 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBladeSDF : Unconditional and Conditional Generative Modeling of Representative Blade Geometries Using Signed Distance Functions
Jan 19, 2026Generative AI has emerged as a transformative paradigm in engineering design, enabling automated synthesis and reconstruction of complex 3D geometries while preserving feasibility and performance relevance. This paper introduces a domain-specific implicit generative framework for turbine blade geometry using DeepSDF, addressing critical gaps in performance-aware modeling and manufacturable design generation. The proposed method leverages a continuous signed distance function (SDF) representation to reconstruct and generate smooth, watertight geometries with quantified accuracy. It establishes an interpretable, near-Gaussian latent space that aligns with blade-relevant parameters, such as taper and chord ratios, enabling controlled exploration and unconditional synthesis through interpolation and Gaussian sampling. In addition, a compact neural network maps engineering descriptors, such as maximum directional strains, to latent codes, facilitating the generation of performance-informed geometry. The framework achieves high reconstruction fidelity, with surface distance errors concentrated within $1\%$ of the maximum blade dimension, and demonstrates robust generalization to unseen designs. By integrating constraints, objectives, and performance metrics, this approach advances beyond traditional 2D-guided or unconstrained 3D pipelines, offering a practical and interpretable solution for data-driven turbine blade modeling and concept generation.
MassiveGNN: Efficient Training via Prefetching for Massively Connected Distributed Graphs
Oct 30, 2024Graph Neural Networks (GNN) are indispensable in learning from graph-structured data, yet their rising computational costs, especially on massively connected graphs, pose significant challenges in terms of execution performance. To tackle this, distributed-memory solutions such as partitioning the graph to concurrently train multiple replicas of GNNs are in practice. However, approaches requiring a partitioned graph usually suffer from communication overhead and load imbalance, even under optimal partitioning and communication strategies due to irregularities in the neighborhood minibatch sampling. This paper proposes practical trade-offs for improving the sampling and communication overheads for representation learning on distributed graphs (using popular GraphSAGE architecture) by developing a parameterized continuous prefetch and eviction scheme on top of the state-of-the-art Amazon DistDGL distributed GNN framework, demonstrating about 15-40% improvement in end-to-end training performance on the National Energy Research Scientific Computing Center's (NERSC) Perlmutter supercomputer for various OGB datasets.
Final Report for CHESS: Cloud, High-Performance Computing, and Edge for Science and Security
Oct 21, 2024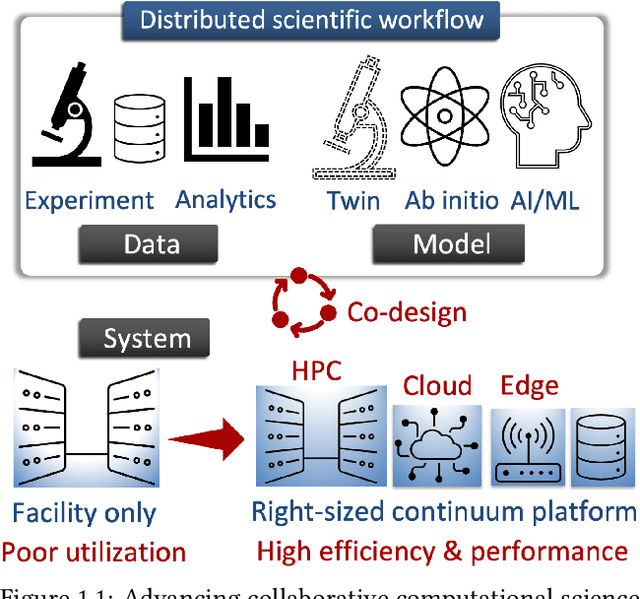
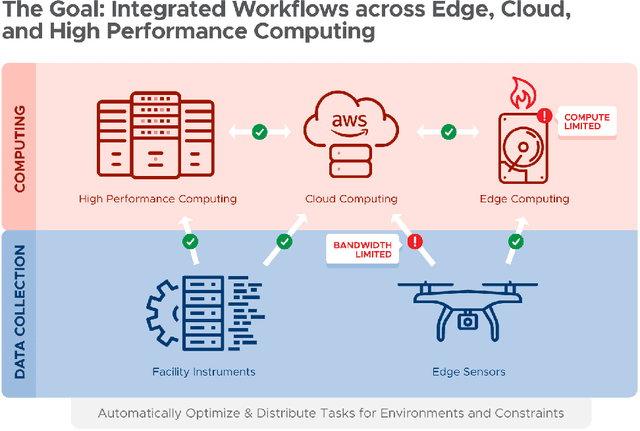
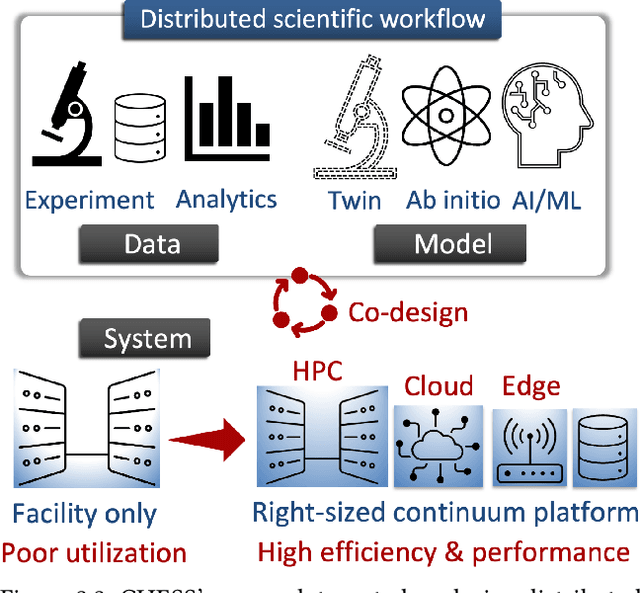

Automating the theory-experiment cycle requires effective distributed workflows that utilize a computing continuum spanning lab instruments, edge sensors, computing resources at multiple facilities, data sets distributed across multiple information sources, and potentially cloud. Unfortunately, the obvious methods for constructing continuum platforms, orchestrating workflow tasks, and curating datasets over time fail to achieve scientific requirements for performance, energy, security, and reliability. Furthermore, achieving the best use of continuum resources depends upon the efficient composition and execution of workflow tasks, i.e., combinations of numerical solvers, data analytics, and machine learning. Pacific Northwest National Laboratory's LDRD "Cloud, High-Performance Computing (HPC), and Edge for Science and Security" (CHESS) has developed a set of interrelated capabilities for enabling distributed scientific workflows and curating datasets. This report describes the results and successes of CHESS from the perspective of open science.
Heterogenous Multi-Source Data Fusion Through Input Mapping and Latent Variable Gaussian Process
Jul 15, 2024Artificial intelligence and machine learning frameworks have served as computationally efficient mapping between inputs and outputs for engineering problems. These mappings have enabled optimization and analysis routines that have warranted superior designs, ingenious material systems and optimized manufacturing processes. A common occurrence in such modeling endeavors is the existence of multiple source of data, each differentiated by fidelity, operating conditions, experimental conditions, and more. Data fusion frameworks have opened the possibility of combining such differentiated sources into single unified models, enabling improved accuracy and knowledge transfer. However, these frameworks encounter limitations when the different sources are heterogeneous in nature, i.e., not sharing the same input parameter space. These heterogeneous input scenarios can occur when the domains differentiated by complexity, scale, and fidelity require different parametrizations. Towards addressing this void, a heterogeneous multi-source data fusion framework is proposed based on input mapping calibration (IMC) and latent variable Gaussian process (LVGP). In the first stage, the IMC algorithm is utilized to transform the heterogeneous input parameter spaces into a unified reference parameter space. In the second stage, a multi-source data fusion model enabled by LVGP is leveraged to build a single source-aware surrogate model on the transformed reference space. The proposed framework is demonstrated and analyzed on three engineering case studies (design of cantilever beam, design of ellipsoidal void and modeling properties of Ti6Al4V alloy). The results indicate that the proposed framework provides improved predictive accuracy over a single source model and transformed but source unaware model.
Compare without Despair: Reliable Preference Evaluation with Generation Separability
Jul 02, 2024



Human evaluation of generated language through pairwise preference judgments is pervasive. However, under common scenarios, such as when generations from a model pair are very similar, or when stochastic decoding results in large variations in generations, it results in inconsistent preference ratings. We address these challenges by introducing a meta-evaluation measure, separability, which estimates how suitable a test instance is for pairwise preference evaluation. For a candidate test instance, separability samples multiple generations from a pair of models, and measures how distinguishable the two sets of generations are. Our experiments show that instances with high separability values yield more consistent preference ratings from both human- and auto-raters. Further, the distribution of separability allows insights into which test benchmarks are more valuable for comparing models. Finally, we incorporate separability into ELO ratings, accounting for how suitable each test instance might be for reliably ranking LLMs. Overall, separability has implications for consistent, efficient and robust preference evaluation of LLMs with both human- and auto-raters.
Instance Segmentation and Teeth Classification in Panoramic X-rays
Jun 06, 2024Teeth segmentation and recognition are critical in various dental applications and dental diagnosis. Automatic and accurate segmentation approaches have been made possible by integrating deep learning models. Although teeth segmentation has been studied in the past, only some techniques were able to effectively classify and segment teeth simultaneously. This article offers a pipeline of two deep learning models, U-Net and YOLOv8, which results in BB-UNet, a new architecture for the classification and segmentation of teeth on panoramic X-rays that is efficient and reliable. We have improved the quality and reliability of teeth segmentation by utilising the YOLOv8 and U-Net capabilities. The proposed networks have been evaluated using the mean average precision (mAP) and dice coefficient for YOLOv8 and BB-UNet, respectively. We have achieved a 3\% increase in mAP score for teeth classification compared to existing methods, and a 10-15\% increase in dice coefficient for teeth segmentation compared to U-Net across different categories of teeth. A new Dental dataset was created based on UFBA-UESC dataset with Bounding-Box and Polygon annotations of 425 dental panoramic X-rays. The findings of this research pave the way for a wider adoption of object detection models in the field of dental diagnosis.
Deep Oscillatory Neural Network
May 06, 2024We propose a novel, brain-inspired deep neural network model known as the Deep Oscillatory Neural Network (DONN). Deep neural networks like the Recurrent Neural Networks indeed possess sequence processing capabilities but the internal states of the network are not designed to exhibit brain-like oscillatory activity. With this motivation, the DONN is designed to have oscillatory internal dynamics. Neurons of the DONN are either nonlinear neural oscillators or traditional neurons with sigmoidal or ReLU activation. The neural oscillator used in the model is the Hopf oscillator, with the dynamics described in the complex domain. Input can be presented to the neural oscillator in three possible modes. The sigmoid and ReLU neurons also use complex-valued extensions. All the weight stages are also complex-valued. Training follows the general principle of weight change by minimizing the output error and therefore has an overall resemblance to complex backpropagation. A generalization of DONN to convolutional networks known as the Oscillatory Convolutional Neural Network is also proposed. The two proposed oscillatory networks are applied to a variety of benchmark problems in signal and image/video processing. The performance of the proposed models is either comparable or superior to published results on the same data sets.
Interpretable Multi-Source Data Fusion Through Latent Variable Gaussian Process
Feb 16, 2024With the advent of artificial intelligence (AI) and machine learning (ML), various domains of science and engineering communites has leveraged data-driven surrogates to model complex systems from numerous sources of information (data). The proliferation has led to significant reduction in cost and time involved in development of superior systems designed to perform specific functionalities. A high proposition of such surrogates are built extensively fusing multiple sources of data, may it be published papers, patents, open repositories, or other resources. However, not much attention has been paid to the differences in quality and comprehensiveness of the known and unknown underlying physical parameters of the information sources that could have downstream implications during system optimization. Towards resolving this issue, a multi-source data fusion framework based on Latent Variable Gaussian Process (LVGP) is proposed. The individual data sources are tagged as a characteristic categorical variable that are mapped into a physically interpretable latent space, allowing the development of source-aware data fusion modeling. Additionally, a dissimilarity metric based on the latent variables of LVGP is introduced to study and understand the differences in the sources of data. The proposed approach is demonstrated on and analyzed through two mathematical (representative parabola problem, 2D Ackley function) and two materials science (design of FeCrAl and SmCoFe alloys) case studies. From the case studies, it is observed that compared to using single-source and source unaware ML models, the proposed multi-source data fusion framework can provide better predictions for sparse-data problems, interpretability regarding the sources, and enhanced modeling capabilities by taking advantage of the correlations and relationships among different sources.
Leveraging Multiple Teachers for Test-Time Adaptation of Language-Guided Classifiers
Nov 13, 2023Recent approaches have explored language-guided classifiers capable of classifying examples from novel tasks when provided with task-specific natural language explanations, instructions or prompts (Sanh et al., 2022; R. Menon et al., 2022). While these classifiers can generalize in zero-shot settings, their task performance often varies substantially between different language explanations in unpredictable ways (Lu et al., 2022; Gonen et al., 2022). Also, current approaches fail to leverage unlabeled examples that may be available in many scenarios. Here, we introduce TALC, a framework that uses data programming to adapt a language-guided classifier for a new task during inference when provided with explanations from multiple teachers and unlabeled test examples. Our results show that TALC consistently outperforms a competitive baseline from prior work by an impressive 9.3% (relative improvement). Further, we demonstrate the robustness of TALC to variations in the quality and quantity of provided explanations, highlighting its potential in scenarios where learning from multiple teachers or a crowd is involved. Our code is available at: https://github.com/WeiKangda/TALC.git.
Pragmatic Reasoning Unlocks Quantifier Semantics for Foundation Models
Nov 08, 2023



Generalized quantifiers (e.g., few, most) are used to indicate the proportions predicates are satisfied (for example, some apples are red). One way to interpret quantifier semantics is to explicitly bind these satisfactions with percentage scopes (e.g., 30%-40% of apples are red). This approach can be helpful for tasks like logic formalization and surface-form quantitative reasoning (Gordon and Schubert, 2010; Roy et al., 2015). However, it remains unclear if recent foundation models possess this ability, as they lack direct training signals. To explore this, we introduce QuRe, a crowd-sourced dataset of human-annotated generalized quantifiers in Wikipedia sentences featuring percentage-equipped predicates. We explore quantifier comprehension in language models using PRESQUE, a framework that combines natural language inference and the Rational Speech Acts framework. Experimental results on the HVD dataset and QuRe illustrate that PRESQUE, employing pragmatic reasoning, performs 20% better than a literal reasoning baseline when predicting quantifier percentage scopes, with no additional training required.