 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Embedding Induced Text Clustering, a Non-parametric Bayesian Approach
Nov 29, 2018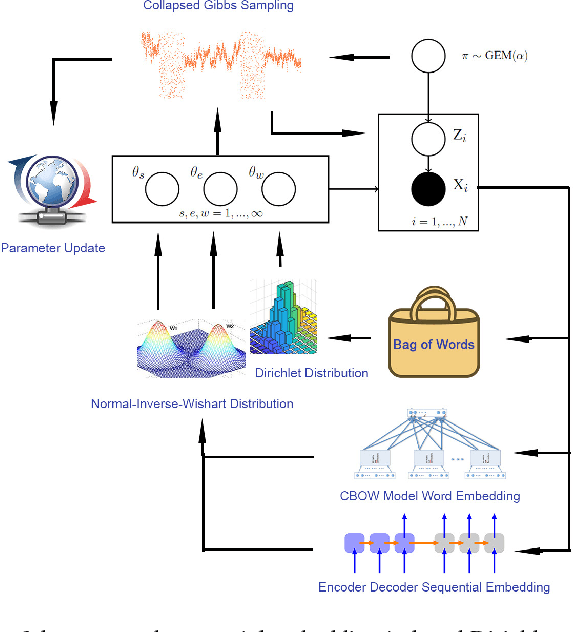

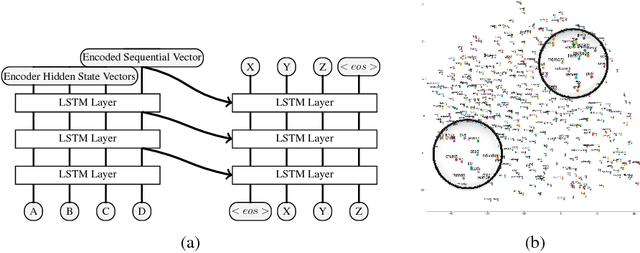
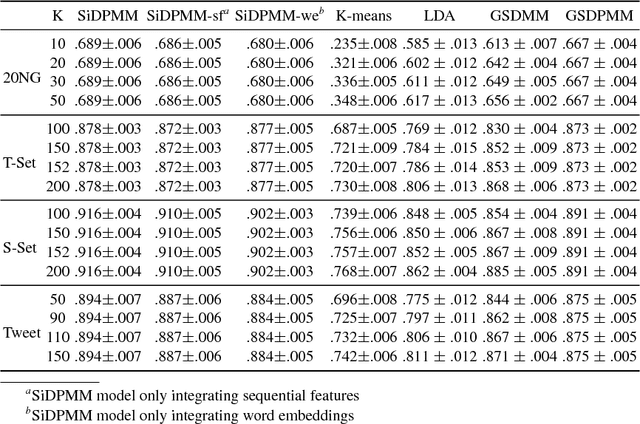
Current state-of-the-art nonparametric Bayesian text clustering methods model documents through multinomial distribution on bags of words. Although these methods can effectively utilize the word burstiness representation of documents and achieve decent performance, they do not explore the sequential information of text and relationships among synonyms. In this paper, the documents are modeled as the joint of bags of words, sequential features and word embeddings. We proposed Sequential Embedding induced Dirichlet Process Mixture Model (SiDPMM) to effectively exploit this joint document representation in text clustering. The sequential features are extracted by the encoder-decoder component. Word embeddings produced by the continuous-bag-of-words (CBOW) model are introduced to handle synonyms. Experimental results demonstrate the benefits of our model in two major aspects: 1) improved performance across multiple diverse text datasets in terms of the normalized mutual information (NMI); 2) more accurate inference of ground truth cluster numbers with regularization effect on tiny outlier clusters.
Deep Multi-instance Networks with Sparse Label Assignment for Whole Mammogram Classification
May 23, 2017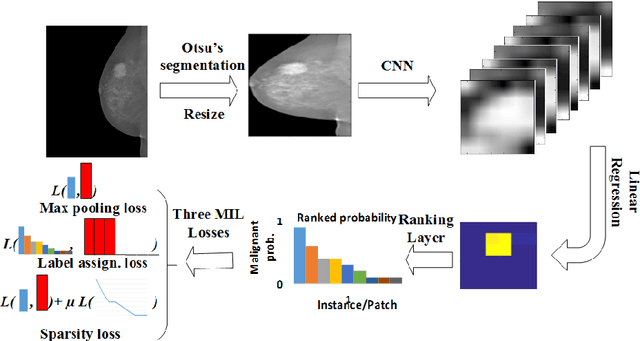
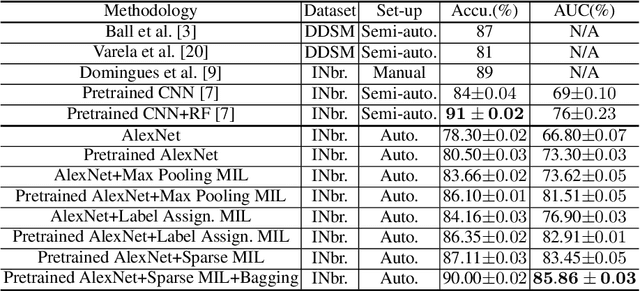
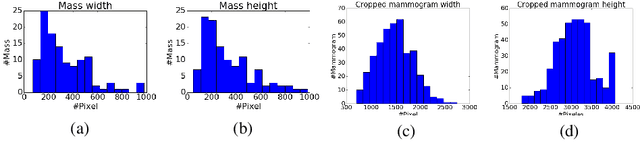
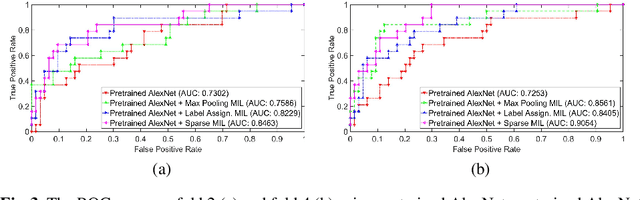
Mammogram classification is directly related to computer-aided diagnosis of breast cancer. Traditional methods rely on regions of interest (ROIs) which require great efforts to annotate. Inspired by the success of using deep convolutional features for natural image analysis and multi-instance learning (MIL) for labeling a set of instances/patches, we propose end-to-end trained deep multi-instance networks for mass classification based on whole mammogram without the aforementioned ROIs. We explore three different schemes to construct deep multi-instance networks for whole mammogram classification. Experimental results on the INbreast dataset demonstrate the robustness of proposed networks compared to previous work using segmentation and detection annotations.
Novelty Detection Under Multi-Instance Multi-Label Framework
Nov 25, 2013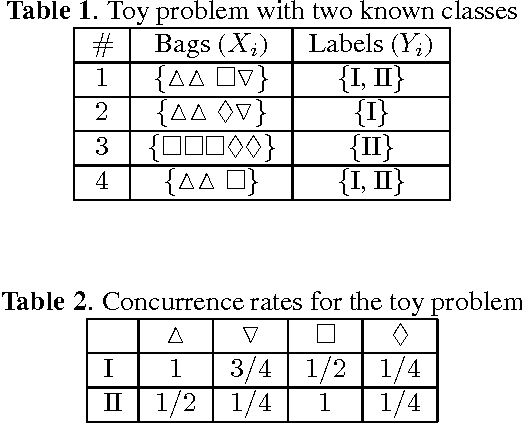
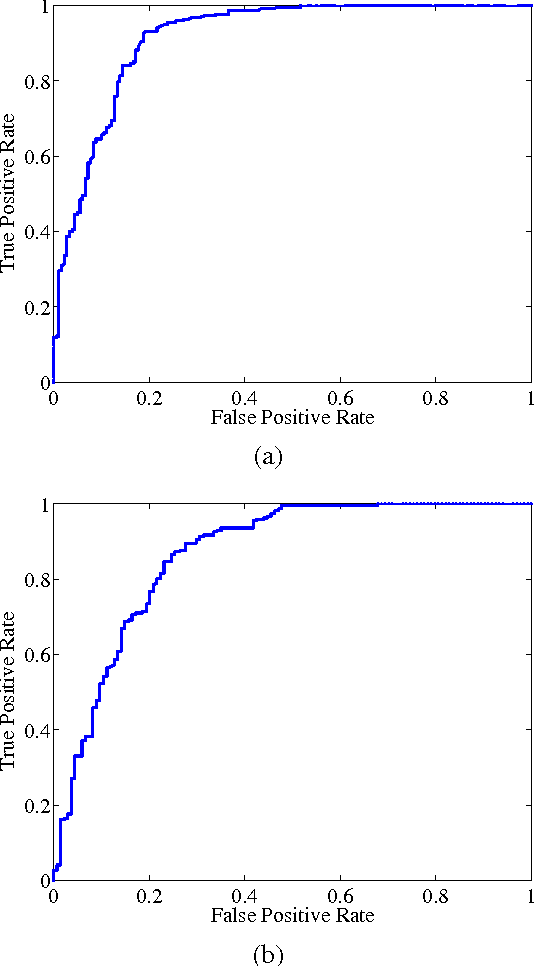

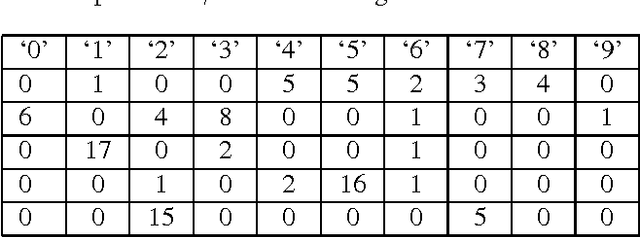
Novelty detection plays an important role in machine learning and signal processing. This paper studies novelty detection in a new setting where the data object is represented as a bag of instances and associated with multiple class labels, referred to as multi-instance multi-label (MIML) learning. Contrary to the common assumption in MIML that each instance in a bag belongs to one of the known classes, in novelty detection, we focus on the scenario where bags may contain novel-class instances. The goal is to determine, for any given instance in a new bag, whether it belongs to a known class or a novel class. Detecting novelty in the MIML setting captures many real-world phenomena and has many potential applications. For example, in a collection of tagged images, the tag may only cover a subset of objects existing in the images. Discovering an object whose class has not been previously tagged can be useful for the purpose of soliciting a label for the new object class. To address this novel problem, we present a discriminative framework for detecting new class instances. Experiments demonstrate the effectiveness of our proposed method, and reveal that the presence of unlabeled novel instances in training bags is helpful to the detection of such instances in testing stage.