 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETT-CKGE: Efficient Task-driven Tokens for Continual Knowledge Graph Embedding
Jun 09, 2025Continual Knowledge Graph Embedding (CKGE) seeks to integrate new knowledge while preserving past information. However, existing methods struggle with efficiency and scalability due to two key limitations: (1) suboptimal knowledge preservation between snapshots caused by manually designed node/relation importance scores that ignore graph dependencies relevant to the downstream task, and (2) computationally expensive graph traversal for node/relation importance calculation, leading to slow training and high memory overhead. To address these limitations, we introduce ETT-CKGE (Efficient, Task-driven, Tokens for Continual Knowledge Graph Embedding), a novel task-guided CKGE method that leverages efficient task-driven tokens for efficient and effective knowledge transfer between snapshots. Our method introduces a set of learnable tokens that directly capture task-relevant signals, eliminating the need for explicit node scoring or traversal. These tokens serve as consistent and reusable guidance across snapshots, enabling efficient token-masked embedding alignment between snapshots. Importantly, knowledge transfer is achieved through simple matrix operations, significantly reducing training time and memory usage. Extensive experiments across six benchmark datasets demonstrate that ETT-CKGE consistently achieves superior or competitive predictive performance, while substantially improving training efficiency and scalability compared to state-of-the-art CKGE methods. The code is available at: https://github.com/lijingzhu1/ETT-CKGE/tree/main
CIBR: Cross-modal Information Bottleneck Regularization for Robust CLIP Generalization
Mar 31, 2025Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success in cross-modal tasks such as zero-shot image classification and text-image retrieval by effectively aligning visual and textual representations. However, the theoretical foundations underlying CLIP's strong generalization remain unclear. In this work, we address this gap by proposing the Cross-modal Information Bottleneck (CIB) framework. CIB offers a principled interpretation of CLIP's contrastive learning objective as an implicit Information Bottleneck optimization. Under this view, the model maximizes shared cross-modal information while discarding modality-specific redundancies, thereby preserving essential semantic alignment across modalities. Building on this insight, we introduce a Cross-modal Information Bottleneck Regularization (CIBR) method that explicitly enforces these IB principles during training. CIBR introduces a penalty term to discourage modality-specific redundancy, thereby enhancing semantic alignment between image and text features. We validate CIBR on extensive vision-language benchmarks, including zero-shot classification across seven diverse image datasets and text-image retrieval on MSCOCO and Flickr30K. The results show consistent performance gains over standard CLIP. These findings provide the first theoretical understanding of CLIP's generalization through the IB lens. They also demonstrate practical improvements, offering guidance for future cross-modal representation learning.
HGTDP-DTA: Hybrid Graph-Transformer with Dynamic Prompt for Drug-Target Binding Affinity Prediction
Jun 25, 2024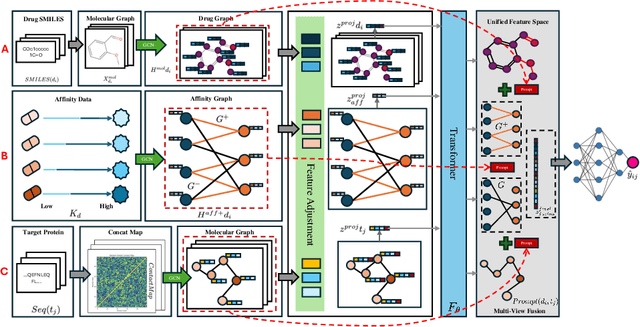
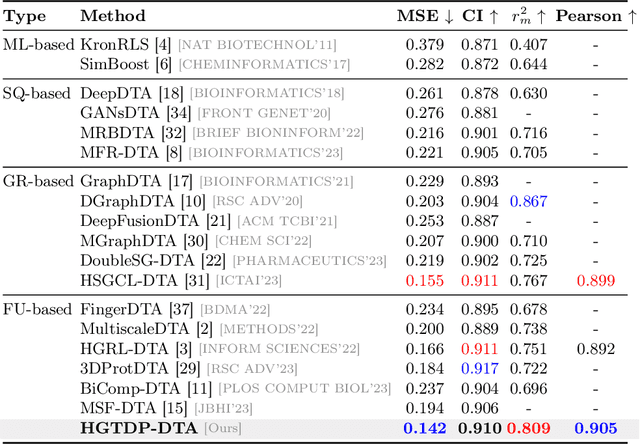
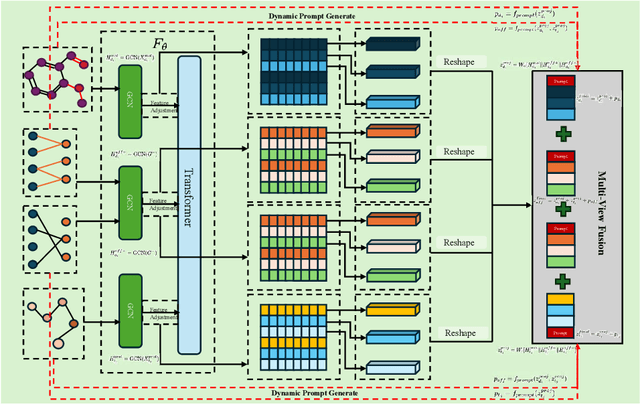
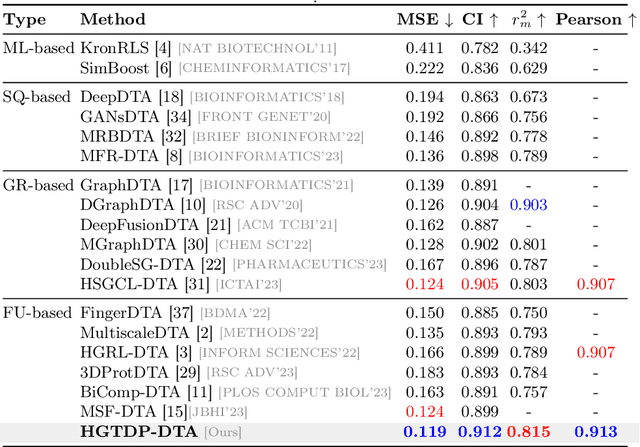
Drug target binding affinity (DTA) is a key criterion for drug screening. Existing experimental methods are time-consuming and rely on limited structural and domain information. While learning-based methods can model sequence and structural information, they struggle to integrate contextual data and often lack comprehensive modeling of drug-target interactions. In this study, we propose a novel DTA prediction method, termed HGTDP-DTA, which utilizes dynamic prompts within a hybrid Graph-Transformer framework. Our method generates context-specific prompts for each drug-target pair, enhancing the model's ability to capture unique interactions. The introduction of prompt tuning further optimizes the prediction process by filtering out irrelevant noise and emphasizing task-relevant information, dynamically adjusting the input features of the molecular graph. The proposed hybrid Graph-Transformer architecture combines structural information from Graph Convolutional Networks (GCNs) with sequence information captured by Transformers, facilitating the interaction between global and local information. Additionally, we adopted the multi-view feature fusion method to project molecular graph views and affinity subgraph views into a common feature space, effectively combining structural and contextual information. Experiments on two widely used public datasets, Davis and KIBA, show that HGTDP-DTA outperforms state-of-the-art DTA prediction methods in both prediction performance and generalization ability.
SKGHOI: Spatial-Semantic Knowledge Graph for Human-Object Interaction Detection
Mar 15, 2023Detecting human-object interactions (HOIs) is a challenging problem in computer vision. Existing techniques for HOI detection heavily rely on appearance-based features, which may not capture other essential characteristics for accurate detection. Furthermore, the use of transformer-based models for sentiment representation of human-object pairs can be computationally expensive. To address these challenges, we propose a novel graph-based approach, SKGHOI (Spatial-Semantic Knowledge Graph for Human-Object Interaction Detection), that effectively captures the sentiment representation of HOIs by integrating both spatial and semantic knowledge. In a graph, SKGHOI takes the components of interaction as nodes, and the spatial relationships between them as edges. Our approach employs a spatial encoder and a semantic encoder to extract spatial and semantic information, respectively, and then combines these encodings to create a knowledge graph that captures the sentiment representation of HOIs. Compared to existing techniques, SKGHOI is computationally efficient and allows for the incorporation of prior knowledge, making it practical for use in real-world applications. We demonstrate the effectiveness of our proposed method on the widely-used HICO-DET datasets, where it outperforms existing state-of-the-art graph-based methods by a significant margin. Our results indicate that the SKGHOI approach has the potential to significantly improve the accuracy and efficiency of HOI detection, and we anticipate that it will be of great interest to researchers and practitioners working on this challenging task.