 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model Based Handwriting Verification
Jul 31, 2024

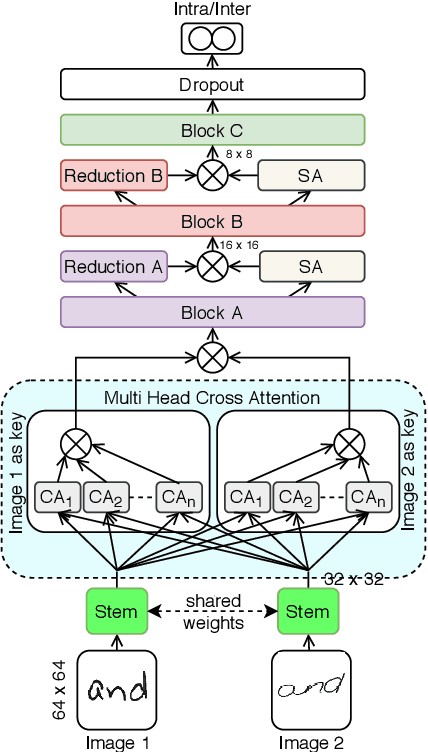
Handwriting Verification is a critical in document forensics. Deep learning based approaches often face skepticism from forensic document examiners due to their lack of explainability and reliance on extensive training data and handcrafted features. This paper explores using Vision Language Models (VLMs), such as OpenAI's GPT-4o and Google's PaliGemma, to address these challenges. By leveraging their Visual Question Answering capabilities and 0-shot Chain-of-Thought (CoT) reasoning, our goal is to provide clear, human-understandable explanations for model decisions. Our experiments on the CEDAR handwriting dataset demonstrate that VLMs offer enhanced interpretability, reduce the need for large training datasets, and adapt better to diverse handwriting styles. However, results show that the CNN-based ResNet-18 architecture outperforms the 0-shot CoT prompt engineering approach with GPT-4o (Accuracy: 70%) and supervised fine-tuned PaliGemma (Accuracy: 71%), achieving an accuracy of 84% on the CEDAR AND dataset. These findings highlight the potential of VLMs in generating human-interpretable decisions while underscoring the need for further advancements to match the performance of specialized deep learning models.
Self-Supervised Learning Based Handwriting Verification
May 28, 2024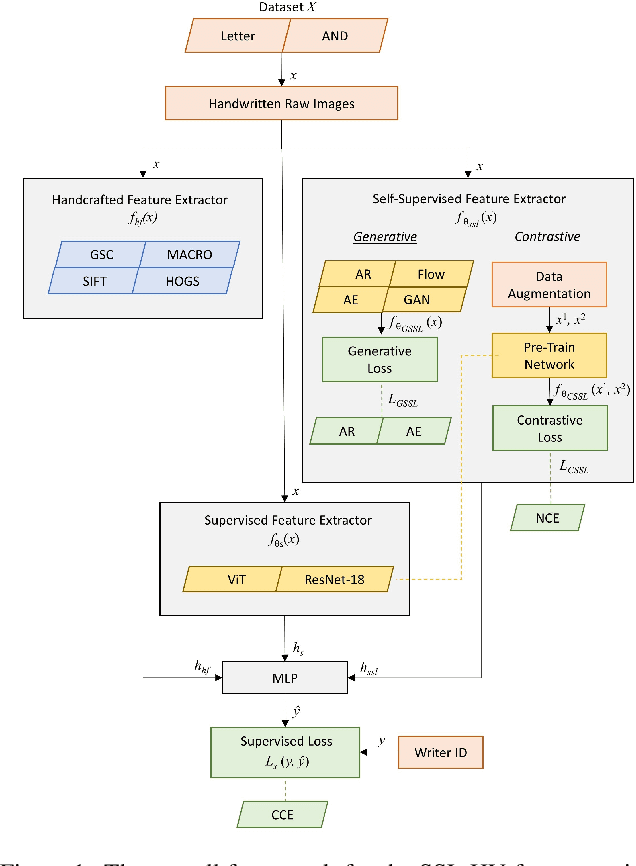
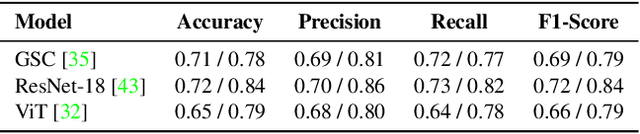

We present SSL-HV: Self-Supervised Learning approaches applied to the task of Handwriting Verification. This task involves determining whether a given pair of handwritten images originate from the same or different writer distribution. We have compared the performance of multiple generative, contrastive SSL approaches against handcrafted feature extractors and supervised learning on CEDAR AND dataset. We show that ResNet based Variational Auto-Encoder (VAE) outperforms other generative approaches achieving 76.3% accuracy, while ResNet-18 fine-tuned using Variance-Invariance-Covariance Regularization (VICReg) outperforms other contrastive approaches achieving 78% accuracy. Using a pre-trained VAE and VICReg for the downstream task of writer verification we observed a relative improvement in accuracy of 6.7% and 9% over ResNet-18 supervised baseline with 10% writer labels.
Attention based Writer Independent Handwriting Verification
Oct 01, 2020
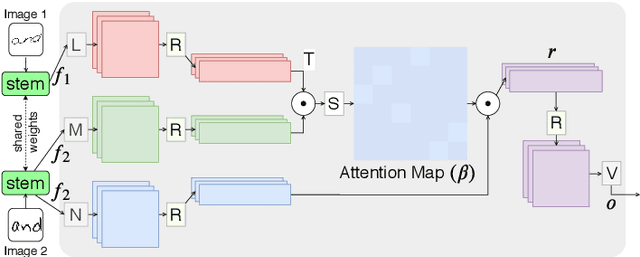
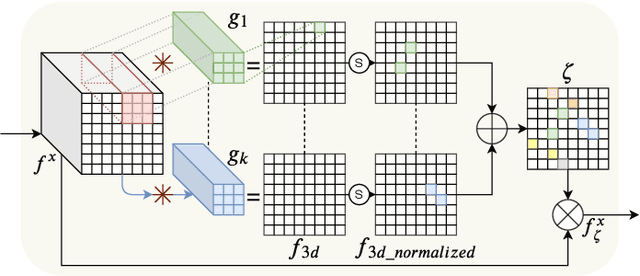
The task of writer verification is to provide a likelihood score for whether the queried and known handwritten image samples belong to the same writer or not. Such a task calls for the neural network to make it's outcome interpretable, i.e. provide a view into the network's decision making process. We implement and integrate cross-attention and soft-attention mechanisms to capture the highly correlated and salient points in feature space of 2D inputs. The attention maps serve as an explanation premise for the network's output likelihood score. The attention mechanism also allows the network to focus more on relevant areas of the input, thus improving the classification performance. Our proposed approach achieves a precision of 86\% for detecting intra-writer cases in CEDAR cursive "AND" dataset. Furthermore, we generate meaningful explanations for the provided decision by extracting attention maps from multiple levels of the network.
Ultra Efficient Transfer Learning with Meta Update for Cross Subject EEG Classification
Mar 13, 2020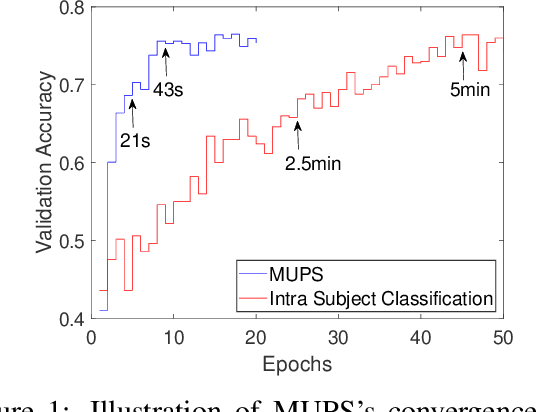
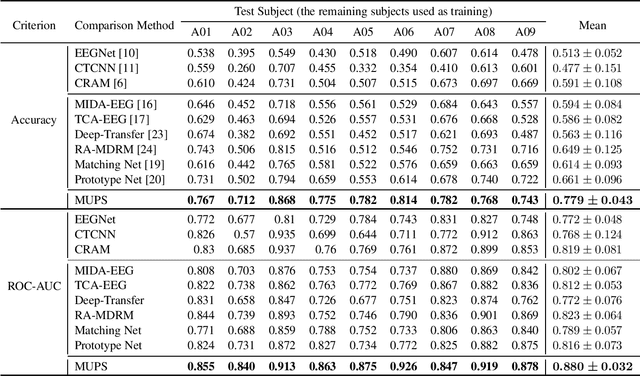
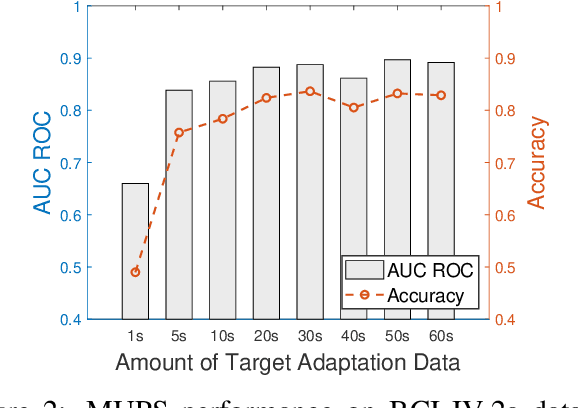
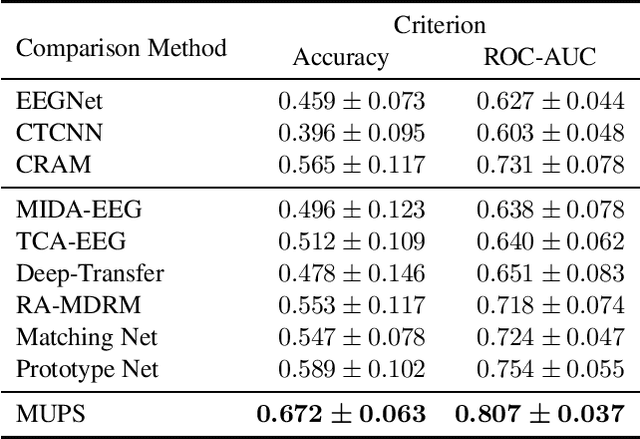
Electroencephalogram (EEG) signal is widely used in brain computer interfaces (BCI), the pattern of which differs significantly across different subjects, and poses a major challenge for real world application of EEG classifiers. We found an efficient transfer learning method, named Meta UPdate Strategy (MUPS), boosts cross subject classification performance of EEG signals, and only need a small amount of data from target subject. The model tackles the problem with a two step process: (1) extract versatile features that are effective across all source subjects, and (2) adapt the model to target subject. The proposed model, which originates from meta learning, aims to find feature representation that is broadly suitable for different subjects, and maximizes sensitivity of the loss function on new subject such that one or a small number of gradient steps can lead to effective adaptation. The method can be applied to all deep learning oriented models. We performed extensive experiments on two public datasets, the proposed MUPS model outperforms current state of the arts by a large margin on accuracy and AUC-ROC when only a small amount of target data is used.
Explanation based Handwriting Verification
Aug 14, 2019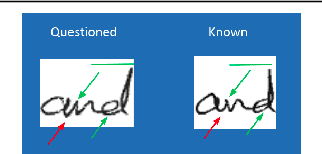
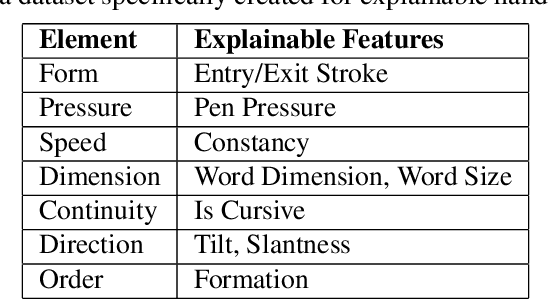
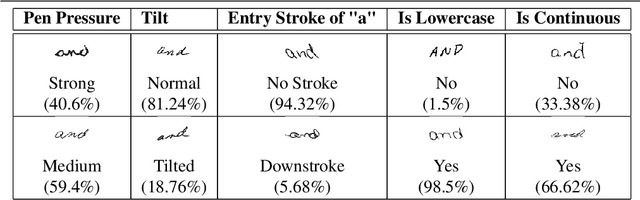
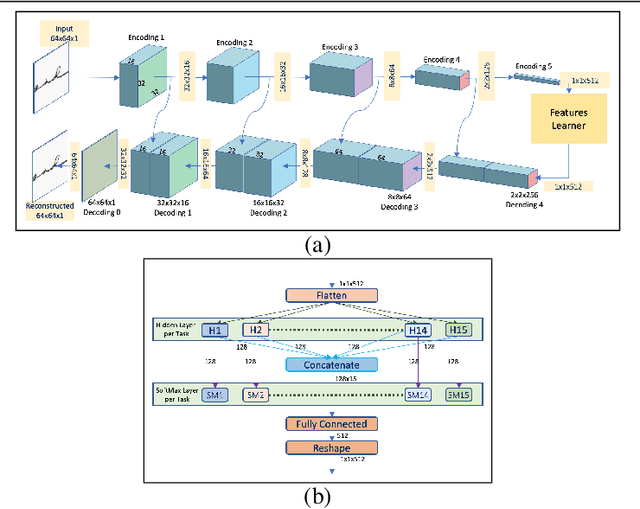
Deep learning system have drawback that their output is not accompanied with ex-planation. In a domain such as forensic handwriting verification it is essential to provideexplanation to jurors. The goal of handwriting verification is to find a measure of confi-dence whether the given handwritten samples are written by the same or different writer.We propose a method to generate explanations for the confidence provided by convolu-tional neural network (CNN) which maps the input image to 15 annotations (features)provided by experts. Our system comprises of: (1) Feature learning network (FLN),a differentiable system, (2) Inference module for providing explanations. Furthermore,inference module provides two types of explanations: (a) Based on cosine similaritybetween categorical probabilities of each feature, (b) Based on Log-Likelihood Ratio(LLR) using directed probabilistic graphical model. We perform experiments using acombination of feature learning network (FLN) and each inference module. We evaluateour system using XAI-AND dataset, containing 13700 handwritten samples and 15 cor-responding expert examined features for each sample. The dataset is released for publicuse and the methods can be extended to provide explanations on other verification taskslike face verification and bio-medical comparison. This dataset can serve as the basis and benchmark for future research in explanation based handwriting verification. The code is available on github.
Hybrid Feature Learning for Handwriting Verification
Nov 19, 2018
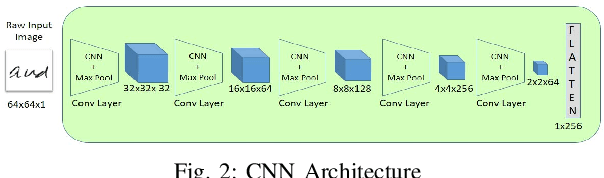
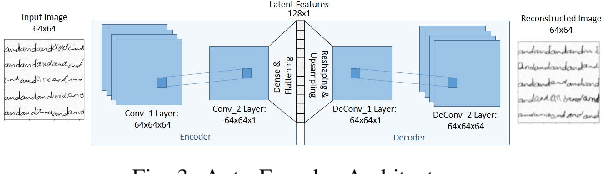
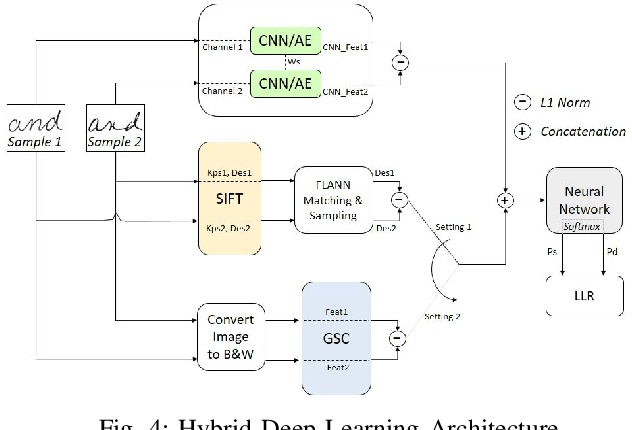
We propose an effective Hybrid Deep Learning (HDL) architecture for the task of determining the probability that a questioned handwritten word has been written by a known writer. HDL is an amalgamation of Auto-Learned Features (ALF) and Human-Engineered Features (HEF). To extract auto-learned features we use two methods: First, Two Channel Convolutional Neural Network (TC-CNN); Second, Two Channel Autoencoder (TC-AE). Furthermore, human-engineered features are extracted by using two methods: First, Gradient Structural Concavity (GSC); Second, Scale Invariant Feature Transform (SIFT). Experiments are performed by complementing one of the HEF methods with one ALF method on 150000 pairs of samples of the word "AND" cropped from handwritten notes written by 1500 writers. Our results indicate that HDL architecture with AE-GSC achieves 99.7% accuracy on seen writer dataset and 92.16% accuracy on shuffled writer dataset which out performs CEDAR-FOX, as for unseen writer dataset, AE-SIFT performs comparable to this sophisticated handwriting comparison tool.