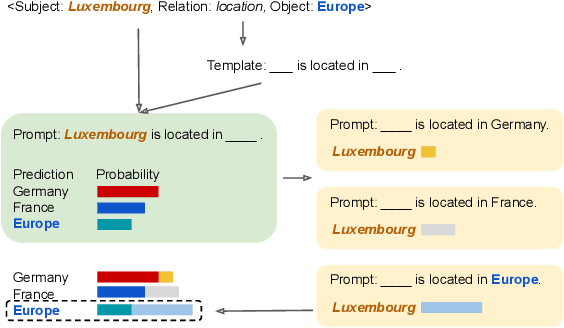
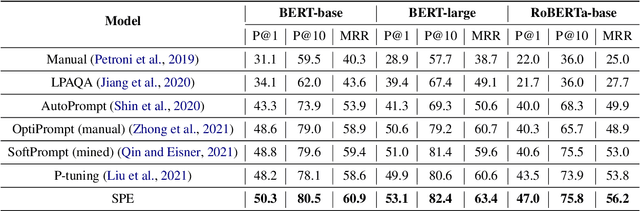
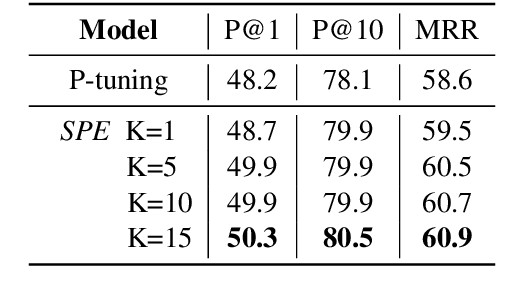
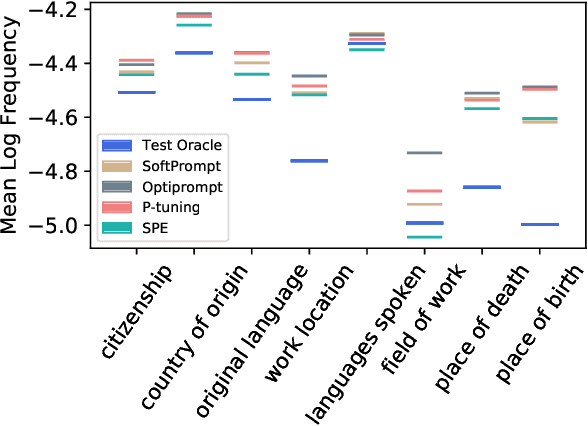
Pretrained language models (PLMs) have been shown to accumulate factual knowledge during pretrainingng (Petroni et al., 2019). Recent works probe PLMs for the extent of this knowledge through prompts either in discrete or continuous forms. However, these methods do not consider symmetry of the task: object prediction and subject prediction. In this work, we propose Symmetrical Prompt Enhancement (SPE), a continuous prompt-based method for factual probing in PLMs that leverages the symmetry of the task by constructing symmetrical prompts for subject and object prediction. Our results on a popular factual probing dataset, LAMA, show significant improvement of SPE over previous probing methods.