 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized K-fan Multimodal Deep Model with Shared Representations
Paper and Code
Mar 26, 2015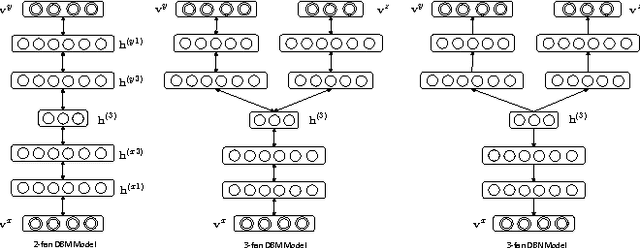
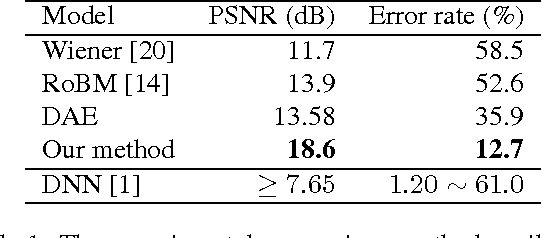


Multimodal learning with deep Boltzmann machines (DBMs) is an generative approach to fuse multimodal inputs, and can learn the shared representation via Contrastive Divergence (CD) for classification and information retrieval tasks. However, it is a 2-fan DBM model, and cannot effectively handle multiple prediction tasks. Moreover, this model cannot recover the hidden representations well by sampling from the conditional distribution when more than one modalities are missing. In this paper, we propose a K-fan deep structure model, which can handle the multi-input and muti-output learning problems effectively. In particular, the deep structure has K-branch for different inputs where each branch can be composed of a multi-layer deep model, and a shared representation is learned in an discriminative manner to tackle multimodal tasks. Given the deep structure, we propose two objective functions to handle two multi-input and multi-output tasks: joint visual restoration and labeling, and the multi-view multi-calss object recognition tasks. To estimate the model parameters, we initialize the deep model parameters with CD to maximize the joint distribution, and then we use backpropagation to update the model according to specific objective function. The experimental results demonstrate that the model can effectively leverages multi-source information and predict multiple tasks well over competitive baselines.