 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotNet: An Image Centric, Lidar Anchored Approach To Long Range Perception
May 24, 2024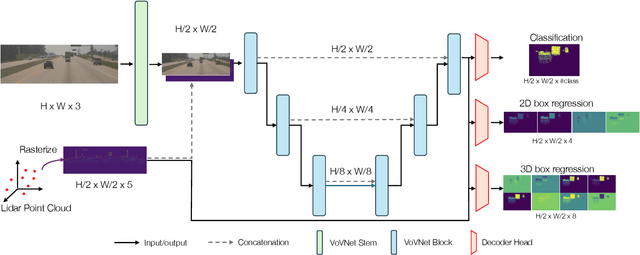

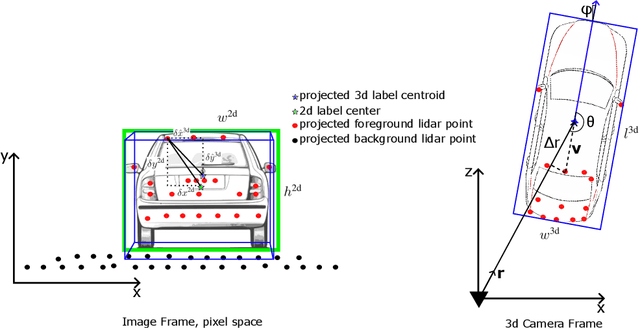

In this paper, we propose SpotNet: a fast, single stage, image-centric but LiDAR anchored approach for long range 3D object detection. We demonstrate that our approach to LiDAR/image sensor fusion, combined with the joint learning of 2D and 3D detection tasks, can lead to accurate 3D object detection with very sparse LiDAR support. Unlike more recent bird's-eye-view (BEV) sensor-fusion methods which scale with range $r$ as $O(r^2)$, SpotNet scales as $O(1)$ with range. We argue that such an architecture is ideally suited to leverage each sensor's strength, i.e. semantic understanding from images and accurate range finding from LiDAR data. Finally we show that anchoring detections on LiDAR points removes the need to regress distances, and so the architecture is able to transfer from 2MP to 8MP resolution images without re-training.
Brain Tumor Segmentation and Tractographic Feature Extraction from Structural MR Images for Overall Survival Prediction
Oct 10, 2018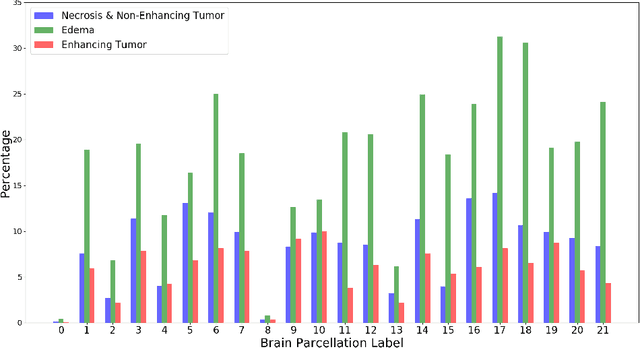
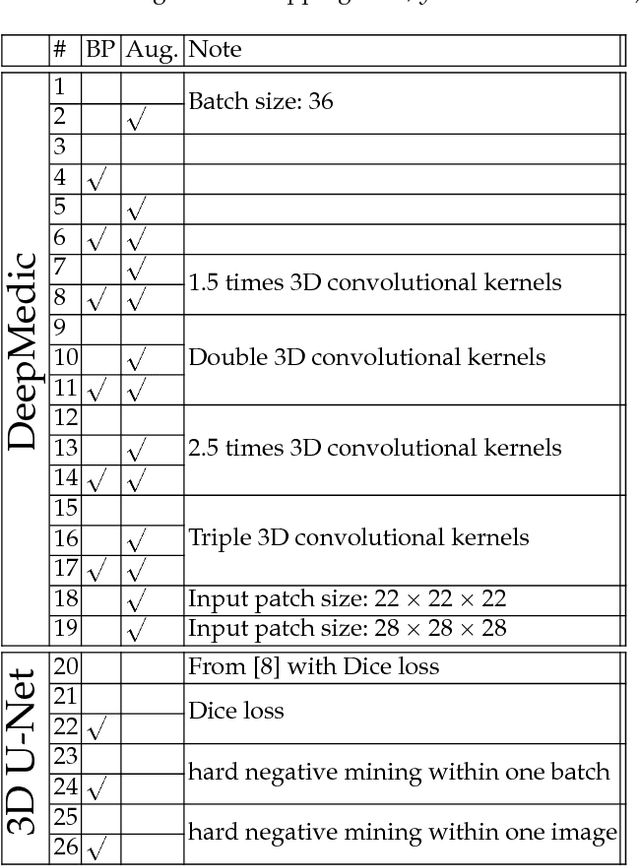
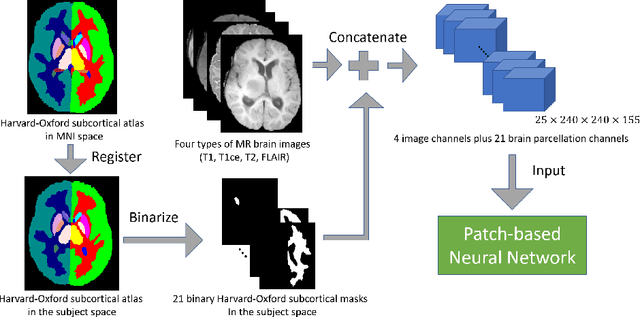

This paper introduces a novel methodology to integrate human brain connectomics and parcellation for brain tumor segmentation and survival prediction. For segmentation, we utilize an existing brain parcellation atlas in the MNI152 1mm space and map this parcellation to each individual subject data. We use deep neural network architectures together with hard negative mining to achieve the final voxel level classification. For survival prediction, we present a new method for combining features from connectomics data, brain parcellation information, and the brain tumor mask. We leverage the average connectome information from the Human Connectome Project and map each subject brain volume onto this common connectome space. From this, we compute tractographic features that describe potential neural disruptions due to the brain tumor. These features are then used to predict the overall survival of the subjects. The main novelty in the proposed methods is the use of normalized brain parcellation data and tractography data from the human connectome project for analyzing MR images for segmentation and survival prediction. Experimental results are reported on the BraTS2018 data.
Optimizing Region Selection for Weakly Supervised Object Detection
Aug 05, 2017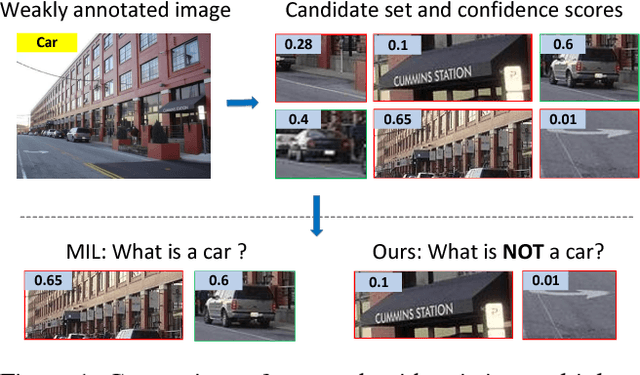

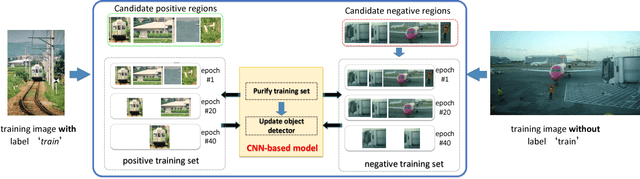
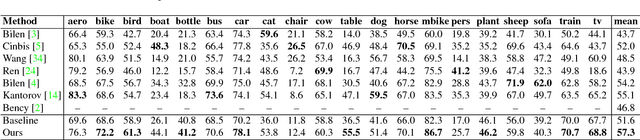
Training object detectors with only image-level annotations is very challenging because the target objects are often surrounded by a large number of background clutters. Many existing approaches tackle this problem through object proposal mining. However, the collected positive regions are either low in precision or lack of diversity, and the strategy of collecting negative regions is not carefully designed, neither. Moreover, training is often slow because region selection and object detector training are processed separately. In this context, the primary contribution of this work is to improve weakly supervised detection with an optimized region selection strategy. The proposed method collects purified positive training regions by progressively removing easy background clutters, and selects discriminative negative regions by mining class-specific hard samples. This region selection procedure is further integrated into a CNN-based weakly supervised detection (WSD) framework, and can be performed in each stochastic gradient descent mini-batch during training. Therefore, the entire model can be trained end-to-end efficiently. Extensive evaluation results on PASCAL VOC 2007, VOC 2010 and VOC 2012 datasets are presented which demonstrate that the proposed method effectively improves WSD.