 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRoG: Evaluating Fuzzy Reasoning of Generalized Quantifiers in Large Language Models
Paper and Code
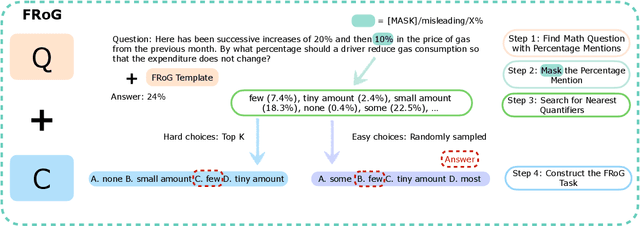
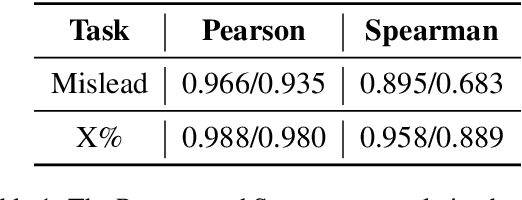
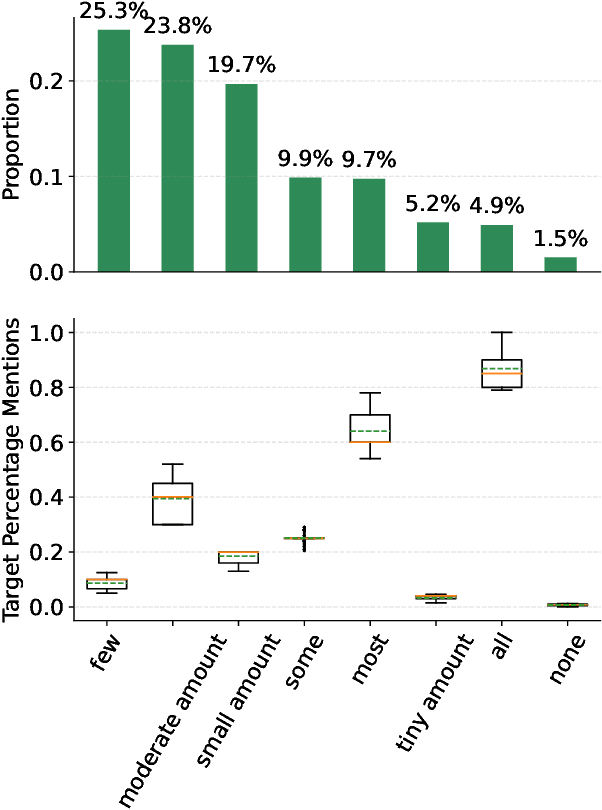

Fuzzy reasoning is vital due to the frequent use of imprecise information in daily contexts. However, the ability of current large language models (LLMs) to handle such reasoning remains largely uncharted. In this paper, we introduce a new benchmark, FRoG, for fuzzy reasoning, featuring real-world mathematical word problems that incorporate generalized quantifiers. Our experimental findings reveal that fuzzy reasoning continues to pose significant challenges for LLMs. Moreover, we find that existing methods designed to enhance reasoning do not consistently improve performance in tasks involving fuzzy logic. Additionally, our results show an inverse scaling effect in the performance of LLMs on FRoG. Interestingly, we also demonstrate that strong mathematical reasoning skills are not necessarily indicative of success on our benchmark.