 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperSAM: Crafting a SAM Supernetwork via Structured Pruning and Unstructured Parameter Prioritization
Jan 15, 2025



Neural Architecture Search (NAS) is a powerful approach of automating the design of efficient neural architectures. In contrast to traditional NAS methods, recently proposed one-shot NAS methods prove to be more efficient in performing NAS. One-shot NAS works by generating a singular weight-sharing supernetwork that acts as a search space (container) of subnetworks. Despite its achievements, designing the one-shot search space remains a major challenge. In this work we propose a search space design strategy for Vision Transformer (ViT)-based architectures. In particular, we convert the Segment Anything Model (SAM) into a weight-sharing supernetwork called SuperSAM. Our approach involves automating the search space design via layer-wise structured pruning and parameter prioritization. While the structured pruning applies probabilistic removal of certain transformer layers, parameter prioritization performs weight reordering and slicing of MLP-blocks in the remaining layers. We train supernetworks on several datasets using the sandwich rule. For deployment, we enhance subnetwork discovery by utilizing a program autotuner to identify efficient subnetworks within the search space. The resulting subnetworks are 30-70% smaller in size compared to the original pre-trained SAM ViT-B, yet outperform the pretrained model. Our work introduces a new and effective method for ViT NAS search-space design.
AI-Enabled Operations at Fermi Complex: Multivariate Time Series Prediction for Outage Prediction and Diagnosis
Jan 02, 2025



The Main Control Room of the Fermilab accelerator complex continuously gathers extensive time-series data from thousands of sensors monitoring the beam. However, unplanned events such as trips or voltage fluctuations often result in beam outages, causing operational downtime. This downtime not only consumes operator effort in diagnosing and addressing the issue but also leads to unnecessary energy consumption by idle machines awaiting beam restoration. The current threshold-based alarm system is reactive and faces challenges including frequent false alarms and inconsistent outage-cause labeling. To address these limitations, we propose an AI-enabled framework that leverages predictive analytics and automated labeling. Using data from $2,703$ Linac devices and $80$ operator-labeled outages, we evaluate state-of-the-art deep learning architectures, including recurrent, attention-based, and linear models, for beam outage prediction. Additionally, we assess a Random Forest-based labeling system for providing consistent, confidence-scored outage annotations. Our findings highlight the strengths and weaknesses of these architectures for beam outage prediction and identify critical gaps that must be addressed to fully harness AI for transitioning downtime handling from reactive to predictive, ultimately reducing downtime and improving decision-making in accelerator management.
Final Report for CHESS: Cloud, High-Performance Computing, and Edge for Science and Security
Oct 21, 2024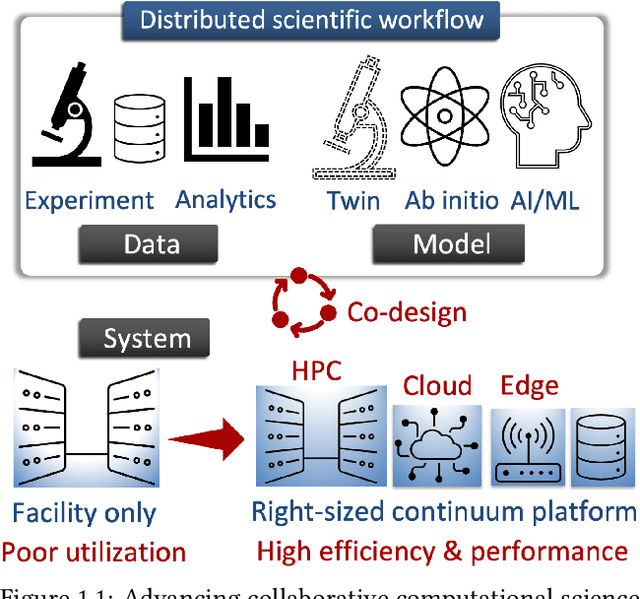
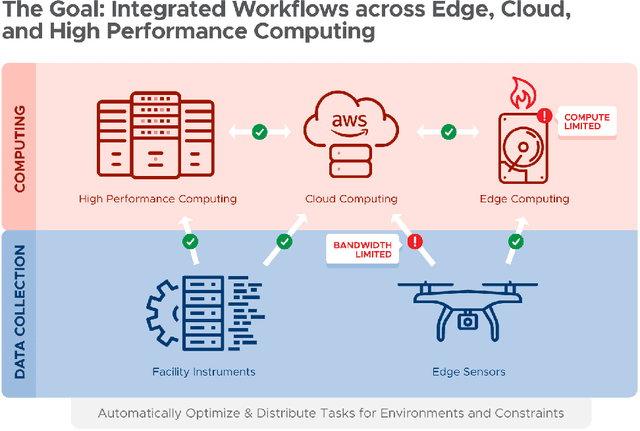
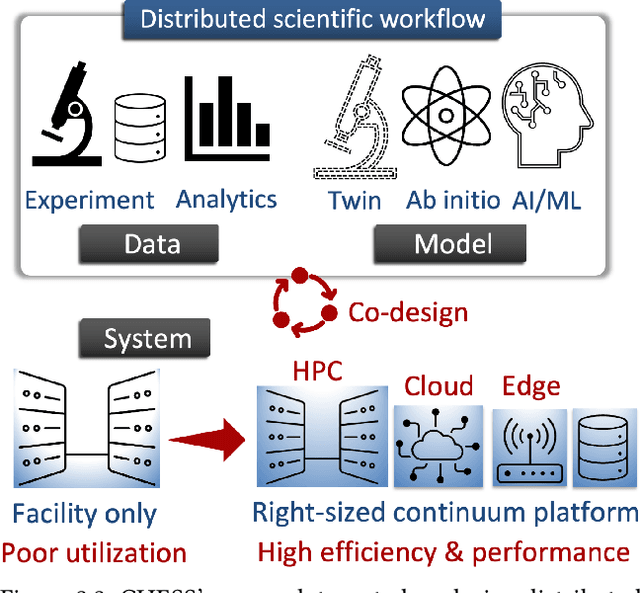

Automating the theory-experiment cycle requires effective distributed workflows that utilize a computing continuum spanning lab instruments, edge sensors, computing resources at multiple facilities, data sets distributed across multiple information sources, and potentially cloud. Unfortunately, the obvious methods for constructing continuum platforms, orchestrating workflow tasks, and curating datasets over time fail to achieve scientific requirements for performance, energy, security, and reliability. Furthermore, achieving the best use of continuum resources depends upon the efficient composition and execution of workflow tasks, i.e., combinations of numerical solvers, data analytics, and machine learning. Pacific Northwest National Laboratory's LDRD "Cloud, High-Performance Computing (HPC), and Edge for Science and Security" (CHESS) has developed a set of interrelated capabilities for enabling distributed scientific workflows and curating datasets. This report describes the results and successes of CHESS from the perspective of open science.
PermitQA: A Benchmark for Retrieval Augmented Generation in Wind Siting and Permitting domain
Aug 21, 2024

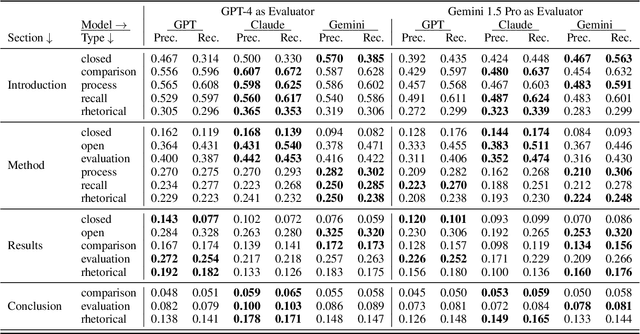
In the rapidly evolving landscape of Natural Language Processing (NLP) and text generation, the emergence of Retrieval Augmented Generation (RAG) presents a promising avenue for improving the quality and reliability of generated text by leveraging information retrieved from user specified database. Benchmarking is essential to evaluate and compare the performance of the different RAG configurations in terms of retriever and generator, providing insights into their effectiveness, scalability, and suitability for the specific domain and applications. In this paper, we present a comprehensive framework to generate a domain relevant RAG benchmark. Our framework is based on automatic question-answer generation with Human (domain experts)-AI Large Language Model (LLM) teaming. As a case study, we demonstrate the framework by introducing PermitQA, a first-of-its-kind benchmark on the wind siting and permitting domain which comprises of multiple scientific documents/reports related to environmental impact of wind energy projects. Our framework systematically evaluates RAG performance using diverse metrics and multiple question types with varying complexity level. We also demonstrate the performance of different models on our benchmark.
SAM-I-Am: Semantic Boosting for Zero-shot Atomic-Scale Electron Micrograph Segmentation
Apr 09, 2024



Image segmentation is a critical enabler for tasks ranging from medical diagnostics to autonomous driving. However, the correct segmentation semantics - where are boundaries located? what segments are logically similar? - change depending on the domain, such that state-of-the-art foundation models can generate meaningless and incorrect results. Moreover, in certain domains, fine-tuning and retraining techniques are infeasible: obtaining labels is costly and time-consuming; domain images (micrographs) can be exponentially diverse; and data sharing (for third-party retraining) is restricted. To enable rapid adaptation of the best segmentation technology, we propose the concept of semantic boosting: given a zero-shot foundation model, guide its segmentation and adjust results to match domain expectations. We apply semantic boosting to the Segment Anything Model (SAM) to obtain microstructure segmentation for transmission electron microscopy. Our booster, SAM-I-Am, extracts geometric and textural features of various intermediate masks to perform mask removal and mask merging operations. We demonstrate a zero-shot performance increase of (absolute) +21.35%, +12.6%, +5.27% in mean IoU, and a -9.91%, -18.42%, -4.06% drop in mean false positive masks across images of three difficulty classes over vanilla SAM (ViT-L).
Neural Ordinary Differential Equations for Nonlinear System Identification
Mar 15, 2022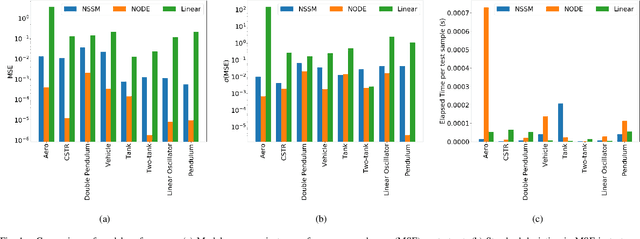
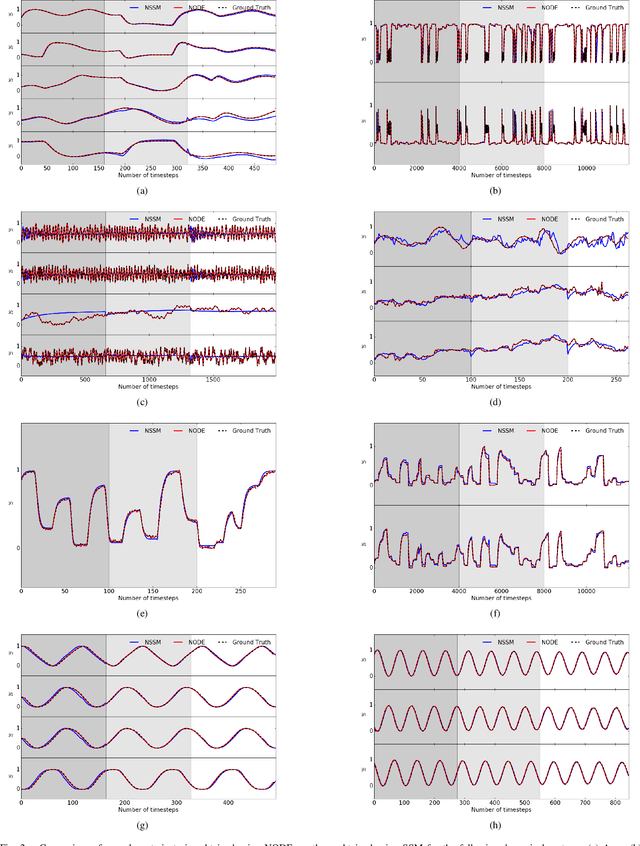
Neural ordinary differential equations (NODE) have been recently proposed as a promising approach for nonlinear system identification tasks. In this work, we systematically compare their predictive performance with current state-of-the-art nonlinear and classical linear methods. In particular, we present a quantitative study comparing NODE's performance against neural state-space models and classical linear system identification methods. We evaluate the inference speed and prediction performance of each method on open-loop errors across eight different dynamical systems. The experiments show that NODEs can consistently improve the prediction accuracy by an order of magnitude compared to benchmark methods. Besides improved accuracy, we also observed that NODEs are less sensitive to hyperparameters compared to neural state-space models. On the other hand, these performance gains come with a slight increase of computation at the inference time.
Accelerated Computation of a High Dimensional Kolmogorov-Smirnov Distance
Jun 25, 2021
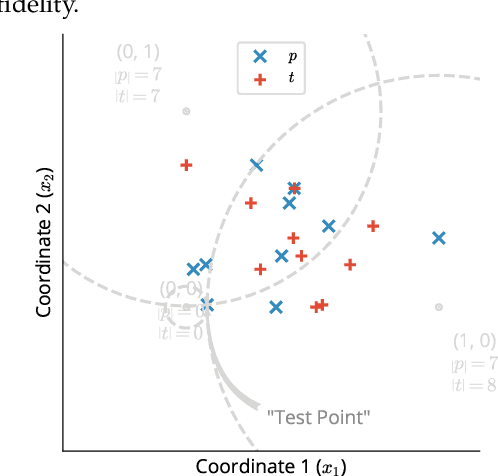


Statistical testing is widespread and critical for a variety of scientific disciplines. The advent of machine learning and the increase of computing power has increased the interest in the analysis and statistical testing of multidimensional data. We extend the powerful Kolmogorov-Smirnov two sample test to a high dimensional form in a similar manner to Fasano (Fasano, 1987). We call our result the d-dimensional Kolmogorov-Smirnov test (ddKS) and provide three novel contributions therewith: we develop an analytical equation for the significance of a given ddKS score, we provide an algorithm for computation of ddKS on modern computing hardware that is of constant time complexity for small sample sizes and dimensions, and we provide two approximate calculations of ddKS: one that reduces the time complexity to linear at larger sample sizes, and another that reduces the time complexity to linear with increasing dimension. We perform power analysis of ddKS and its approximations on a corpus of datasets and compare to other common high dimensional two sample tests and distances: Hotelling's T^2 test and Kullback-Leibler divergence. Our ddKS test performs well for all datasets, dimensions, and sizes tested, whereas the other tests and distances fail to reject the null hypothesis on at least one dataset. We therefore conclude that ddKS is a powerful multidimensional two sample test for general use, and can be calculated in a fast and efficient manner using our parallel or approximate methods. Open source implementations of all methods described in this work are located at https://github.com/pnnl/ddks.
Scaling the training of particle classification on simulated MicroBooNE events to multiple GPUs
Apr 17, 2020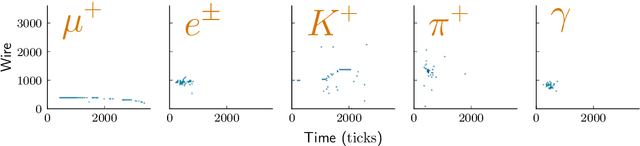
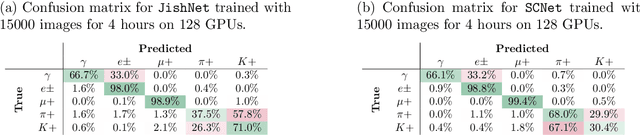
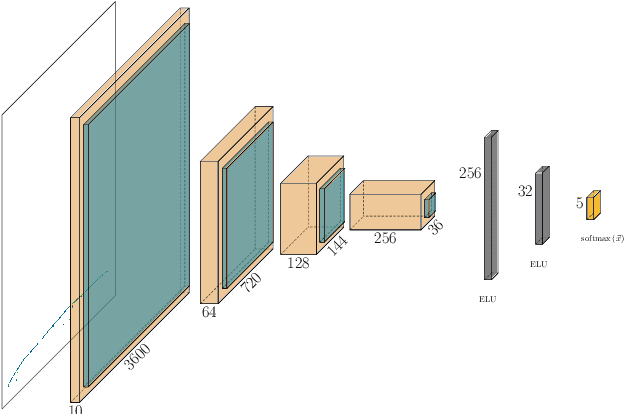
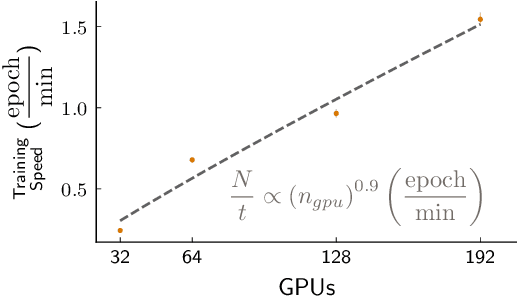
Measurements in Liquid Argon Time Projection Chamber (LArTPC) neutrino detectors, such as the MicroBooNE detector at Fermilab, feature large, high fidelity event images. Deep learning techniques have been extremely successful in classification tasks of photographs, but their application to LArTPC event images is challenging, due to the large size of the events. Events in these detectors are typically two orders of magnitude larger than images found in classical challenges, like recognition of handwritten digits contained in the MNIST database or object recognition in the ImageNet database. Ideally, training would occur on many instances of the entire event data, instead of many instances of cropped regions of interest from the event data. However, such efforts lead to extremely long training cycles, which slow down the exploration of new network architectures and hyperparameter scans to improve the classification performance. We present studies of scaling a LArTPC classification problem on multiple architectures, spanning multiple nodes. The studies are carried out on simulated events in the MicroBooNE detector. We emphasize that it is beyond the scope of this study to optimize networks or extract the physics from any results here. Institutional computing at Pacific Northwest National Laboratory and the SummitDev machine at Oak Ridge National Laboratory's Leadership Computing Facility have been used. To our knowledge, this is the first use of state-of-the-art Convolutional Neural Networks for particle physics and their attendant compute techniques onto the DOE Leadership Class Facilities. We expect benefits to accrue particularly to the Deep Underground Neutrino Experiment (DUNE) LArTPC program, the flagship US High Energy Physics (HEP) program for the coming decades.