 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable-Length Finite-Rate CSI Feedback With Generative Priors
Jun 05, 2026This letter studies variable-length finite-rate CSI feedback from a structural perspective and proposes CsiCoGen, a novel generative feedback structure with a transferable codebook mechanism without joint training. The UE maps $H_0$ into an ordered sequence of codebook indices, while the BS recursively recovers CSI from any received partial sequence of feedback indices using a shared denoising prior. This enables flexible control of feedback sequence length and per-step quantization precision through codebook size. CsiCoGen does not require jointly training a task-specific feedback encoder or codebook with the reconstructor, and the same online structure can be paired with different pretrained denoisers. In this work, we instantiate the decoder with a generative diffusion model. Simulation results on COST2100 show favorable rate-NMSE and rate-$ρ$ tradeoffs against representative baselines, with CsiCoGen reaching about -31 dB indoor NMSE and -20 dB outdoor NMSE in the high-rate regime while demonstrating scalable decoding complexity and adjustable per-step quantization precision.
Spatiotemporal Gaussian representation-based dynamic reconstruction and motion estimation framework for time-resolved volumetric MR imaging (DREME-GSMR)
Apr 07, 2026Time-resolved volumetric MR imaging that reconstructs a 3D MRI within sub-seconds to resolve deformable motion is essential for motion-adaptive radiotherapy. Representing patient anatomy and associated motion fields as 3D Gaussians, we developed a spatiotemporal Gaussian representation-based framework (DREME-GSMR), which enables time-resolved dynamic MRI reconstruction from a pre-treatment 3D MR scan without any prior anatomical/motion model. DREME-GSMR represents a reference MRI volume and a corresponding low-rank motion model (as motion-basis components) using 3D Gaussians, and incorporates a dual-path MLP/CNN motion encoder to estimate temporal motion coefficients of the motion model from raw k-space-derived signals. Furthermore, using the solved motion model, DREME-GSMR can infer motion coefficients directly from new online k-space data, allowing subsequent intra-treatment volumetric MR imaging and motion tracking (real-time imaging). A motion-augmentation strategy is further introduced to improve robustness to unseen motion patterns during real-time imaging. DREME-GSMR was evaluated on the XCAT digital phantom, a physical motion phantom, and MR-LINAC datasets acquired from 6 healthy volunteers and 20 patients (with independent sequential scans for cross-evaluation). DREME-GSMR reconstructs MRIs of a ~400ms temporal resolution, with an inference time of ~10ms/volume. In XCAT experiments, DREME-GSMR achieved mean(s.d.) SSIM, tumor center-of-mass-error(COME), and DSC of 0.92(0.01)/0.91(0.02), 0.50(0.15)/0.65(0.19) mm, and 0.92(0.02)/0.92(0.03) for dynamic reconstruction/real-time imaging. For the physical phantom, the mean target COME was 1.19(0.94)/1.40(1.15) mm for dynamic/real-time imaging, while for volunteers and patients, the mean liver COME for real-time imaging was 1.31(0.82) and 0.96(0.64) mm, respectively.
TOM: An Open-Source Tongue Segmentation Method with Multi-Teacher Distillation and Task-Specific Data Augmentation
Aug 19, 2025Tongue imaging serves as a valuable diagnostic tool, particularly in Traditional Chinese Medicine (TCM). The quality of tongue surface segmentation significantly affects the accuracy of tongue image classification and subsequent diagnosis in intelligent tongue diagnosis systems. However, existing research on tongue image segmentation faces notable limitations, and there is a lack of robust and user-friendly segmentation tools. This paper proposes a tongue image segmentation model (TOM) based on multi-teacher knowledge distillation. By incorporating a novel diffusion-based data augmentation method, we enhanced the generalization ability of the segmentation model while reducing its parameter size. Notably, after reducing the parameter count by 96.6% compared to the teacher models, the student model still achieves an impressive segmentation performance of 95.22% mIoU. Furthermore, we packaged and deployed the trained model as both an online and offline segmentation tool (available at https://itongue.cn/), allowing TCM practitioners and researchers to use it without any programming experience. We also present a case study on TCM constitution classification using segmented tongue patches. Experimental results demonstrate that training with tongue patches yields higher classification performance and better interpretability than original tongue images. To our knowledge, this is the first open-source and freely available tongue image segmentation tool.
TCM-Ladder: A Benchmark for Multimodal Question Answering on Traditional Chinese Medicine
May 29, 2025Traditional Chinese Medicine (TCM), as an effective alternative medicine, has been receiving increasing attention. In recent years, the rapid development of large language models (LLMs) tailored for TCM has underscored the need for an objective and comprehensive evaluation framework to assess their performance on real-world tasks. However, existing evaluation datasets are limited in scope and primarily text-based, lacking a unified and standardized multimodal question-answering (QA) benchmark. To address this issue, we introduce TCM-Ladder, the first multimodal QA dataset specifically designed for evaluating large TCM language models. The dataset spans multiple core disciplines of TCM, including fundamental theory, diagnostics, herbal formulas, internal medicine, surgery, pharmacognosy, and pediatrics. In addition to textual content, TCM-Ladder incorporates various modalities such as images and videos. The datasets were constructed using a combination of automated and manual filtering processes and comprise 52,000+ questions in total. These questions include single-choice, multiple-choice, fill-in-the-blank, diagnostic dialogue, and visual comprehension tasks. We trained a reasoning model on TCM-Ladder and conducted comparative experiments against 9 state-of-the-art general domain and 5 leading TCM-specific LLMs to evaluate their performance on the datasets. Moreover, we propose Ladder-Score, an evaluation method specifically designed for TCM question answering that effectively assesses answer quality regarding terminology usage and semantic expression. To our knowledge, this is the first work to evaluate mainstream general domain and TCM-specific LLMs on a unified multimodal benchmark. The datasets and leaderboard are publicly available at https://tcmladder.com or https://54.211.107.106 and will be continuously updated.
Time-resolved dynamic CBCT reconstruction using prior-model-free spatiotemporal Gaussian representation (PMF-STGR)
Mar 28, 2025Time-resolved CBCT imaging, which reconstructs a dynamic sequence of CBCTs reflecting intra-scan motion (one CBCT per x-ray projection without phase sorting or binning), is highly desired for regular and irregular motion characterization, patient setup, and motion-adapted radiotherapy. Representing patient anatomy and associated motion fields as 3D Gaussians, we developed a Gaussian representation-based framework (PMF-STGR) for fast and accurate dynamic CBCT reconstruction. PMF-STGR comprises three major components: a dense set of 3D Gaussians to reconstruct a reference-frame CBCT for the dynamic sequence; another 3D Gaussian set to capture three-level, coarse-to-fine motion-basis-components (MBCs) to model the intra-scan motion; and a CNN-based motion encoder to solve projection-specific temporal coefficients for the MBCs. Scaled by the temporal coefficients, the learned MBCs will combine into deformation vector fields to deform the reference CBCT into projection-specific, time-resolved CBCTs to capture the dynamic motion. Due to the strong representation power of 3D Gaussians, PMF-STGR can reconstruct dynamic CBCTs in a 'one-shot' training fashion from a standard 3D CBCT scan, without using any prior anatomical or motion model. We evaluated PMF-STGR using XCAT phantom simulations and real patient scans. Metrics including the image relative error, structural-similarity-index-measure, tumor center-of-mass-error, and landmark localization error were used to evaluate the accuracy of solved dynamic CBCTs and motion. PMF-STGR shows clear advantages over a state-of-the-art, INR-based approach, PMF-STINR. Compared with PMF-STINR, PMF-STGR reduces reconstruction time by 50% while reconstructing less blurred images with better motion accuracy. With improved efficiency and accuracy, PMF-STGR enhances the applicability of dynamic CBCT imaging for potential clinical translation.
TD-RD: A Top-Down Benchmark with Real-Time Framework for Road Damage Detection
Jan 24, 2025



Object detection has witnessed remarkable advancements over the past decade, largely driven by breakthroughs in deep learning and the proliferation of large scale datasets. However, the domain of road damage detection remains relatively under explored, despite its critical significance for applications such as infrastructure maintenance and road safety. This paper addresses this gap by introducing a novel top down benchmark that offers a complementary perspective to existing datasets, specifically tailored for road damage detection. Our proposed Top Down Road Damage Detection Dataset (TDRD) includes three primary categories of road damage cracks, potholes, and patches captured from a top down viewpoint. The dataset consists of 7,088 high resolution images, encompassing 12,882 annotated instances of road damage. Additionally, we present a novel real time object detection framework, TDYOLOV10, designed to handle the unique challenges posed by the TDRD dataset. Comparative studies with state of the art models demonstrate competitive baseline results. By releasing TDRD, we aim to accelerate research in this crucial area. A sample of the dataset will be made publicly available upon the paper's acceptance.
HGTDP-DTA: Hybrid Graph-Transformer with Dynamic Prompt for Drug-Target Binding Affinity Prediction
Jun 25, 2024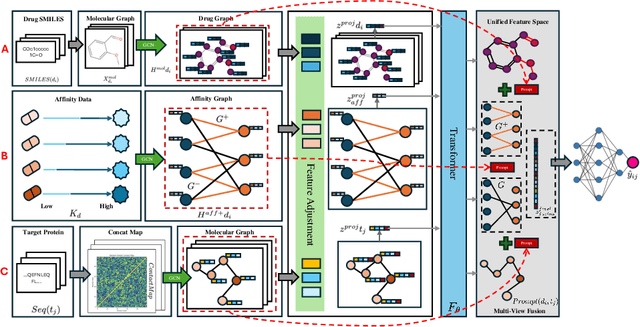
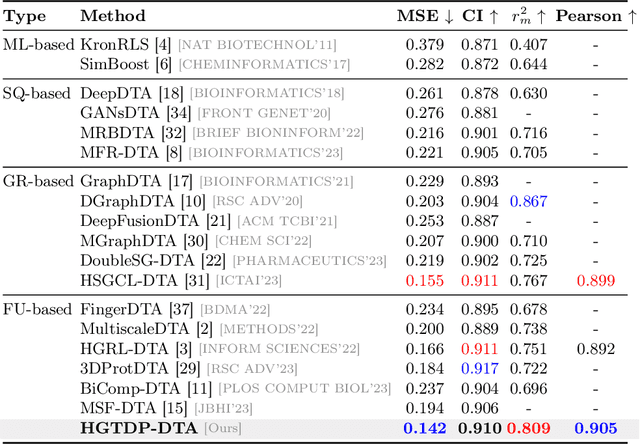
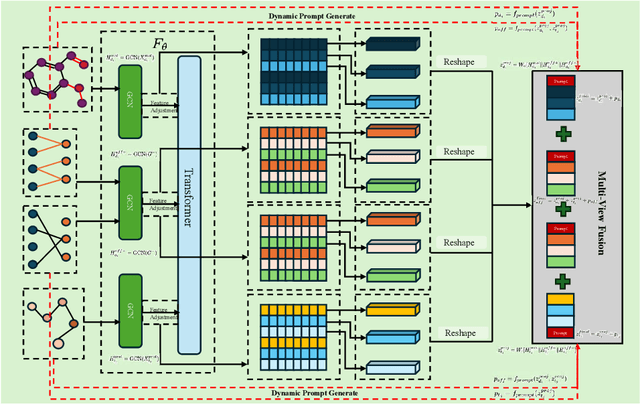
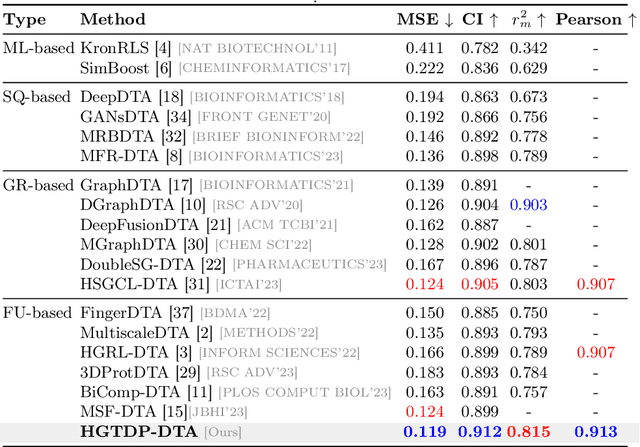
Drug target binding affinity (DTA) is a key criterion for drug screening. Existing experimental methods are time-consuming and rely on limited structural and domain information. While learning-based methods can model sequence and structural information, they struggle to integrate contextual data and often lack comprehensive modeling of drug-target interactions. In this study, we propose a novel DTA prediction method, termed HGTDP-DTA, which utilizes dynamic prompts within a hybrid Graph-Transformer framework. Our method generates context-specific prompts for each drug-target pair, enhancing the model's ability to capture unique interactions. The introduction of prompt tuning further optimizes the prediction process by filtering out irrelevant noise and emphasizing task-relevant information, dynamically adjusting the input features of the molecular graph. The proposed hybrid Graph-Transformer architecture combines structural information from Graph Convolutional Networks (GCNs) with sequence information captured by Transformers, facilitating the interaction between global and local information. Additionally, we adopted the multi-view feature fusion method to project molecular graph views and affinity subgraph views into a common feature space, effectively combining structural and contextual information. Experiments on two widely used public datasets, Davis and KIBA, show that HGTDP-DTA outperforms state-of-the-art DTA prediction methods in both prediction performance and generalization ability.
Cycle-YOLO: A Efficient and Robust Framework for Pavement Damage Detection
May 28, 2024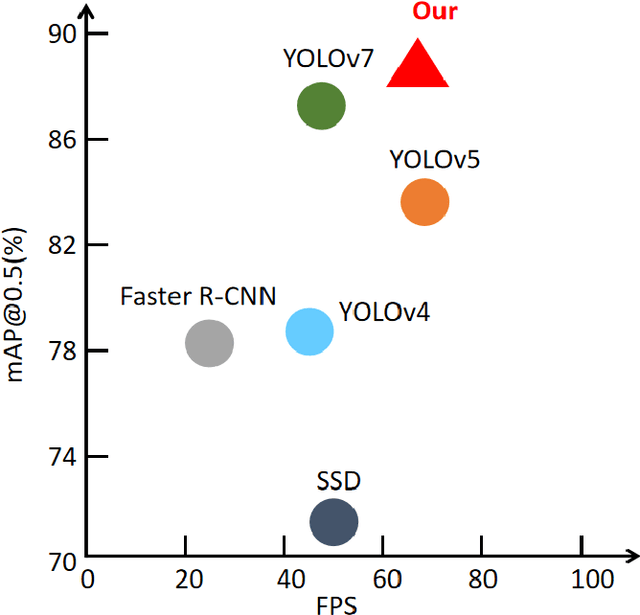
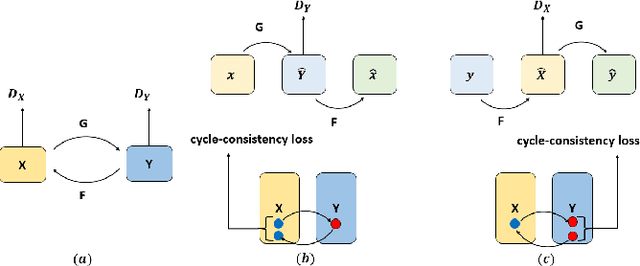

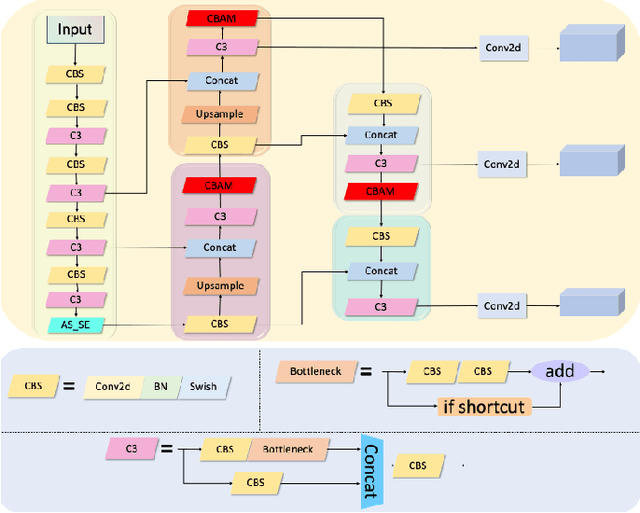
With the development of modern society, traffic volume continues to increase in most countries worldwide, leading to an increase in the rate of pavement damage Therefore, the real-time and highly accurate pavement damage detection and maintenance have become the current need. In this paper, an enhanced pavement damage detection method with CycleGAN and improved YOLOv5 algorithm is presented. We selected 7644 self-collected images of pavement damage samples as the initial dataset and augmented it by CycleGAN. Due to a substantial difference between the images generated by CycleGAN and real road images, we proposed a data enhancement method based on an improved Scharr filter, CycleGAN, and Laplacian pyramid. To improve the target recognition effect on a complex background and solve the problem that the spatial pyramid pooling-fast module in the YOLOv5 network cannot handle multiscale targets, we introduced the convolutional block attention module attention mechanism and proposed the atrous spatial pyramid pooling with squeeze-and-excitation structure. In addition, we optimized the loss function of YOLOv5 by replacing the CIoU with EIoU. The experimental results showed that our algorithm achieved a precision of 0.872, recall of 0.854, and mean average precision@0.5 of 0.882 in detecting three main types of pavement damage: cracks, potholes, and patching. On the GPU, its frames per second reached 68, meeting the requirements for real-time detection. Its overall performance even exceeded the current more advanced YOLOv7 and achieved good results in practical applications, providing a basis for decision-making in pavement damage detection and prevention.
Prior Frequency Guided Diffusion Model for Limited Angle (LA)-CBCT Reconstruction
Apr 09, 2024Cone-beam computed tomography (CBCT) is widely used in image-guided radiotherapy. Reconstructing CBCTs from limited-angle acquisitions (LA-CBCT) is highly desired for improved imaging efficiency, dose reduction, and better mechanical clearance. LA-CBCT reconstruction, however, suffers from severe under-sampling artifacts, making it a highly ill-posed inverse problem. Diffusion models can generate data/images by reversing a data-noising process through learned data distributions; and can be incorporated as a denoiser/regularizer in LA-CBCT reconstruction. In this study, we developed a diffusion model-based framework, prior frequency-guided diffusion model (PFGDM), for robust and structure-preserving LA-CBCT reconstruction. PFGDM uses a conditioned diffusion model as a regularizer for LA-CBCT reconstruction, and the condition is based on high-frequency information extracted from patient-specific prior CT scans which provides a strong anatomical prior for LA-CBCT reconstruction. Specifically, we developed two variants of PFGDM (PFGDM-A and PFGDM-B) with different conditioning schemes. PFGDM-A applies the high-frequency CT information condition until a pre-optimized iteration step, and drops it afterwards to enable both similar and differing CT/CBCT anatomies to be reconstructed. PFGDM-B, on the other hand, continuously applies the prior CT information condition in every reconstruction step, while with a decaying mechanism, to gradually phase out the reconstruction guidance from the prior CT scans. The two variants of PFGDM were tested and compared with current available LA-CBCT reconstruction solutions, via metrics including PSNR and SSIM. PFGDM outperformed all traditional and diffusion model-based methods. PFGDM reconstructs high-quality LA-CBCTs under very-limited gantry angles, allowing faster and more flexible CBCT scans with dose reductions.
CFNet: Conditional Filter Learning with Dynamic Noise Estimation for Real Image Denoising
Nov 26, 2022



A mainstream type of the state of the arts (SOTAs) based on convolutional neural network (CNN) for real image denoising contains two sub-problems, i.e., noise estimation and non-blind denoising. This paper considers real noise approximated by heteroscedastic Gaussian/Poisson Gaussian distributions with in-camera signal processing pipelines. The related works always exploit the estimated noise prior via channel-wise concatenation followed by a convolutional layer with spatially sharing kernels. Due to the variable modes of noise strength and frequency details of all feature positions, this design cannot adaptively tune the corresponding denoising patterns. To address this problem, we propose a novel conditional filter in which the optimal kernels for different feature positions can be adaptively inferred by local features from the image and the noise map. Also, we bring the thought that alternatively performs noise estimation and non-blind denoising into CNN structure, which continuously updates noise prior to guide the iterative feature denoising. In addition, according to the property of heteroscedastic Gaussian distribution, a novel affine transform block is designed to predict the stationary noise component and the signal-dependent noise component. Compared with SOTAs, extensive experiments are conducted on five synthetic datasets and three real datasets, which shows the improvement of the proposed CFNet.