 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnidirectional Image Quality Captioning: A Large-scale Database and A New Model
Feb 21, 2025



The fast growing application of omnidirectional images calls for effective approaches for omnidirectional image quality assessment (OIQA). Existing OIQA methods have been developed and tested on homogeneously distorted omnidirectional images, but it is hard to transfer their success directly to the heterogeneously distorted omnidirectional images. In this paper, we conduct the largest study so far on OIQA, where we establish a large-scale database called OIQ-10K containing 10,000 omnidirectional images with both homogeneous and heterogeneous distortions. A comprehensive psychophysical study is elaborated to collect human opinions for each omnidirectional image, together with the spatial distributions (within local regions or globally) of distortions, and the head and eye movements of the subjects. Furthermore, we propose a novel multitask-derived adaptive feature-tailoring OIQA model named IQCaption360, which is capable of generating a quality caption for an omnidirectional image in a manner of textual template. Extensive experiments demonstrate the effectiveness of IQCaption360, which outperforms state-of-the-art methods by a significant margin on the proposed OIQ-10K database. The OIQ-10K database and the related source codes are available at https://github.com/WenJuing/IQCaption360.
Lesion-aware network for diabetic retinopathy diagnosis
Aug 14, 2024Deep learning brought boosts to auto diabetic retinopathy (DR) diagnosis, thus, greatly helping ophthalmologists for early disease detection, which contributes to preventing disease deterioration that may eventually lead to blindness. It has been proved that convolutional neural network (CNN)-aided lesion identifying or segmentation benefits auto DR screening. The key to fine-grained lesion tasks mainly lies in: (1) extracting features being both sensitive to tiny lesions and robust against DR-irrelevant interference, and (2) exploiting and re-using encoded information to restore lesion locations under extremely imbalanced data distribution. To this end, we propose a CNN-based DR diagnosis network with attention mechanism involved, termed lesion-aware network, to better capture lesion information from imbalanced data. Specifically, we design the lesion-aware module (LAM) to capture noise-like lesion areas across deeper layers, and the feature-preserve module (FPM) to assist shallow-to-deep feature fusion. Afterward, the proposed lesion-aware network (LANet) is constructed by embedding the LAM and FPM into the CNN decoders for DR-related information utilization. The proposed LANet is then further extended to a DR screening network by adding a classification layer. Through experiments on three public fundus datasets with pixel-level annotations, our method outperforms the mainstream methods with an area under curve of 0.967 in DR screening, and increases the overall average precision by 7.6%, 2.1%, and 1.2% in lesion segmentation on three datasets. Besides, the ablation study validates the effectiveness of the proposed sub-modules.
CFNet: Conditional Filter Learning with Dynamic Noise Estimation for Real Image Denoising
Nov 26, 2022



A mainstream type of the state of the arts (SOTAs) based on convolutional neural network (CNN) for real image denoising contains two sub-problems, i.e., noise estimation and non-blind denoising. This paper considers real noise approximated by heteroscedastic Gaussian/Poisson Gaussian distributions with in-camera signal processing pipelines. The related works always exploit the estimated noise prior via channel-wise concatenation followed by a convolutional layer with spatially sharing kernels. Due to the variable modes of noise strength and frequency details of all feature positions, this design cannot adaptively tune the corresponding denoising patterns. To address this problem, we propose a novel conditional filter in which the optimal kernels for different feature positions can be adaptively inferred by local features from the image and the noise map. Also, we bring the thought that alternatively performs noise estimation and non-blind denoising into CNN structure, which continuously updates noise prior to guide the iterative feature denoising. In addition, according to the property of heteroscedastic Gaussian distribution, a novel affine transform block is designed to predict the stationary noise component and the signal-dependent noise component. Compared with SOTAs, extensive experiments are conducted on five synthetic datasets and three real datasets, which shows the improvement of the proposed CFNet.
Anomaly Detection in Video Sequences: A Benchmark and Computational Model
Jun 16, 2021
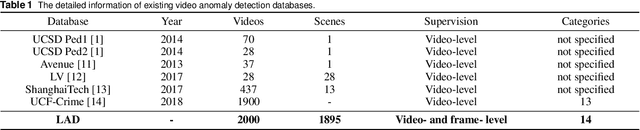


Anomaly detection has attracted considerable search attention. However, existing anomaly detection databases encounter two major problems. Firstly, they are limited in scale. Secondly, training sets contain only video-level labels indicating the existence of an abnormal event during the full video while lacking annotations of precise time durations. To tackle these problems, we contribute a new Large-scale Anomaly Detection (LAD) database as the benchmark for anomaly detection in video sequences, which is featured in two aspects. 1) It contains 2000 video sequences including normal and abnormal video clips with 14 anomaly categories including crash, fire, violence, etc. with large scene varieties, making it the largest anomaly analysis database to date. 2) It provides the annotation data, including video-level labels (abnormal/normal video, anomaly type) and frame-level labels (abnormal/normal video frame) to facilitate anomaly detection. Leveraging the above benefits from the LAD database, we further formulate anomaly detection as a fully-supervised learning problem and propose a multi-task deep neural network to solve it. We first obtain the local spatiotemporal contextual feature by using an Inflated 3D convolutional (I3D) network. Then we construct a recurrent convolutional neural network fed the local spatiotemporal contextual feature to extract the spatiotemporal contextual feature. With the global spatiotemporal contextual feature, the anomaly type and score can be computed simultaneously by a multi-task neural network. Experimental results show that the proposed method outperforms the state-of-the-art anomaly detection methods on our database and other public databases of anomaly detection. Codes are available at https://github.com/wanboyang/anomaly_detection_LAD2000.
Optimizing Region Selection for Weakly Supervised Object Detection
Aug 05, 2017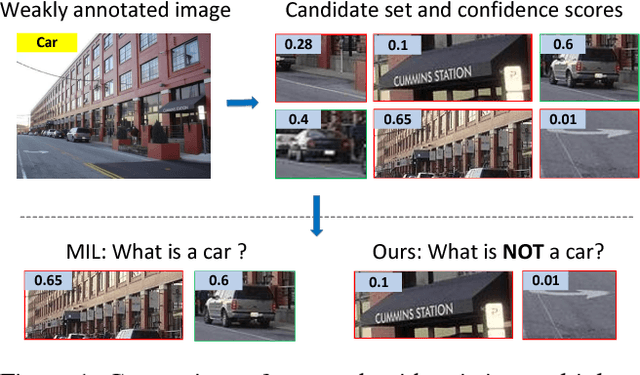

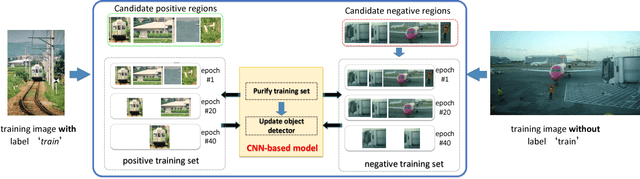
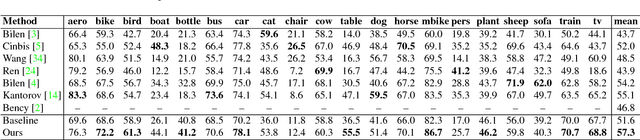
Training object detectors with only image-level annotations is very challenging because the target objects are often surrounded by a large number of background clutters. Many existing approaches tackle this problem through object proposal mining. However, the collected positive regions are either low in precision or lack of diversity, and the strategy of collecting negative regions is not carefully designed, neither. Moreover, training is often slow because region selection and object detector training are processed separately. In this context, the primary contribution of this work is to improve weakly supervised detection with an optimized region selection strategy. The proposed method collects purified positive training regions by progressively removing easy background clutters, and selects discriminative negative regions by mining class-specific hard samples. This region selection procedure is further integrated into a CNN-based weakly supervised detection (WSD) framework, and can be performed in each stochastic gradient descent mini-batch during training. Therefore, the entire model can be trained end-to-end efficiently. Extensive evaluation results on PASCAL VOC 2007, VOC 2010 and VOC 2012 datasets are presented which demonstrate that the proposed method effectively improves WSD.