 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model Based Handwriting Verification
Jul 31, 2024

Handwriting Verification is a critical in document forensics. Deep learning based approaches often face skepticism from forensic document examiners due to their lack of explainability and reliance on extensive training data and handcrafted features. This paper explores using Vision Language Models (VLMs), such as OpenAI's GPT-4o and Google's PaliGemma, to address these challenges. By leveraging their Visual Question Answering capabilities and 0-shot Chain-of-Thought (CoT) reasoning, our goal is to provide clear, human-understandable explanations for model decisions. Our experiments on the CEDAR handwriting dataset demonstrate that VLMs offer enhanced interpretability, reduce the need for large training datasets, and adapt better to diverse handwriting styles. However, results show that the CNN-based ResNet-18 architecture outperforms the 0-shot CoT prompt engineering approach with GPT-4o (Accuracy: 70%) and supervised fine-tuned PaliGemma (Accuracy: 71%), achieving an accuracy of 84% on the CEDAR AND dataset. These findings highlight the potential of VLMs in generating human-interpretable decisions while underscoring the need for further advancements to match the performance of specialized deep learning models.
Self-Supervised Learning Based Handwriting Verification
May 28, 2024
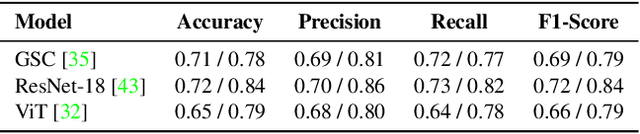

We present SSL-HV: Self-Supervised Learning approaches applied to the task of Handwriting Verification. This task involves determining whether a given pair of handwritten images originate from the same or different writer distribution. We have compared the performance of multiple generative, contrastive SSL approaches against handcrafted feature extractors and supervised learning on CEDAR AND dataset. We show that ResNet based Variational Auto-Encoder (VAE) outperforms other generative approaches achieving 76.3% accuracy, while ResNet-18 fine-tuned using Variance-Invariance-Covariance Regularization (VICReg) outperforms other contrastive approaches achieving 78% accuracy. Using a pre-trained VAE and VICReg for the downstream task of writer verification we observed a relative improvement in accuracy of 6.7% and 9% over ResNet-18 supervised baseline with 10% writer labels.