 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETT-CKGE: Efficient Task-driven Tokens for Continual Knowledge Graph Embedding
Jun 09, 2025Continual Knowledge Graph Embedding (CKGE) seeks to integrate new knowledge while preserving past information. However, existing methods struggle with efficiency and scalability due to two key limitations: (1) suboptimal knowledge preservation between snapshots caused by manually designed node/relation importance scores that ignore graph dependencies relevant to the downstream task, and (2) computationally expensive graph traversal for node/relation importance calculation, leading to slow training and high memory overhead. To address these limitations, we introduce ETT-CKGE (Efficient, Task-driven, Tokens for Continual Knowledge Graph Embedding), a novel task-guided CKGE method that leverages efficient task-driven tokens for efficient and effective knowledge transfer between snapshots. Our method introduces a set of learnable tokens that directly capture task-relevant signals, eliminating the need for explicit node scoring or traversal. These tokens serve as consistent and reusable guidance across snapshots, enabling efficient token-masked embedding alignment between snapshots. Importantly, knowledge transfer is achieved through simple matrix operations, significantly reducing training time and memory usage. Extensive experiments across six benchmark datasets demonstrate that ETT-CKGE consistently achieves superior or competitive predictive performance, while substantially improving training efficiency and scalability compared to state-of-the-art CKGE methods. The code is available at: https://github.com/lijingzhu1/ETT-CKGE/tree/main
Distributionally Robust Cross Subject EEG Decoding
Aug 19, 2023



Recently, deep learning has shown to be effective for Electroencephalography (EEG) decoding tasks. Yet, its performance can be negatively influenced by two key factors: 1) the high variance and different types of corruption that are inherent in the signal, 2) the EEG datasets are usually relatively small given the acquisition cost, annotation cost and amount of effort needed. Data augmentation approaches for alleviation of this problem have been empirically studied, with augmentation operations on spatial domain, time domain or frequency domain handcrafted based on expertise of domain knowledge. In this work, we propose a principled approach to perform dynamic evolution on the data for improvement of decoding robustness. The approach is based on distributionally robust optimization and achieves robustness by optimizing on a family of evolved data distributions instead of the single training data distribution. We derived a general data evolution framework based on Wasserstein gradient flow (WGF) and provides two different forms of evolution within the framework. Intuitively, the evolution process helps the EEG decoder to learn more robust and diverse features. It is worth mentioning that the proposed approach can be readily integrated with other data augmentation approaches for further improvements. We performed extensive experiments on the proposed approach and tested its performance on different types of corrupted EEG signals. The model significantly outperforms competitive baselines on challenging decoding scenarios.
Meta-Learning with Less Forgetting on Large-Scale Non-Stationary Task Distributions
Sep 03, 2022

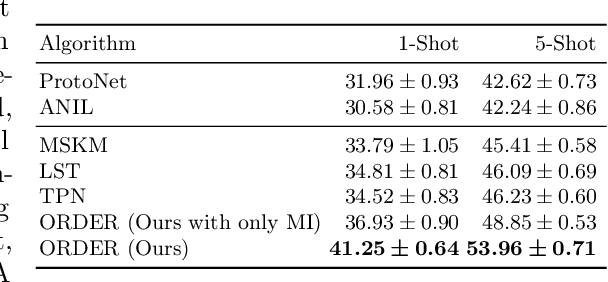
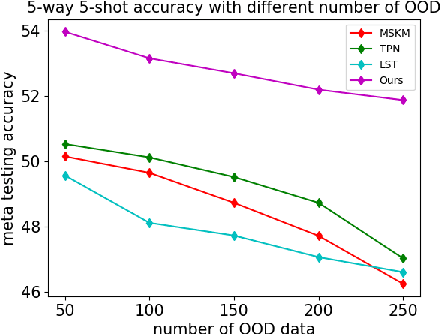
The paradigm of machine intelligence moves from purely supervised learning to a more practical scenario when many loosely related unlabeled data are available and labeled data is scarce. Most existing algorithms assume that the underlying task distribution is stationary. Here we consider a more realistic and challenging setting in that task distributions evolve over time. We name this problem as Semi-supervised meta-learning with Evolving Task diStributions, abbreviated as SETS. Two key challenges arise in this more realistic setting: (i) how to use unlabeled data in the presence of a large amount of unlabeled out-of-distribution (OOD) data; and (ii) how to prevent catastrophic forgetting on previously learned task distributions due to the task distribution shift. We propose an OOD Robust and knowleDge presErved semi-supeRvised meta-learning approach (ORDER), to tackle these two major challenges. Specifically, our ORDER introduces a novel mutual information regularization to robustify the model with unlabeled OOD data and adopts an optimal transport regularization to remember previously learned knowledge in feature space. In addition, we test our method on a very challenging dataset: SETS on large-scale non-stationary semi-supervised task distributions consisting of (at least) 72K tasks. With extensive experiments, we demonstrate the proposed ORDER alleviates forgetting on evolving task distributions and is more robust to OOD data than related strong baselines.
Improving Task-free Continual Learning by Distributionally Robust Memory Evolution
Jul 15, 2022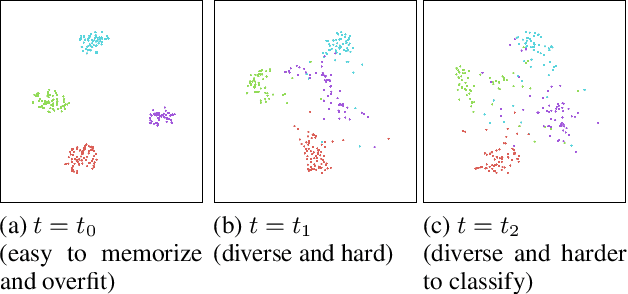
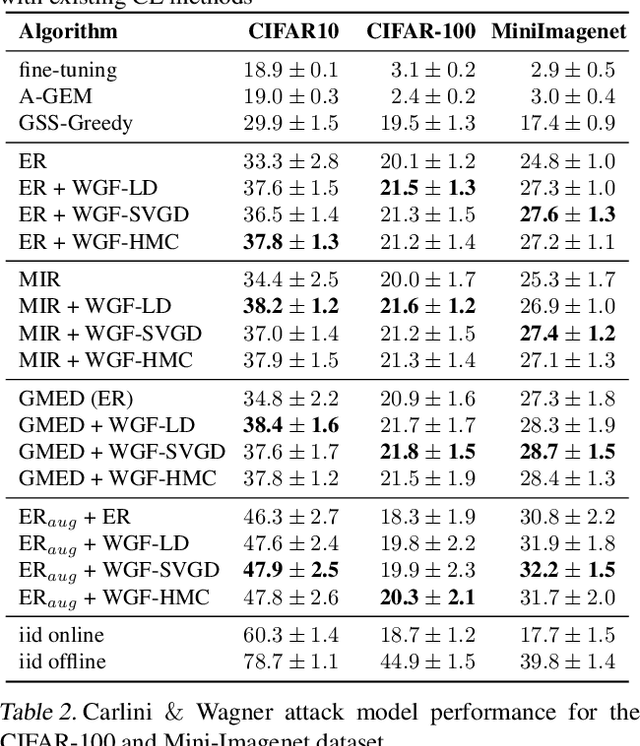
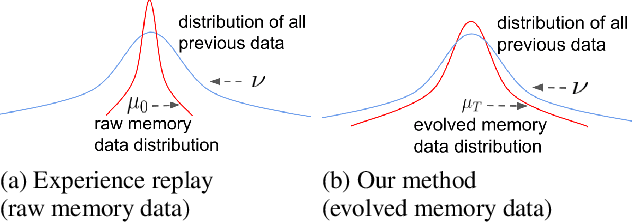
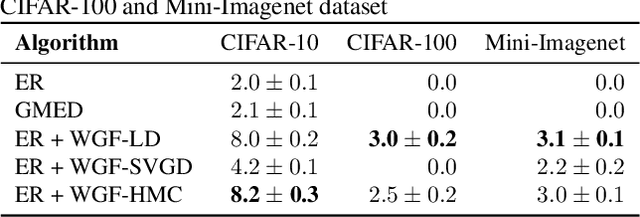
Task-free continual learning (CL) aims to learn a non-stationary data stream without explicit task definitions and not forget previous knowledge. The widely adopted memory replay approach could gradually become less effective for long data streams, as the model may memorize the stored examples and overfit the memory buffer. Second, existing methods overlook the high uncertainty in the memory data distribution since there is a big gap between the memory data distribution and the distribution of all the previous data examples. To address these problems, for the first time, we propose a principled memory evolution framework to dynamically evolve the memory data distribution by making the memory buffer gradually harder to be memorized with distributionally robust optimization (DRO). We then derive a family of methods to evolve the memory buffer data in the continuous probability measure space with Wasserstein gradient flow (WGF). The proposed DRO is w.r.t the worst-case evolved memory data distribution, thus guarantees the model performance and learns significantly more robust features than existing memory-replay-based methods. Extensive experiments on existing benchmarks demonstrate the effectiveness of the proposed methods for alleviating forgetting. As a by-product of the proposed framework, our method is more robust to adversarial examples than existing task-free CL methods.
Uncertainty Detection in EEG Neural Decoding Models
Dec 28, 2021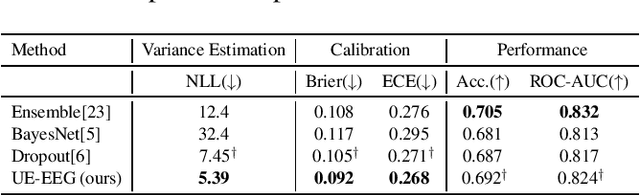

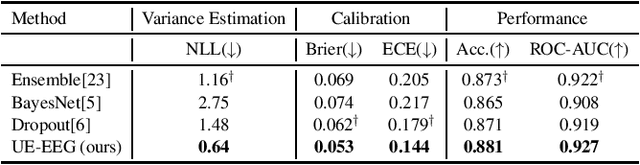
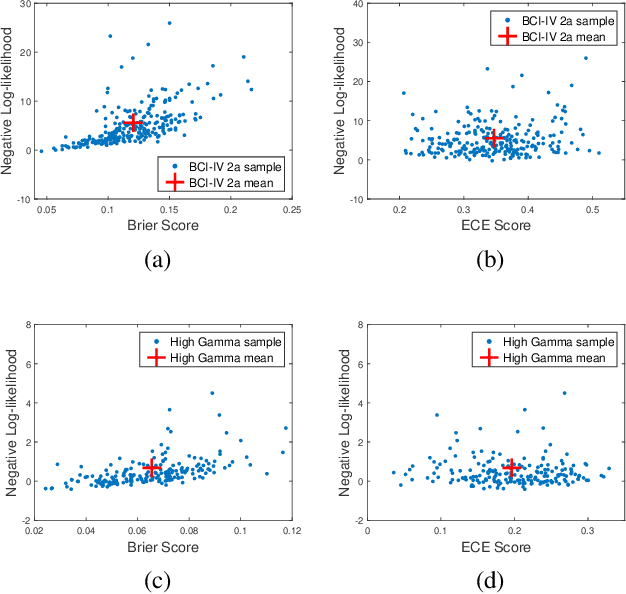
EEG decoding systems based on deep neural networks have been widely used in decision making of brain computer interfaces (BCI). Their predictions, however, can be unreliable given the significant variance and noise in EEG signals. Previous works on EEG analysis mainly focus on the exploration of noise pattern in the source signal, while the uncertainty during the decoding process is largely unexplored. Automatically detecting and quantifying such decoding uncertainty is important for BCI motor imagery applications such as robotic arm control etc. In this work, we proposed an uncertainty estimation model (UE-EEG) to explore the uncertainty during the EEG decoding process, which considers both the uncertainty in the input signal and the uncertainty in the model. The model utilized dropout oriented method for model uncertainty estimation, and Bayesian neural network is adopted for modeling the uncertainty of input data. The model can be integrated into current widely used deep learning classifiers without change of architecture. We performed extensive experiments for uncertainty estimation in both intra-subject EEG decoding and cross-subject EEG decoding on two public motor imagery datasets, where the proposed model achieves significant improvement on the quality of estimated uncertainty and demonstrates the proposed UE-EEG is a useful tool for BCI applications.
Meta Learning on a Sequence of Imbalanced Domains with Difficulty Awareness
Sep 29, 2021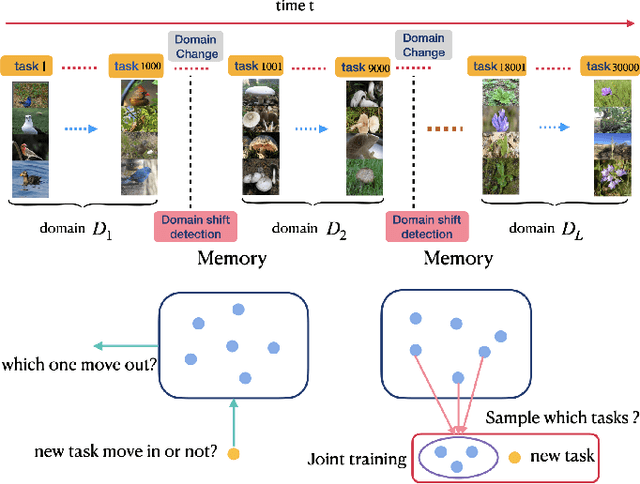
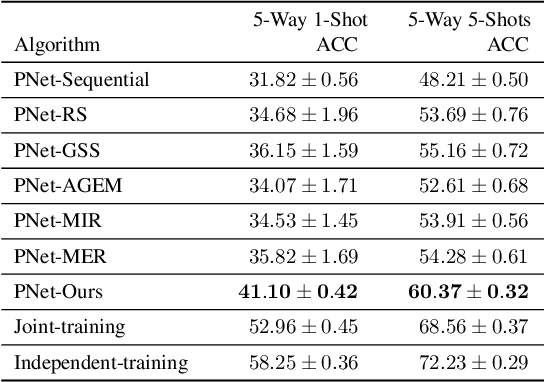
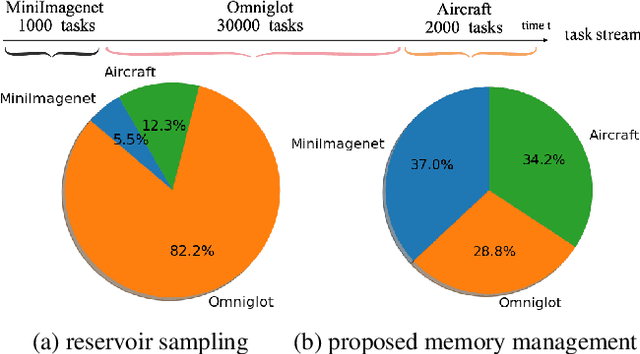
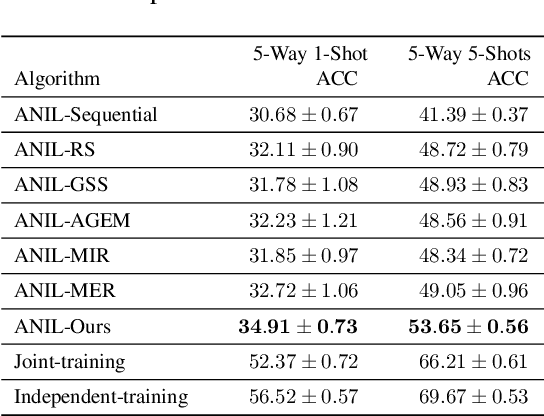
Recognizing new objects by learning from a few labeled examples in an evolving environment is crucial to obtain excellent generalization ability for real-world machine learning systems. A typical setting across current meta learning algorithms assumes a stationary task distribution during meta training. In this paper, we explore a more practical and challenging setting where task distribution changes over time with domain shift. Particularly, we consider realistic scenarios where task distribution is highly imbalanced with domain labels unavailable in nature. We propose a kernel-based method for domain change detection and a difficulty-aware memory management mechanism that jointly considers the imbalanced domain size and domain importance to learn across domains continuously. Furthermore, we introduce an efficient adaptive task sampling method during meta training, which significantly reduces task gradient variance with theoretical guarantees. Finally, we propose a challenging benchmark with imbalanced domain sequences and varied domain difficulty. We have performed extensive evaluations on the proposed benchmark, demonstrating the effectiveness of our method. We made our code publicly available.
Attention based Writer Independent Handwriting Verification
Oct 01, 2020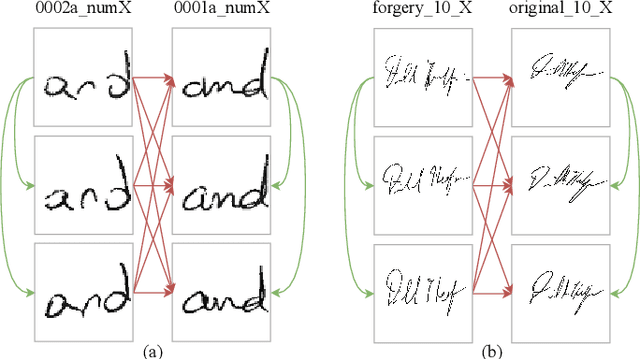
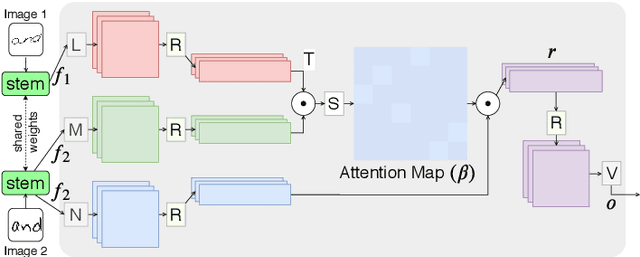
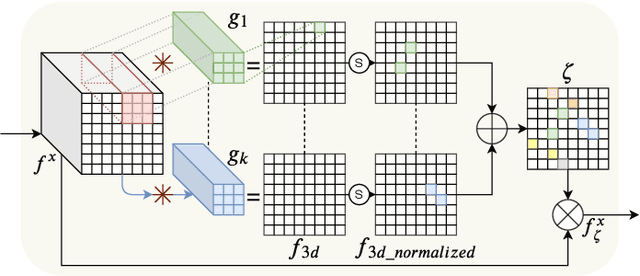
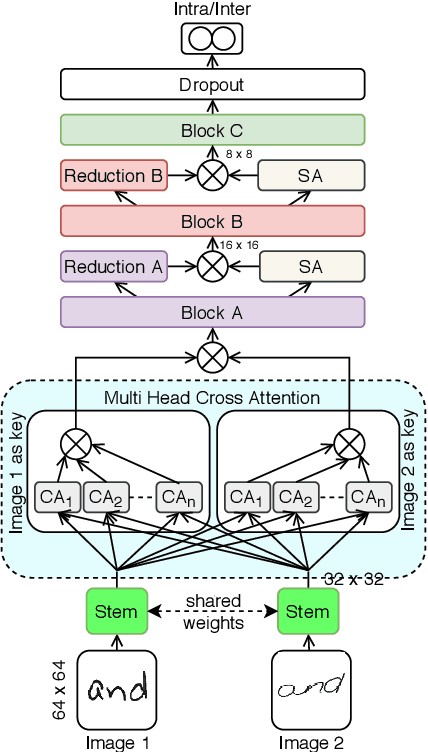
The task of writer verification is to provide a likelihood score for whether the queried and known handwritten image samples belong to the same writer or not. Such a task calls for the neural network to make it's outcome interpretable, i.e. provide a view into the network's decision making process. We implement and integrate cross-attention and soft-attention mechanisms to capture the highly correlated and salient points in feature space of 2D inputs. The attention maps serve as an explanation premise for the network's output likelihood score. The attention mechanism also allows the network to focus more on relevant areas of the input, thus improving the classification performance. Our proposed approach achieves a precision of 86\% for detecting intra-writer cases in CEDAR cursive "AND" dataset. Furthermore, we generate meaningful explanations for the provided decision by extracting attention maps from multiple levels of the network.
Ultra Efficient Transfer Learning with Meta Update for Cross Subject EEG Classification
Mar 13, 2020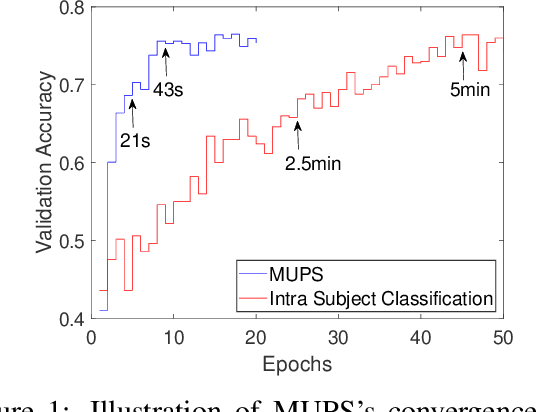
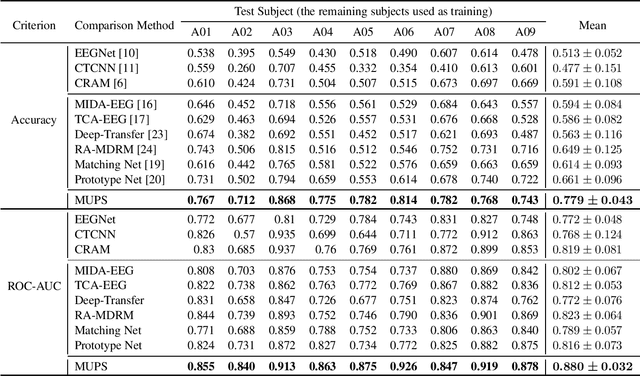
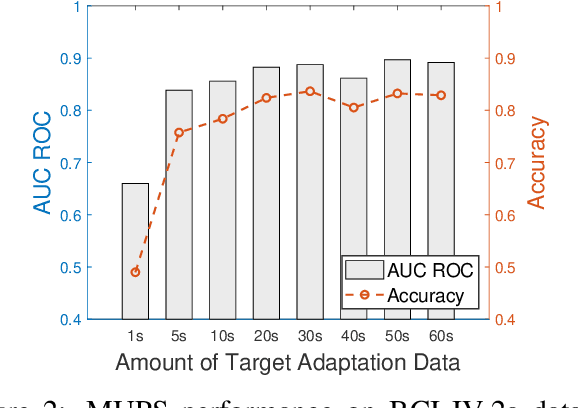
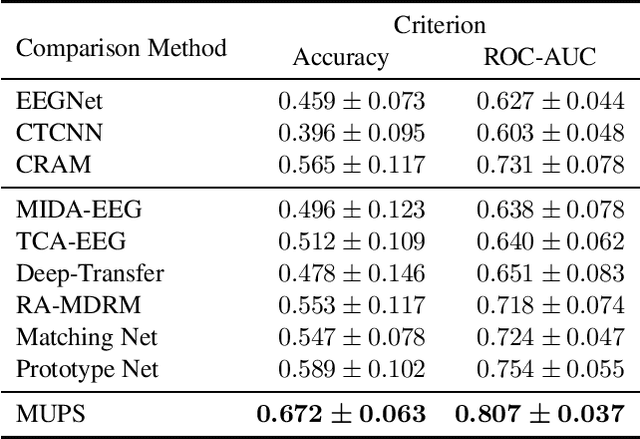
Electroencephalogram (EEG) signal is widely used in brain computer interfaces (BCI), the pattern of which differs significantly across different subjects, and poses a major challenge for real world application of EEG classifiers. We found an efficient transfer learning method, named Meta UPdate Strategy (MUPS), boosts cross subject classification performance of EEG signals, and only need a small amount of data from target subject. The model tackles the problem with a two step process: (1) extract versatile features that are effective across all source subjects, and (2) adapt the model to target subject. The proposed model, which originates from meta learning, aims to find feature representation that is broadly suitable for different subjects, and maximizes sensitivity of the loss function on new subject such that one or a small number of gradient steps can lead to effective adaptation. The method can be applied to all deep learning oriented models. We performed extensive experiments on two public datasets, the proposed MUPS model outperforms current state of the arts by a large margin on accuracy and AUC-ROC when only a small amount of target data is used.
Parallel Clustering of Single Cell Transcriptomic Data with Split-Merge Sampling on Dirichlet Process Mixtures
Dec 25, 2018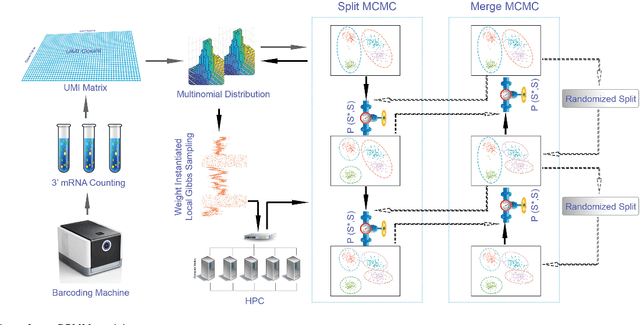

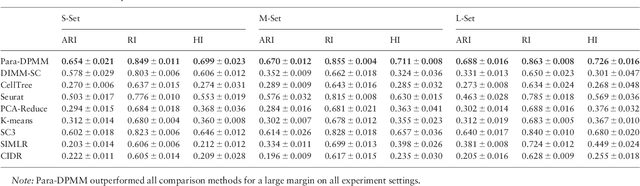

Motivation: With the development of droplet based systems, massive single cell transcriptome data has become available, which enables analysis of cellular and molecular processes at single cell resolution and is instrumental to understanding many biological processes. While state-of-the-art clustering methods have been applied to the data, they face challenges in the following aspects: (1) the clustering quality still needs to be improved; (2) most models need prior knowledge on number of clusters, which is not always available; (3) there is a demand for faster computational speed. Results: We propose to tackle these challenges with Parallel Split Merge Sampling on Dirichlet Process Mixture Model (the Para-DPMM model). Unlike classic DPMM methods that perform sampling on each single data point, the split merge mechanism samples on the cluster level, which significantly improves convergence and optimality of the result. The model is highly parallelized and can utilize the computing power of high performance computing (HPC) clusters, enabling massive clustering on huge datasets. Experiment results show the model outperforms current widely used models in both clustering quality and computational speed. Availability: Source code is publicly available on https://github.com/tiehangd/Para_DPMM/tree/master/Para_DPMM_package
Sequential Embedding Induced Text Clustering, a Non-parametric Bayesian Approach
Nov 29, 2018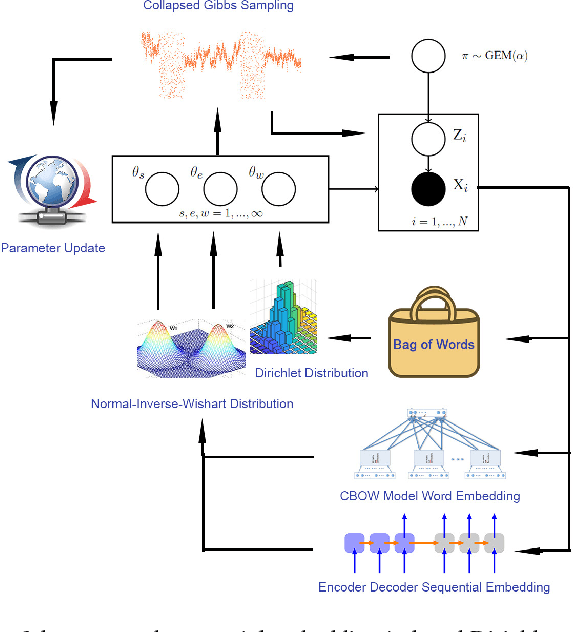

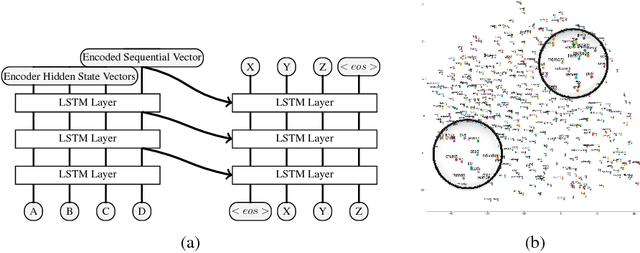
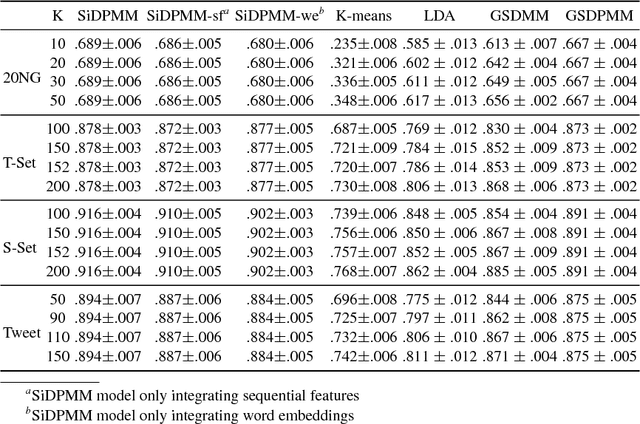
Current state-of-the-art nonparametric Bayesian text clustering methods model documents through multinomial distribution on bags of words. Although these methods can effectively utilize the word burstiness representation of documents and achieve decent performance, they do not explore the sequential information of text and relationships among synonyms. In this paper, the documents are modeled as the joint of bags of words, sequential features and word embeddings. We proposed Sequential Embedding induced Dirichlet Process Mixture Model (SiDPMM) to effectively exploit this joint document representation in text clustering. The sequential features are extracted by the encoder-decoder component. Word embeddings produced by the continuous-bag-of-words (CBOW) model are introduced to handle synonyms. Experimental results demonstrate the benefits of our model in two major aspects: 1) improved performance across multiple diverse text datasets in terms of the normalized mutual information (NMI); 2) more accurate inference of ground truth cluster numbers with regularization effect on tiny outlier clusters.