 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIm2win: Memory Efficient Convolution On SIMD Architectures
Jun 25, 2023Convolution is the most expensive operation among neural network operations, thus its performance is critical to the overall performance of neural networks. Commonly used convolution approaches, including general matrix multiplication (GEMM)-based convolution and direct convolution, rely on im2col for data transformation or do not use data transformation at all, respectively. However, the im2col data transformation can lead to at least 2$\times$ memory footprint compared to not using data transformation at all, thus limiting the size of neural network models running on memory-limited systems. Meanwhile, not using data transformation usually performs poorly due to nonconsecutive memory access although it consumes less memory. To solve those problems, we propose a new memory-efficient data transformation algorithm, called im2win. This algorithm refactorizes a row of square or rectangle dot product windows of the input image and flattens unique elements within these windows into a row in the output tensor, which enables consecutive memory access and data reuse, and thus greatly reduces the memory overhead. Furthermore, we propose a high-performance im2win-based convolution algorithm with various optimizations, including vectorization, loop reordering, etc. Our experimental results show that our algorithm reduces the memory overhead by average to 41.6% compared to the PyTorch's convolution implementation based on im2col, and achieves average to 3.6$\times$ and 5.3$\times$ speedup in performance compared to the im2col-based convolution and not using data transformation, respectively.
* Published at "2022 IEEE High Performance Extreme Computing Conference (HPEC)"
Im2win: An Efficient Convolution Paradigm on GPU
Jun 25, 2023Convolution is the most time-consuming operation in deep neural network operations, so its performance is critical to the overall performance of the neural network. The commonly used methods for convolution on GPU include the general matrix multiplication (GEMM)-based convolution and the direct convolution. GEMM-based convolution relies on the im2col algorithm, which results in a large memory footprint and reduced performance. Direct convolution does not have the large memory footprint problem, but the performance is not on par with GEMM-based approach because of the discontinuous memory access. This paper proposes a window-order-based convolution paradigm on GPU, called im2win, which not only reduces memory footprint but also offers continuous memory accesses, resulting in improved performance. Furthermore, we apply a range of optimization techniques on the convolution CUDA kernel, including shared memory, tiling, micro-kernel, double buffer, and prefetching. We compare our implementation with the direct convolution, and PyTorch's GEMM-based convolution with cuBLAS and six cuDNN-based convolution implementations, with twelve state-of-the-art DNN benchmarks. The experimental results show that our implementation 1) uses less memory footprint by 23.1% and achieves 3.5$\times$ TFLOPS compared with cuBLAS, 2) uses less memory footprint by 32.8% and achieves up to 1.8$\times$ TFLOPS compared with the best performant convolutions in cuDNN, and 3) achieves up to 155$\times$ TFLOPS compared with the direct convolution. We further perform an ablation study on the applied optimization techniques and find that the micro-kernel has the greatest positive impact on performance.
Hybrid Feature Learning for Handwriting Verification
Nov 19, 2018
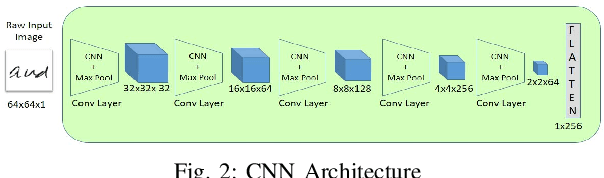
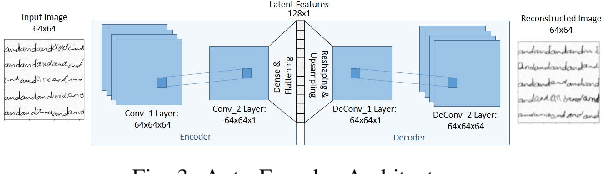
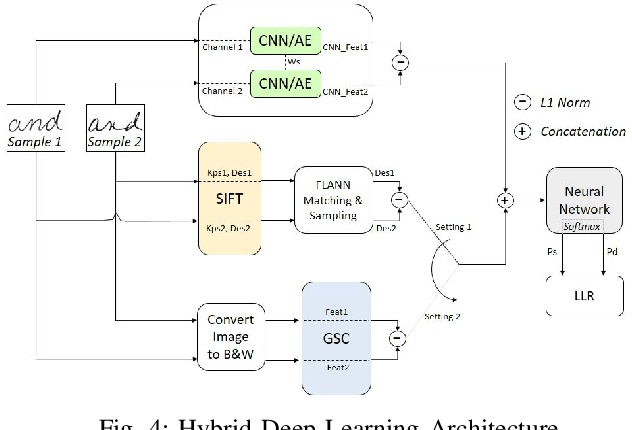
We propose an effective Hybrid Deep Learning (HDL) architecture for the task of determining the probability that a questioned handwritten word has been written by a known writer. HDL is an amalgamation of Auto-Learned Features (ALF) and Human-Engineered Features (HEF). To extract auto-learned features we use two methods: First, Two Channel Convolutional Neural Network (TC-CNN); Second, Two Channel Autoencoder (TC-AE). Furthermore, human-engineered features are extracted by using two methods: First, Gradient Structural Concavity (GSC); Second, Scale Invariant Feature Transform (SIFT). Experiments are performed by complementing one of the HEF methods with one ALF method on 150000 pairs of samples of the word "AND" cropped from handwritten notes written by 1500 writers. Our results indicate that HDL architecture with AE-GSC achieves 99.7% accuracy on seen writer dataset and 92.16% accuracy on shuffled writer dataset which out performs CEDAR-FOX, as for unseen writer dataset, AE-SIFT performs comparable to this sophisticated handwriting comparison tool.
Indoor Frame Recovery from Refined Line Segments
Apr 30, 2017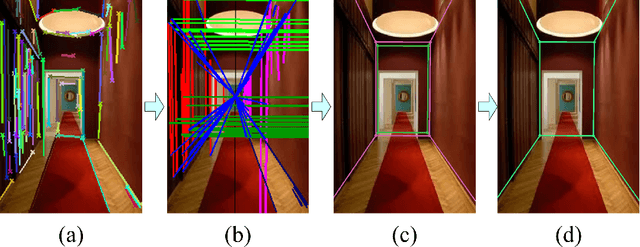
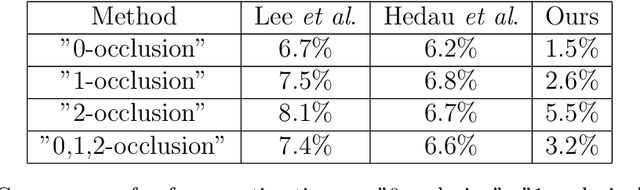
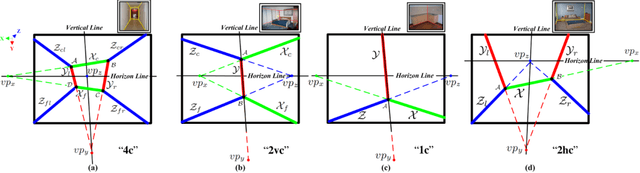
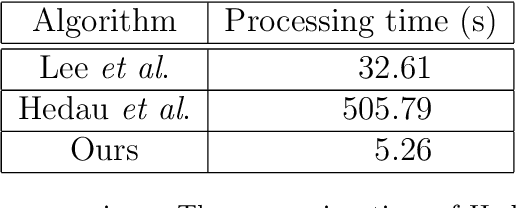
An important yet challenging problem in understanding indoor scene is recovering indoor frame structure from a monocular image. It is more difficult when occlusions and illumination vary, and object boundaries are weak. To overcome these difficulties, a new approach based on line segment refinement with two constraints is proposed. First, the line segments are refined by four consecutive operations, i.e., reclassifying, connecting, fitting, and voting. Specifically, misclassified line segments are revised by the reclassifying operation, some short line segments are joined by the connecting operation, the undetected key line segments are recovered by the fitting operation with the help of the vanishing points, the line segments converging on the frame are selected by the voting operation. Second, we construct four frame models according to four classes of possible shooting angles of the monocular image, the natures of all frame models are introduced via enforcing the cross ratio and depth constraints. The indoor frame is then constructed by fitting those refined line segments with related frame model under the two constraints, which jointly advance the accuracy of the frame. Experimental results on a collection of over 300 indoor images indicate that our algorithm has the capability of recovering the frame from complex indoor scenes.