 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Detection in EEG Neural Decoding Models
Dec 28, 2021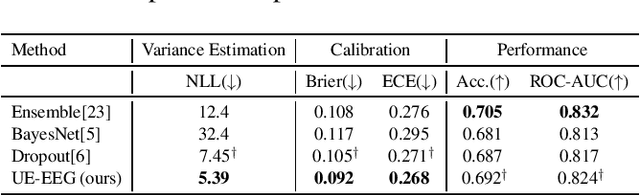

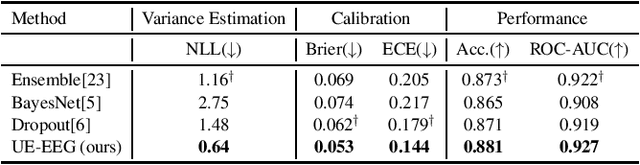
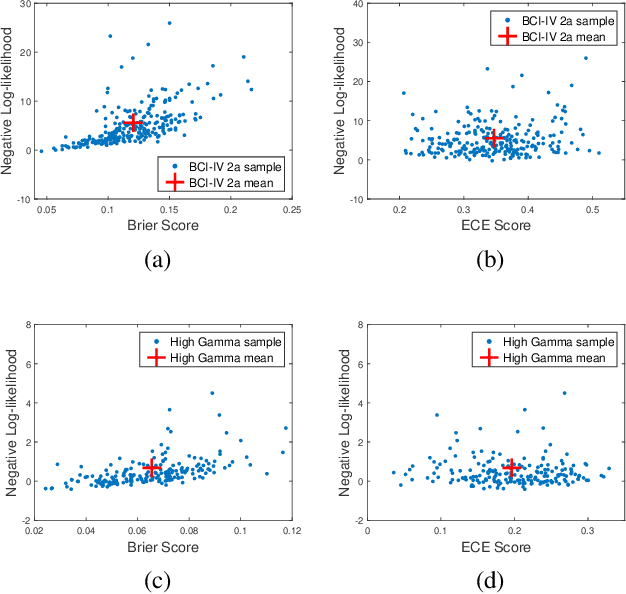
EEG decoding systems based on deep neural networks have been widely used in decision making of brain computer interfaces (BCI). Their predictions, however, can be unreliable given the significant variance and noise in EEG signals. Previous works on EEG analysis mainly focus on the exploration of noise pattern in the source signal, while the uncertainty during the decoding process is largely unexplored. Automatically detecting and quantifying such decoding uncertainty is important for BCI motor imagery applications such as robotic arm control etc. In this work, we proposed an uncertainty estimation model (UE-EEG) to explore the uncertainty during the EEG decoding process, which considers both the uncertainty in the input signal and the uncertainty in the model. The model utilized dropout oriented method for model uncertainty estimation, and Bayesian neural network is adopted for modeling the uncertainty of input data. The model can be integrated into current widely used deep learning classifiers without change of architecture. We performed extensive experiments for uncertainty estimation in both intra-subject EEG decoding and cross-subject EEG decoding on two public motor imagery datasets, where the proposed model achieves significant improvement on the quality of estimated uncertainty and demonstrates the proposed UE-EEG is a useful tool for BCI applications.
Soft-Attention Improves Skin Cancer Classification Performance
May 10, 2021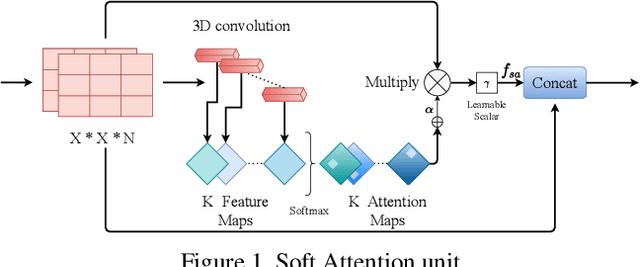
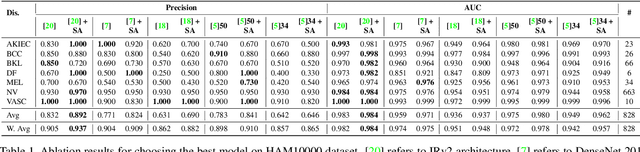
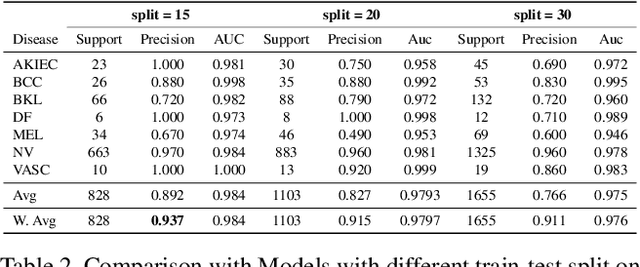
In clinical applications, neural networks must focus on and highlight the most important parts of an input image. Soft-Attention mechanism enables a neural network toachieve this goal. This paper investigates the effectiveness of Soft-Attention in deep neural architectures. The central aim of Soft-Attention is to boost the value of important features and suppress the noise-inducing features. We compare the performance of VGG, ResNet, InceptionResNetv2 and DenseNet architectures with and without the Soft-Attention mechanism, while classifying skin lesions. The original network when coupled with Soft-Attention outperforms the baseline[14] by 4.7% while achieving a precision of 93.7% on HAM10000 dataset. Additionally, Soft-Attention coupling improves the sensitivity score by 3.8% compared to baseline[28] and achieves 91.6% on ISIC-2017 dataset. The code is publicly available at github.
Explanation based Handwriting Verification
Aug 14, 2019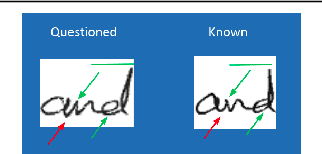
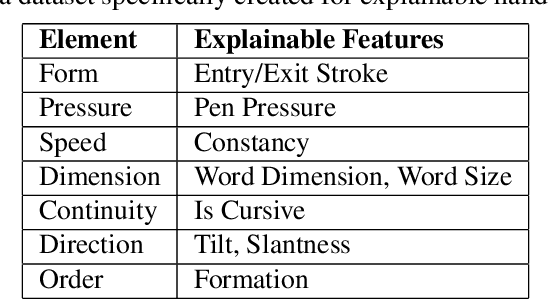
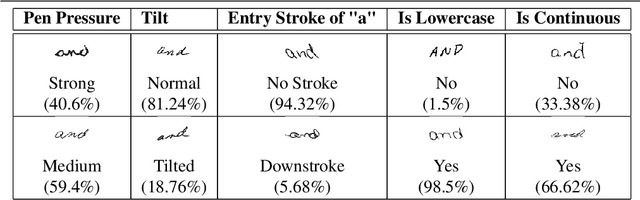
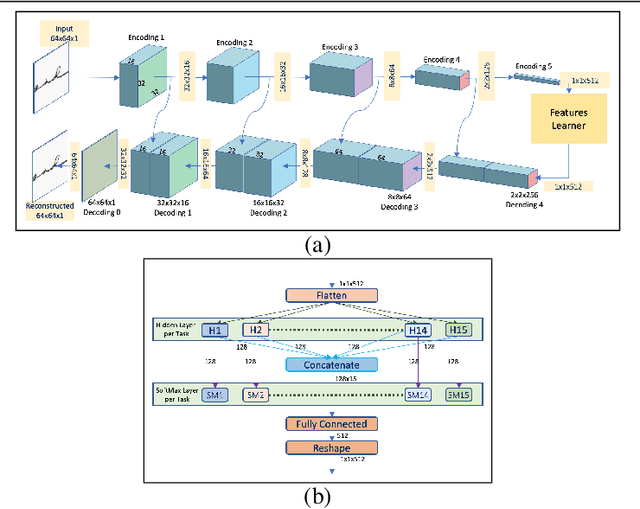
Deep learning system have drawback that their output is not accompanied with ex-planation. In a domain such as forensic handwriting verification it is essential to provideexplanation to jurors. The goal of handwriting verification is to find a measure of confi-dence whether the given handwritten samples are written by the same or different writer.We propose a method to generate explanations for the confidence provided by convolu-tional neural network (CNN) which maps the input image to 15 annotations (features)provided by experts. Our system comprises of: (1) Feature learning network (FLN),a differentiable system, (2) Inference module for providing explanations. Furthermore,inference module provides two types of explanations: (a) Based on cosine similaritybetween categorical probabilities of each feature, (b) Based on Log-Likelihood Ratio(LLR) using directed probabilistic graphical model. We perform experiments using acombination of feature learning network (FLN) and each inference module. We evaluateour system using XAI-AND dataset, containing 13700 handwritten samples and 15 cor-responding expert examined features for each sample. The dataset is released for publicuse and the methods can be extended to provide explanations on other verification taskslike face verification and bio-medical comparison. This dataset can serve as the basis and benchmark for future research in explanation based handwriting verification. The code is available on github.
Sequential Embedding Induced Text Clustering, a Non-parametric Bayesian Approach
Nov 29, 2018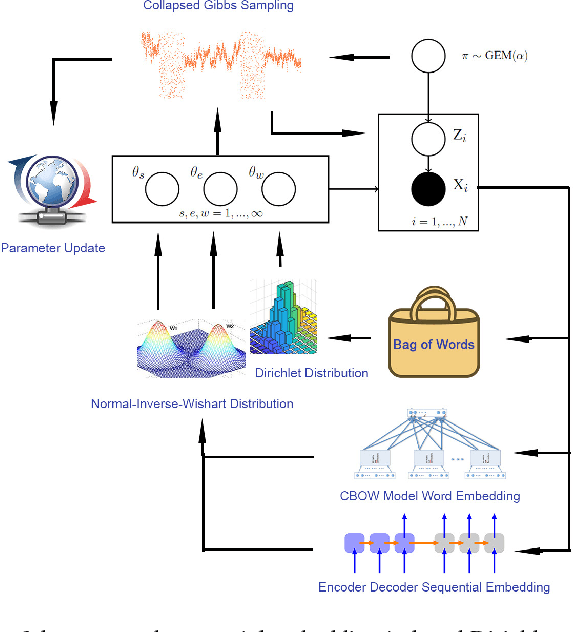

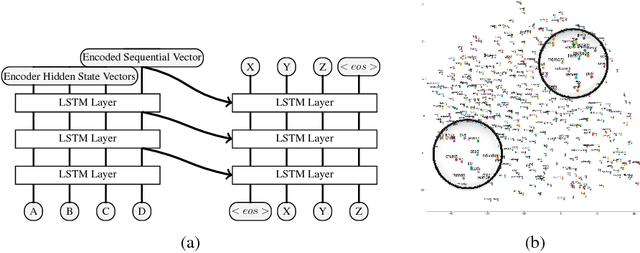
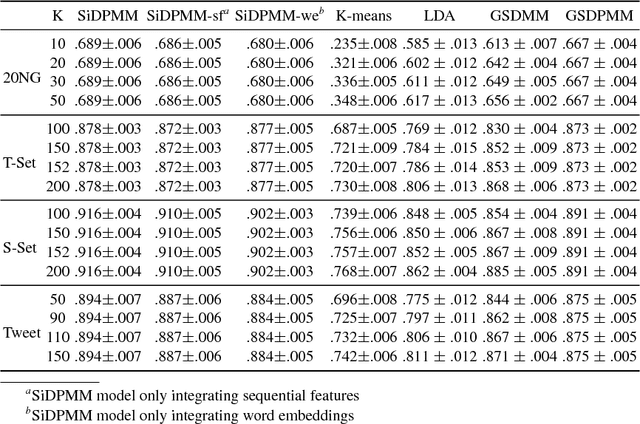
Current state-of-the-art nonparametric Bayesian text clustering methods model documents through multinomial distribution on bags of words. Although these methods can effectively utilize the word burstiness representation of documents and achieve decent performance, they do not explore the sequential information of text and relationships among synonyms. In this paper, the documents are modeled as the joint of bags of words, sequential features and word embeddings. We proposed Sequential Embedding induced Dirichlet Process Mixture Model (SiDPMM) to effectively exploit this joint document representation in text clustering. The sequential features are extracted by the encoder-decoder component. Word embeddings produced by the continuous-bag-of-words (CBOW) model are introduced to handle synonyms. Experimental results demonstrate the benefits of our model in two major aspects: 1) improved performance across multiple diverse text datasets in terms of the normalized mutual information (NMI); 2) more accurate inference of ground truth cluster numbers with regularization effect on tiny outlier clusters.
Joint Visual Denoising and Classification using Deep Learning
Dec 04, 2016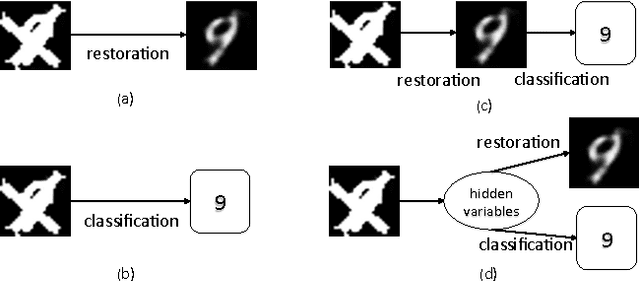



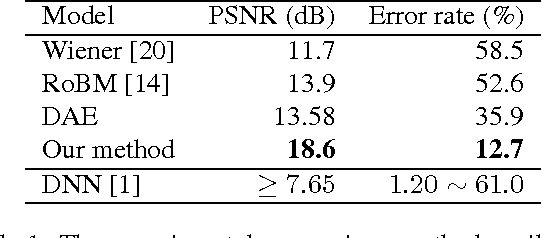
Visual restoration and recognition are traditionally addressed in pipeline fashion, i.e. denoising followed by classification. Instead, observing correlations between the two tasks, for example clearer image will lead to better categorization and vice visa, we propose a joint framework for visual restoration and recognition for handwritten images, inspired by advances in deep autoencoder and multi-modality learning. Our model is a 3-pathway deep architecture with a hidden-layer representation which is shared by multi-inputs and outputs, and each branch can be composed of a multi-layer deep model. Thus, visual restoration and classification can be unified using shared representation via non-linear mapping, and model parameters can be learnt via backpropagation. Using MNIST and USPS data corrupted with structured noise, the proposed framework performs at least 20\% better in classification than separate pipelines, as well as clearer recovered images. The noise model and the reproducible source code is available at {\url{https://github.com/ganggit/jointmodel}}.
Word Recognition with Deep Conditional Random Fields
Dec 04, 2016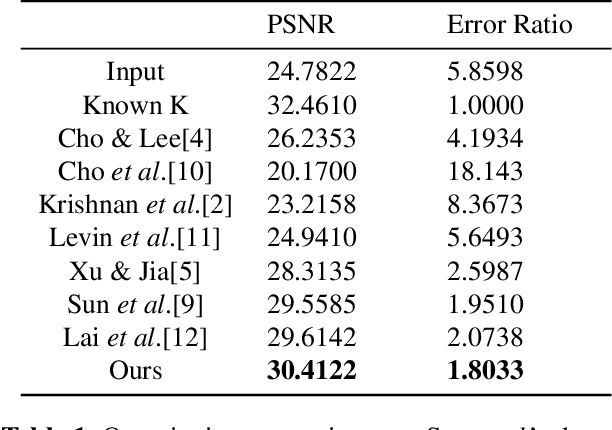
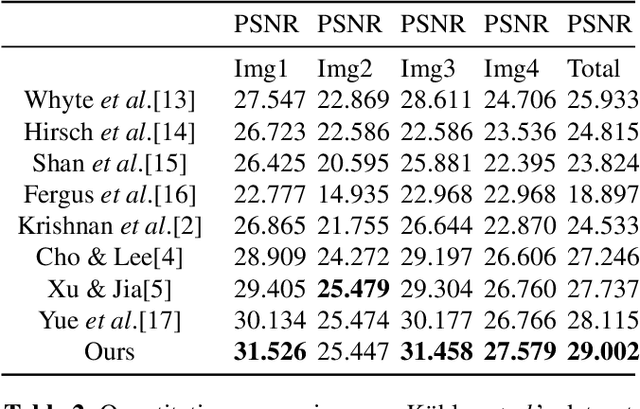
Recognition of handwritten words continues to be an important problem in document analysis and recognition. Existing approaches extract hand-engineered features from word images--which can perform poorly with new data sets. Recently, deep learning has attracted great attention because of the ability to learn features from raw data. Moreover they have yielded state-of-the-art results in classification tasks including character recognition and scene recognition. On the other hand, word recognition is a sequential problem where we need to model the correlation between characters. In this paper, we propose using deep Conditional Random Fields (deep CRFs) for word recognition. Basically, we combine CRFs with deep learning, in which deep features are learned and sequences are labeled in a unified framework. We pre-train the deep structure with stacked restricted Boltzmann machines (RBMs) for feature learning and optimize the entire network with an online learning algorithm. The proposed model was evaluated on two datasets, and seen to perform significantly better than competitive baseline models. The source code is available at https://github.com/ganggit/deepCRFs.
Generalized K-fan Multimodal Deep Model with Shared Representations
Mar 26, 2015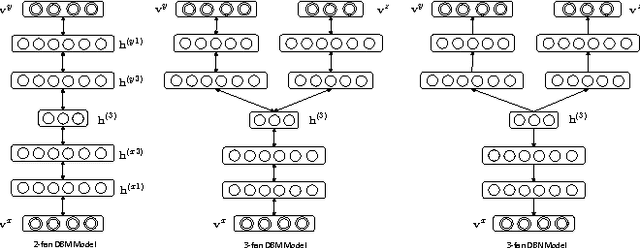


Multimodal learning with deep Boltzmann machines (DBMs) is an generative approach to fuse multimodal inputs, and can learn the shared representation via Contrastive Divergence (CD) for classification and information retrieval tasks. However, it is a 2-fan DBM model, and cannot effectively handle multiple prediction tasks. Moreover, this model cannot recover the hidden representations well by sampling from the conditional distribution when more than one modalities are missing. In this paper, we propose a K-fan deep structure model, which can handle the multi-input and muti-output learning problems effectively. In particular, the deep structure has K-branch for different inputs where each branch can be composed of a multi-layer deep model, and a shared representation is learned in an discriminative manner to tackle multimodal tasks. Given the deep structure, we propose two objective functions to handle two multi-input and multi-output tasks: joint visual restoration and labeling, and the multi-view multi-calss object recognition tasks. To estimate the model parameters, we initialize the deep model parameters with CD to maximize the joint distribution, and then we use backpropagation to update the model according to specific objective function. The experimental results demonstrate that the model can effectively leverages multi-source information and predict multiple tasks well over competitive baselines.