 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Clustering of Single Cell Transcriptomic Data with Split-Merge Sampling on Dirichlet Process Mixtures
Paper and Code
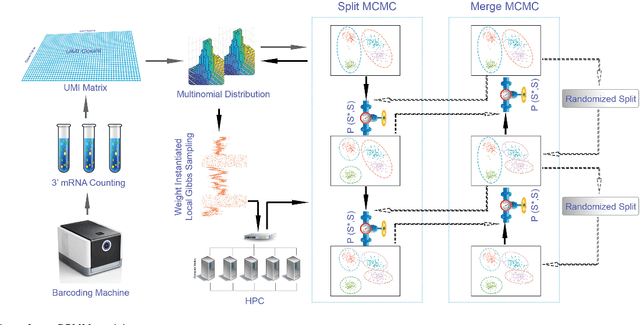

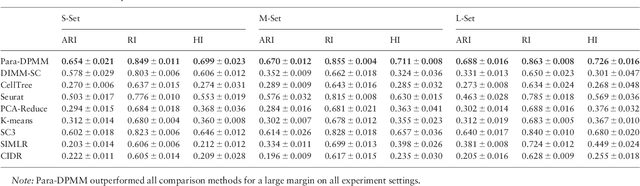

Motivation: With the development of droplet based systems, massive single cell transcriptome data has become available, which enables analysis of cellular and molecular processes at single cell resolution and is instrumental to understanding many biological processes. While state-of-the-art clustering methods have been applied to the data, they face challenges in the following aspects: (1) the clustering quality still needs to be improved; (2) most models need prior knowledge on number of clusters, which is not always available; (3) there is a demand for faster computational speed. Results: We propose to tackle these challenges with Parallel Split Merge Sampling on Dirichlet Process Mixture Model (the Para-DPMM model). Unlike classic DPMM methods that perform sampling on each single data point, the split merge mechanism samples on the cluster level, which significantly improves convergence and optimality of the result. The model is highly parallelized and can utilize the computing power of high performance computing (HPC) clusters, enabling massive clustering on huge datasets. Experiment results show the model outperforms current widely used models in both clustering quality and computational speed. Availability: Source code is publicly available on https://github.com/tiehangd/Para_DPMM/tree/master/Para_DPMM_package