 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model Based Handwriting Verification
Jul 31, 2024

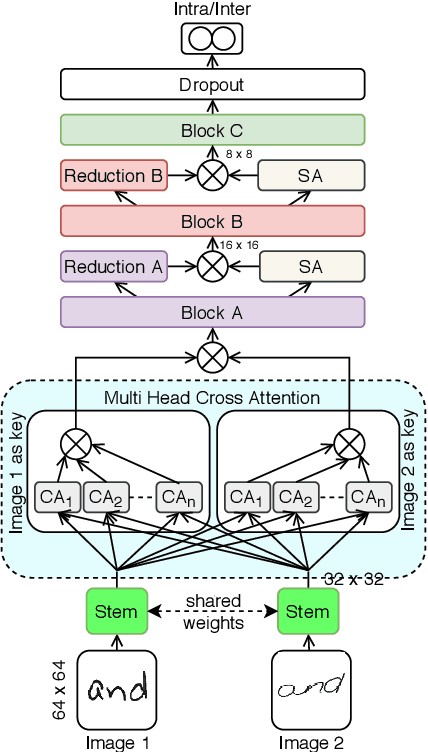
Handwriting Verification is a critical in document forensics. Deep learning based approaches often face skepticism from forensic document examiners due to their lack of explainability and reliance on extensive training data and handcrafted features. This paper explores using Vision Language Models (VLMs), such as OpenAI's GPT-4o and Google's PaliGemma, to address these challenges. By leveraging their Visual Question Answering capabilities and 0-shot Chain-of-Thought (CoT) reasoning, our goal is to provide clear, human-understandable explanations for model decisions. Our experiments on the CEDAR handwriting dataset demonstrate that VLMs offer enhanced interpretability, reduce the need for large training datasets, and adapt better to diverse handwriting styles. However, results show that the CNN-based ResNet-18 architecture outperforms the 0-shot CoT prompt engineering approach with GPT-4o (Accuracy: 70%) and supervised fine-tuned PaliGemma (Accuracy: 71%), achieving an accuracy of 84% on the CEDAR AND dataset. These findings highlight the potential of VLMs in generating human-interpretable decisions while underscoring the need for further advancements to match the performance of specialized deep learning models.
Self-Supervised Learning Based Handwriting Verification
May 28, 2024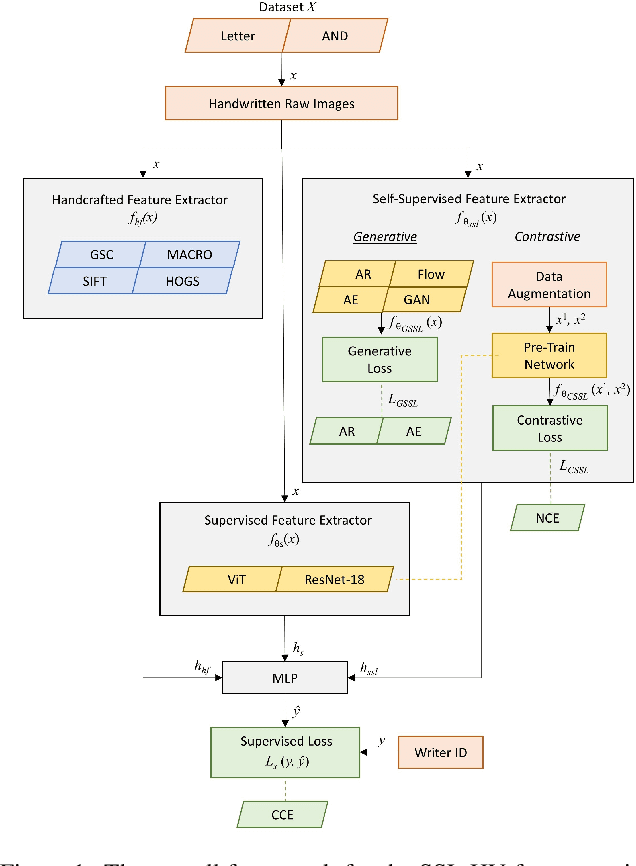
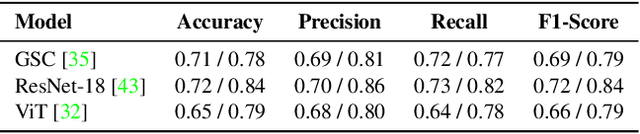
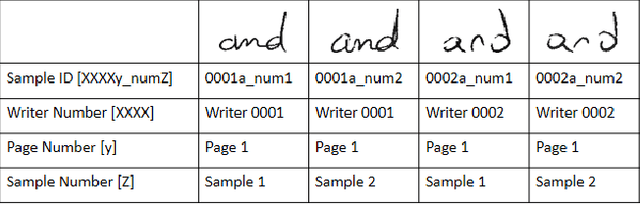

We present SSL-HV: Self-Supervised Learning approaches applied to the task of Handwriting Verification. This task involves determining whether a given pair of handwritten images originate from the same or different writer distribution. We have compared the performance of multiple generative, contrastive SSL approaches against handcrafted feature extractors and supervised learning on CEDAR AND dataset. We show that ResNet based Variational Auto-Encoder (VAE) outperforms other generative approaches achieving 76.3% accuracy, while ResNet-18 fine-tuned using Variance-Invariance-Covariance Regularization (VICReg) outperforms other contrastive approaches achieving 78% accuracy. Using a pre-trained VAE and VICReg for the downstream task of writer verification we observed a relative improvement in accuracy of 6.7% and 9% over ResNet-18 supervised baseline with 10% writer labels.
Improving Joint Learning of Chest X-Ray and Radiology Report by Word Region Alignment
Sep 04, 2021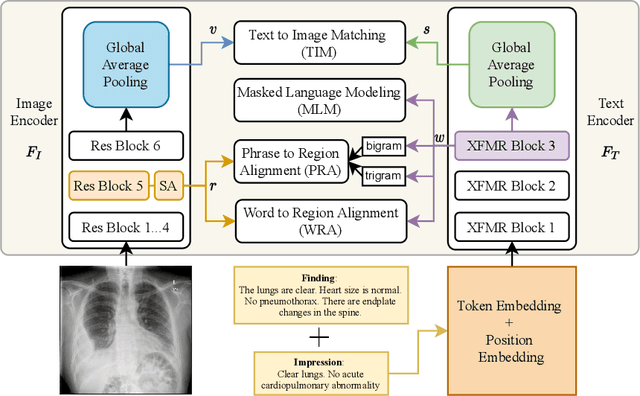
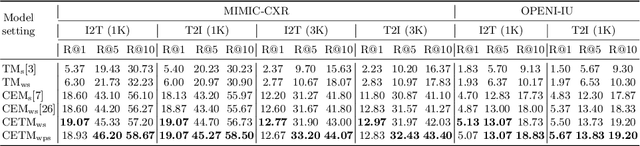
Self-supervised learning provides an opportunity to explore unlabeled chest X-rays and their associated free-text reports accumulated in clinical routine without manual supervision. This paper proposes a Joint Image Text Representation Learning Network (JoImTeRNet) for pre-training on chest X-ray images and their radiology reports. The model was pre-trained on both the global image-sentence level and the local image region-word level for visual-textual matching. Both are bidirectionally constrained on Cross-Entropy based and ranking-based Triplet Matching Losses. The region-word matching is calculated using the attention mechanism without direct supervision about their mapping. The pre-trained multi-modal representation learning paves the way for downstream tasks concerning image and/or text encoding. We demonstrate the representation learning quality by cross-modality retrievals and multi-label classifications on two datasets: OpenI-IU and MIMIC-CXR
LAViTeR: Learning Aligned Visual and Textual Representations Assisted by Image and Caption Generation
Sep 04, 2021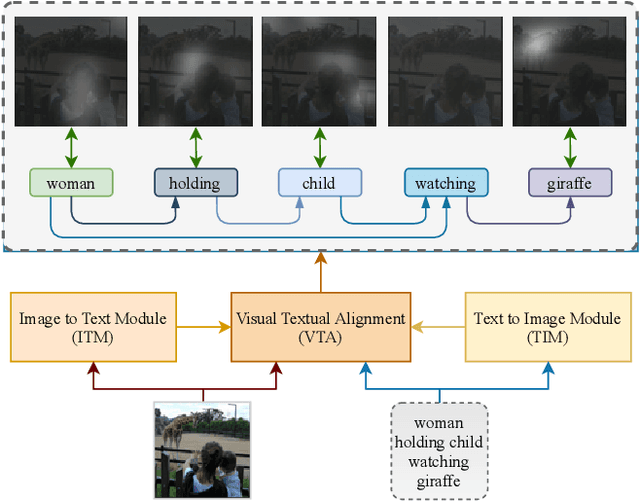
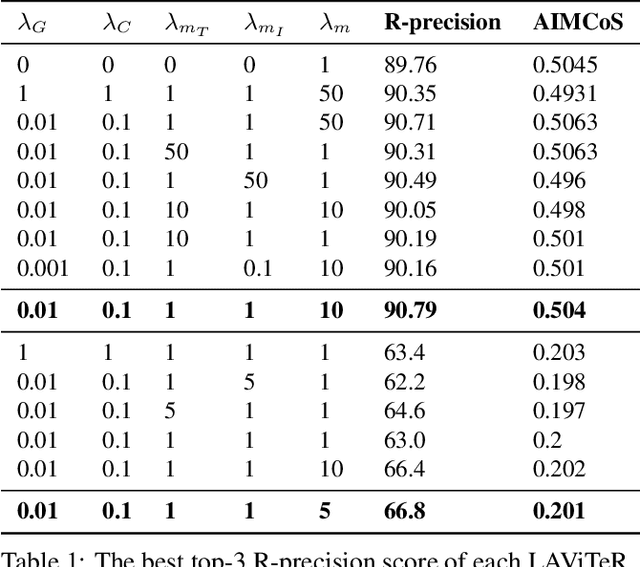
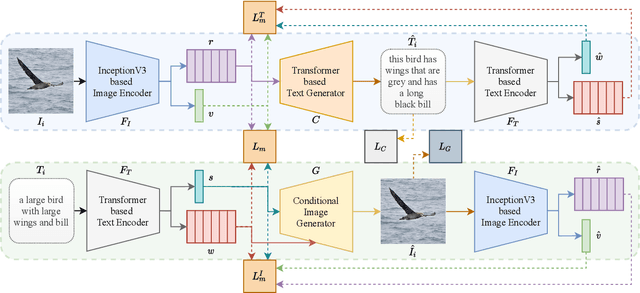
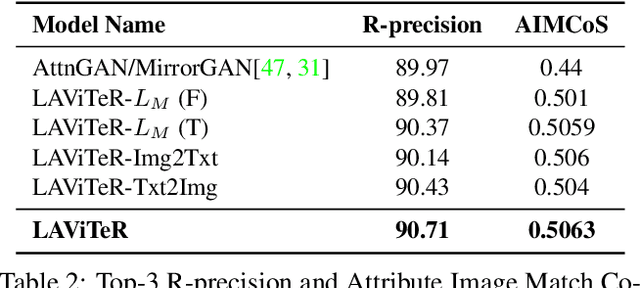
Pre-training visual and textual representations from large-scale image-text pairs is becoming a standard approach for many downstream vision-language tasks. The transformer-based models learn inter and intra-modal attention through a list of self-supervised learning tasks. This paper proposes LAViTeR, a novel architecture for visual and textual representation learning. The main module, Visual Textual Alignment (VTA) will be assisted by two auxiliary tasks, GAN-based image synthesis and Image Captioning. We also propose a new evaluation metric measuring the similarity between the learnt visual and textual embedding. The experimental results on two public datasets, CUB and MS-COCO, demonstrate superior visual and textual representation alignment in the joint feature embedding space
Attention based Writer Independent Handwriting Verification
Oct 01, 2020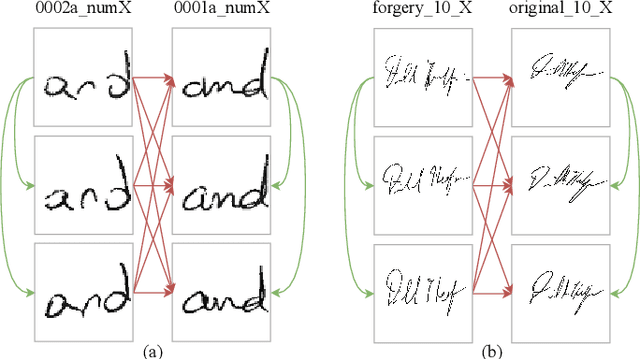
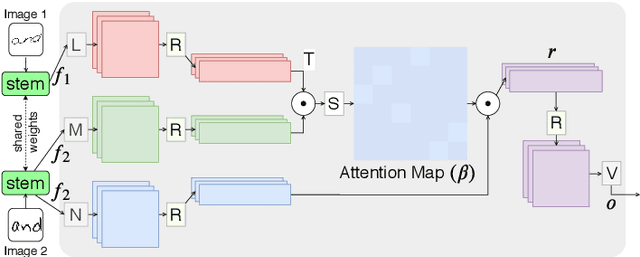
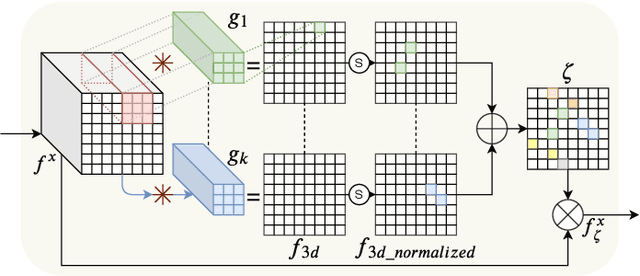
The task of writer verification is to provide a likelihood score for whether the queried and known handwritten image samples belong to the same writer or not. Such a task calls for the neural network to make it's outcome interpretable, i.e. provide a view into the network's decision making process. We implement and integrate cross-attention and soft-attention mechanisms to capture the highly correlated and salient points in feature space of 2D inputs. The attention maps serve as an explanation premise for the network's output likelihood score. The attention mechanism also allows the network to focus more on relevant areas of the input, thus improving the classification performance. Our proposed approach achieves a precision of 86\% for detecting intra-writer cases in CEDAR cursive "AND" dataset. Furthermore, we generate meaningful explanations for the provided decision by extracting attention maps from multiple levels of the network.
Ultra Efficient Transfer Learning with Meta Update for Cross Subject EEG Classification
Mar 13, 2020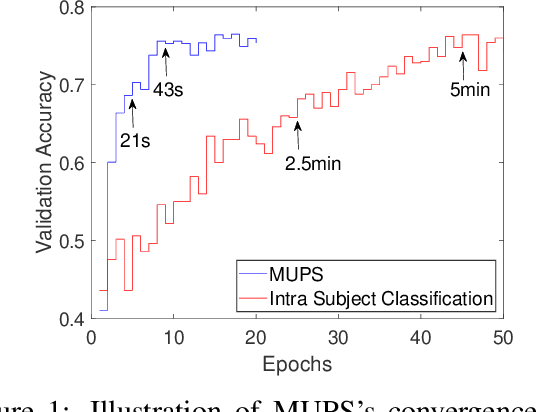
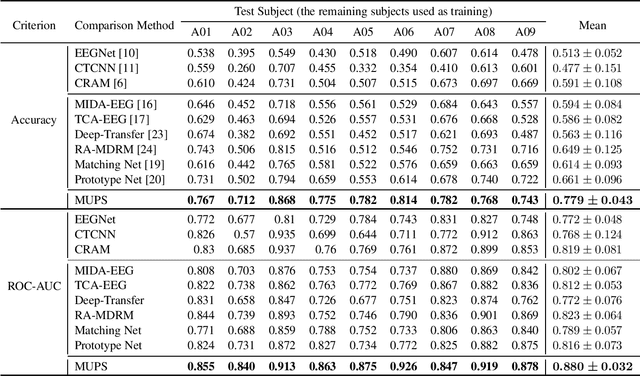
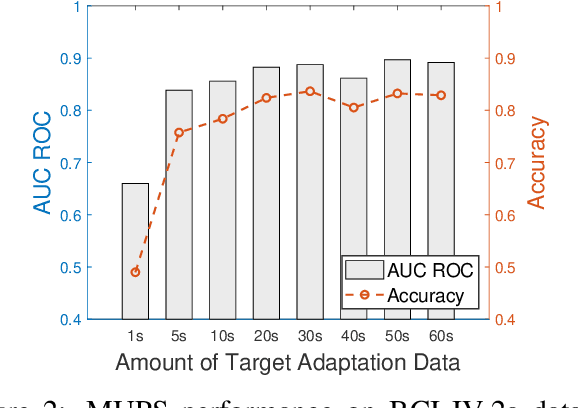
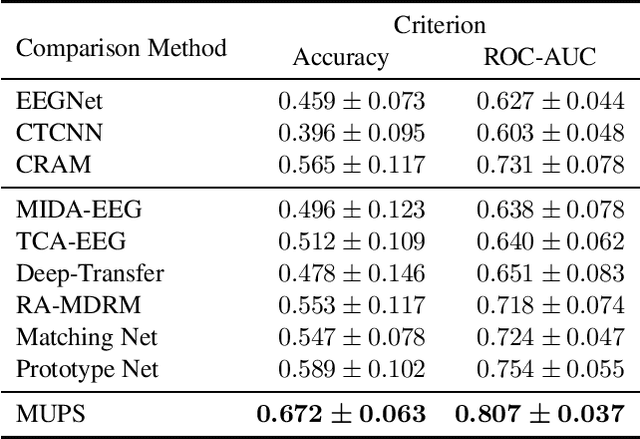
Electroencephalogram (EEG) signal is widely used in brain computer interfaces (BCI), the pattern of which differs significantly across different subjects, and poses a major challenge for real world application of EEG classifiers. We found an efficient transfer learning method, named Meta UPdate Strategy (MUPS), boosts cross subject classification performance of EEG signals, and only need a small amount of data from target subject. The model tackles the problem with a two step process: (1) extract versatile features that are effective across all source subjects, and (2) adapt the model to target subject. The proposed model, which originates from meta learning, aims to find feature representation that is broadly suitable for different subjects, and maximizes sensitivity of the loss function on new subject such that one or a small number of gradient steps can lead to effective adaptation. The method can be applied to all deep learning oriented models. We performed extensive experiments on two public datasets, the proposed MUPS model outperforms current state of the arts by a large margin on accuracy and AUC-ROC when only a small amount of target data is used.
Hybrid Feature Learning for Handwriting Verification
Nov 19, 2018
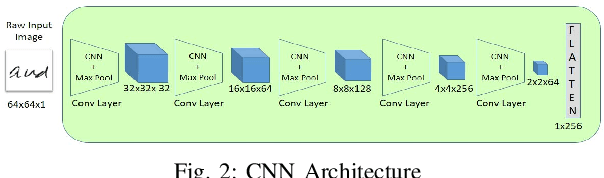
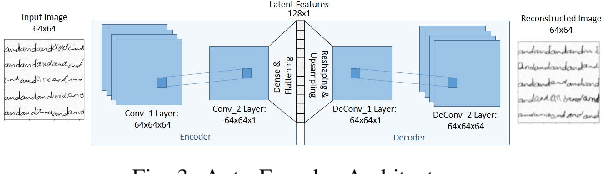
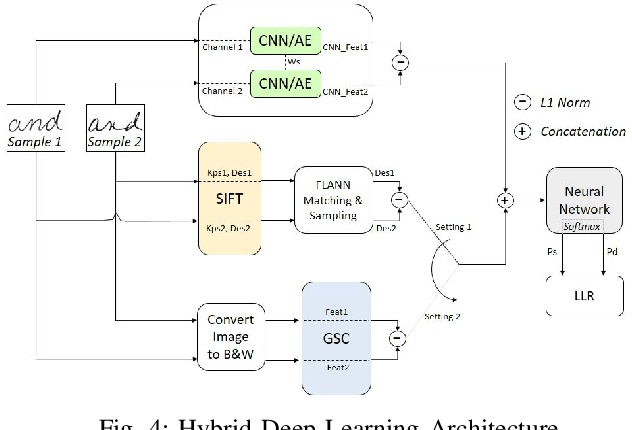
We propose an effective Hybrid Deep Learning (HDL) architecture for the task of determining the probability that a questioned handwritten word has been written by a known writer. HDL is an amalgamation of Auto-Learned Features (ALF) and Human-Engineered Features (HEF). To extract auto-learned features we use two methods: First, Two Channel Convolutional Neural Network (TC-CNN); Second, Two Channel Autoencoder (TC-AE). Furthermore, human-engineered features are extracted by using two methods: First, Gradient Structural Concavity (GSC); Second, Scale Invariant Feature Transform (SIFT). Experiments are performed by complementing one of the HEF methods with one ALF method on 150000 pairs of samples of the word "AND" cropped from handwritten notes written by 1500 writers. Our results indicate that HDL architecture with AE-GSC achieves 99.7% accuracy on seen writer dataset and 92.16% accuracy on shuffled writer dataset which out performs CEDAR-FOX, as for unseen writer dataset, AE-SIFT performs comparable to this sophisticated handwriting comparison tool.
Using Social Dynamics to Make Individual Predictions: Variational Inference with a Stochastic Kinetic Model
Nov 07, 2016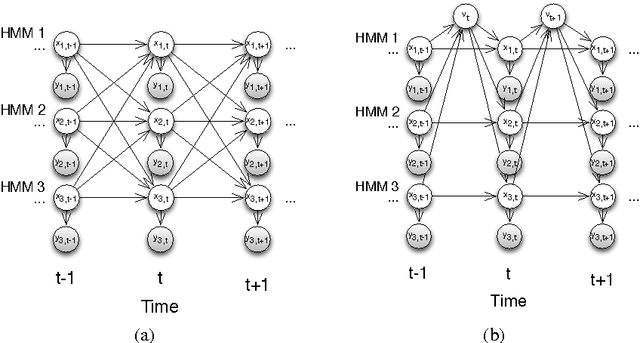
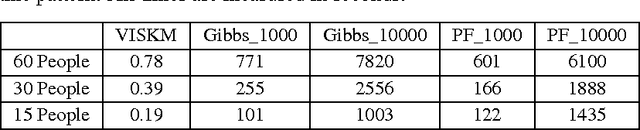
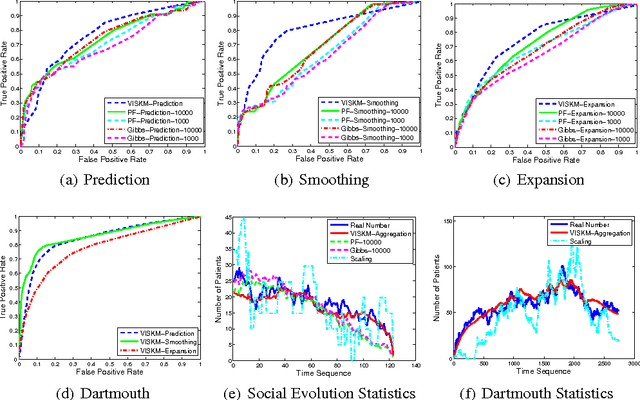
Social dynamics is concerned primarily with interactions among individuals and the resulting group behaviors, modeling the temporal evolution of social systems via the interactions of individuals within these systems. In particular, the availability of large-scale data from social networks and sensor networks offers an unprecedented opportunity to predict state-changing events at the individual level. Examples of such events include disease transmission, opinion transition in elections, and rumor propagation. Unlike previous research focusing on the collective effects of social systems, this study makes efficient inferences at the individual level. In order to cope with dynamic interactions among a large number of individuals, we introduce the stochastic kinetic model to capture adaptive transition probabilities and propose an efficient variational inference algorithm the complexity of which grows linearly --- rather than exponentially --- with the number of individuals. To validate this method, we have performed epidemic-dynamics experiments on wireless sensor network data collected from more than ten thousand people over three years. The proposed algorithm was used to track disease transmission and predict the probability of infection for each individual. Our results demonstrate that this method is more efficient than sampling while nonetheless achieving high accuracy.
Sequential Labeling with online Deep Learning
May 04, 2015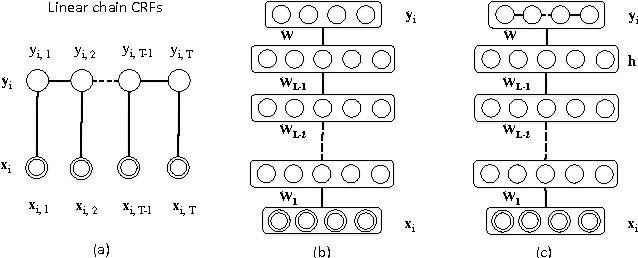
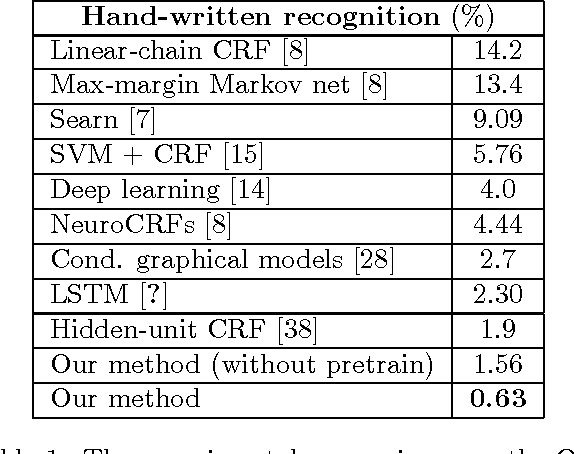


Deep learning has attracted great attention recently and yielded the state of the art performance in dimension reduction and classification problems. However, it cannot effectively handle the structured output prediction, e.g. sequential labeling. In this paper, we propose a deep learning structure, which can learn discriminative features for sequential labeling problems. More specifically, we add the inter-relationship between labels in our deep learning structure, in order to incorporate the context information from the sequential data. Thus, our model is more powerful than linear Conditional Random Fields (CRFs) because the objective function learns latent non-linear features so that target labeling can be better predicted. We pretrain the deep structure with stacked restricted Boltzmann machines (RBMs) for feature learning and optimize our objective function with online learning algorithm, a mixture of perceptron training and stochastic gradient descent. We test our model on different challenge tasks, and show that our model outperforms significantly over the completive baselines.