 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Semantic Coreset with Orthogonal Projection Embeddings for Federated learning
Mar 13, 2026Scientific discovery increasingly requires learning on federated datasets, fed by streams from high-resolution instruments, that have extreme class imbalance. Current ML approaches either require impractical data aggregation or fail due to class imbalance. Existing coreset selection methods rely on local heuristics, making them unaware of the global data landscape and prone to sub-optimal and non-representative pruning. To overcome these challenges, we introduce SCOPE (Semantic Coreset using Orthogonal Projection Embeddings for Federated learning), a coreset framework for federated data that filters anomalies and adaptively prunes redundant data to mitigate long-tail skew. By analyzing the latent space distribution, we score each data point using a representation score that measures the reliability of core class features, a diversity score that quantifies the novelty of orthogonal residuals, and a boundary proximity score that indicates similarity to competing classes. Unlike prior methods, SCOPE shares only scalar metrics with a federated server to construct a global consensus, ensuring communication efficiency. Guided by the global consensus, SCOPE dynamically filters local noise and discards redundant samples to counteract global feature skews. Extensive experiments demonstrate that SCOPE yields competitive global accuracy and robust convergence, all while achieving exceptional efficiency with a 128x to 512x reduction in uplink bandwidth, a 7.72x wall-clock acceleration and reduced FLOP and VRAM footprints for local coreset selection.
SuperSAM: Crafting a SAM Supernetwork via Structured Pruning and Unstructured Parameter Prioritization
Jan 15, 2025



Neural Architecture Search (NAS) is a powerful approach of automating the design of efficient neural architectures. In contrast to traditional NAS methods, recently proposed one-shot NAS methods prove to be more efficient in performing NAS. One-shot NAS works by generating a singular weight-sharing supernetwork that acts as a search space (container) of subnetworks. Despite its achievements, designing the one-shot search space remains a major challenge. In this work we propose a search space design strategy for Vision Transformer (ViT)-based architectures. In particular, we convert the Segment Anything Model (SAM) into a weight-sharing supernetwork called SuperSAM. Our approach involves automating the search space design via layer-wise structured pruning and parameter prioritization. While the structured pruning applies probabilistic removal of certain transformer layers, parameter prioritization performs weight reordering and slicing of MLP-blocks in the remaining layers. We train supernetworks on several datasets using the sandwich rule. For deployment, we enhance subnetwork discovery by utilizing a program autotuner to identify efficient subnetworks within the search space. The resulting subnetworks are 30-70% smaller in size compared to the original pre-trained SAM ViT-B, yet outperform the pretrained model. Our work introduces a new and effective method for ViT NAS search-space design.
Final Report for CHESS: Cloud, High-Performance Computing, and Edge for Science and Security
Oct 21, 2024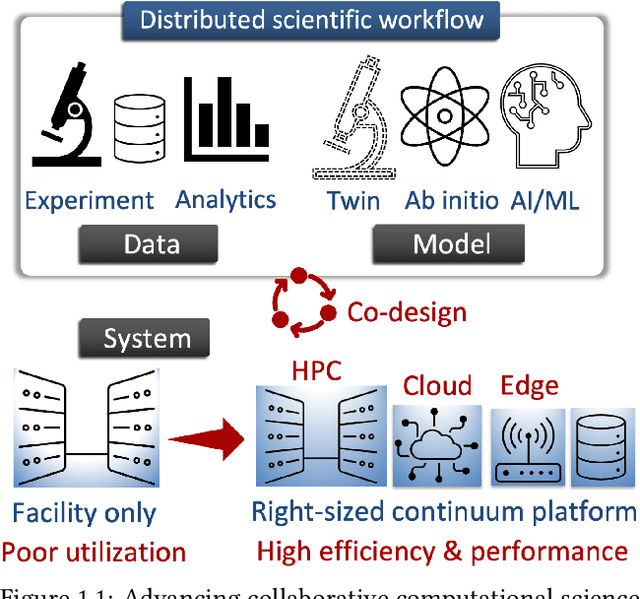
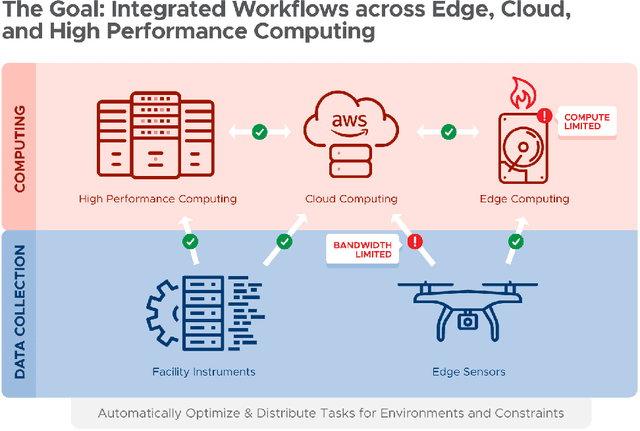
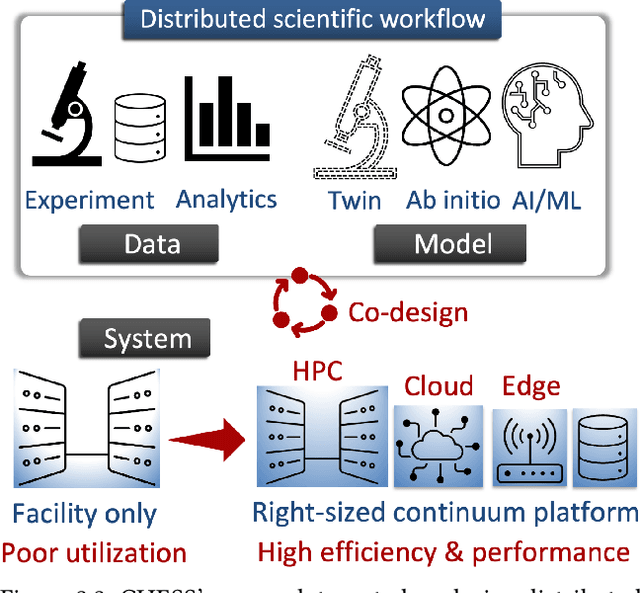

Automating the theory-experiment cycle requires effective distributed workflows that utilize a computing continuum spanning lab instruments, edge sensors, computing resources at multiple facilities, data sets distributed across multiple information sources, and potentially cloud. Unfortunately, the obvious methods for constructing continuum platforms, orchestrating workflow tasks, and curating datasets over time fail to achieve scientific requirements for performance, energy, security, and reliability. Furthermore, achieving the best use of continuum resources depends upon the efficient composition and execution of workflow tasks, i.e., combinations of numerical solvers, data analytics, and machine learning. Pacific Northwest National Laboratory's LDRD "Cloud, High-Performance Computing (HPC), and Edge for Science and Security" (CHESS) has developed a set of interrelated capabilities for enabling distributed scientific workflows and curating datasets. This report describes the results and successes of CHESS from the perspective of open science.
OPDR: Order-Preserving Dimension Reduction for Semantic Embedding of Multimodal Scientific Data
Aug 15, 2024



One of the most common operations in multimodal scientific data management is searching for the $k$ most similar items (or, $k$-nearest neighbors, KNN) from the database after being provided a new item. Although recent advances of multimodal machine learning models offer a \textit{semantic} index, the so-called \textit{embedding vectors} mapped from the original multimodal data, the dimension of the resulting embedding vectors are usually on the order of hundreds or a thousand, which are impractically high for time-sensitive scientific applications. This work proposes to reduce the dimensionality of the output embedding vectors such that the set of top-$k$ nearest neighbors do not change in the lower-dimensional space, namely Order-Preserving Dimension Reduction (OPDR). In order to develop such an OPDR method, our central hypothesis is that by analyzing the intrinsic relationship among key parameters during the dimension-reduction map, a quantitative function may be constructed to reveal the correlation between the target (lower) dimensionality and other variables. To demonstrate the hypothesis, this paper first defines a formal measure function to quantify the KNN similarity for a specific vector, then extends the measure into an aggregate accuracy of the global metric spaces, and finally derives a closed-form function between the target (lower) dimensionality and other variables. We incorporate the closed-function into popular dimension-reduction methods, various distance metrics, and embedding models.
SAM-I-Am: Semantic Boosting for Zero-shot Atomic-Scale Electron Micrograph Segmentation
Apr 09, 2024



Image segmentation is a critical enabler for tasks ranging from medical diagnostics to autonomous driving. However, the correct segmentation semantics - where are boundaries located? what segments are logically similar? - change depending on the domain, such that state-of-the-art foundation models can generate meaningless and incorrect results. Moreover, in certain domains, fine-tuning and retraining techniques are infeasible: obtaining labels is costly and time-consuming; domain images (micrographs) can be exponentially diverse; and data sharing (for third-party retraining) is restricted. To enable rapid adaptation of the best segmentation technology, we propose the concept of semantic boosting: given a zero-shot foundation model, guide its segmentation and adjust results to match domain expectations. We apply semantic boosting to the Segment Anything Model (SAM) to obtain microstructure segmentation for transmission electron microscopy. Our booster, SAM-I-Am, extracts geometric and textural features of various intermediate masks to perform mask removal and mask merging operations. We demonstrate a zero-shot performance increase of (absolute) +21.35%, +12.6%, +5.27% in mean IoU, and a -9.91%, -18.42%, -4.06% drop in mean false positive masks across images of three difficulty classes over vanilla SAM (ViT-L).
Im2win: An Efficient Convolution Paradigm on GPU
Jun 25, 2023



Convolution is the most time-consuming operation in deep neural network operations, so its performance is critical to the overall performance of the neural network. The commonly used methods for convolution on GPU include the general matrix multiplication (GEMM)-based convolution and the direct convolution. GEMM-based convolution relies on the im2col algorithm, which results in a large memory footprint and reduced performance. Direct convolution does not have the large memory footprint problem, but the performance is not on par with GEMM-based approach because of the discontinuous memory access. This paper proposes a window-order-based convolution paradigm on GPU, called im2win, which not only reduces memory footprint but also offers continuous memory accesses, resulting in improved performance. Furthermore, we apply a range of optimization techniques on the convolution CUDA kernel, including shared memory, tiling, micro-kernel, double buffer, and prefetching. We compare our implementation with the direct convolution, and PyTorch's GEMM-based convolution with cuBLAS and six cuDNN-based convolution implementations, with twelve state-of-the-art DNN benchmarks. The experimental results show that our implementation 1) uses less memory footprint by 23.1% and achieves 3.5$\times$ TFLOPS compared with cuBLAS, 2) uses less memory footprint by 32.8% and achieves up to 1.8$\times$ TFLOPS compared with the best performant convolutions in cuDNN, and 3) achieves up to 155$\times$ TFLOPS compared with the direct convolution. We further perform an ablation study on the applied optimization techniques and find that the micro-kernel has the greatest positive impact on performance.
Indoor Frame Recovery from Refined Line Segments
Apr 30, 2017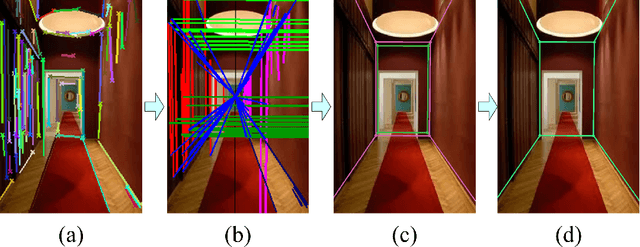
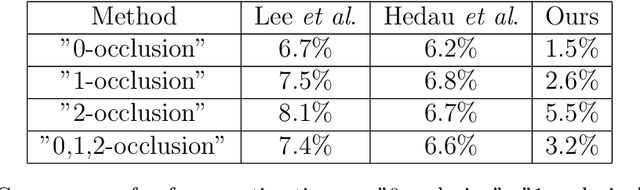
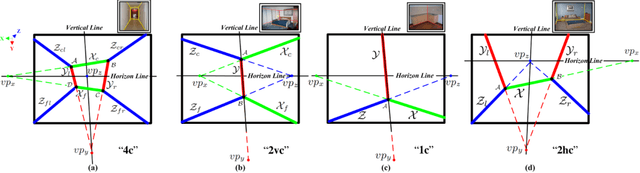
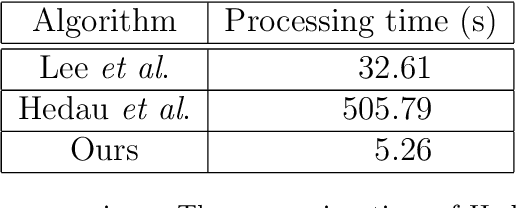
An important yet challenging problem in understanding indoor scene is recovering indoor frame structure from a monocular image. It is more difficult when occlusions and illumination vary, and object boundaries are weak. To overcome these difficulties, a new approach based on line segment refinement with two constraints is proposed. First, the line segments are refined by four consecutive operations, i.e., reclassifying, connecting, fitting, and voting. Specifically, misclassified line segments are revised by the reclassifying operation, some short line segments are joined by the connecting operation, the undetected key line segments are recovered by the fitting operation with the help of the vanishing points, the line segments converging on the frame are selected by the voting operation. Second, we construct four frame models according to four classes of possible shooting angles of the monocular image, the natures of all frame models are introduced via enforcing the cross ratio and depth constraints. The indoor frame is then constructed by fitting those refined line segments with related frame model under the two constraints, which jointly advance the accuracy of the frame. Experimental results on a collection of over 300 indoor images indicate that our algorithm has the capability of recovering the frame from complex indoor scenes.