 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Efficient Low Light Image Enhancement: Methods and Results
May 04, 2026This paper presents a comprehensive review of the NITRE 2026 Efficient Low Light Image Enhancement (E-LLIE) Challenge, highlighting the proposed solutions and final outcomes. This challenge focuses on mobile image enhancement under low-light conditions, aiming to design lightweight networks that improve enhancement quality while ensuring practical deployability under limited computational resources. A total of 207 participants registered, 27 teams submitted valid entries, and 17 teams ultimately provided valid factsheet. Based on these submissions, this paper provides a systematic evaluation of recent methods for E-LLIE, offering a comprehensive overview of state-of-the-art progress and demonstrating significant improvements in both performance and efficiency.
Diffusion-based Facial Aesthetics Enhancement with 3D Structure Guidance
Mar 18, 2025Facial Aesthetics Enhancement (FAE) aims to improve facial attractiveness by adjusting the structure and appearance of a facial image while preserving its identity as much as possible. Most existing methods adopted deep feature-based or score-based guidance for generation models to conduct FAE. Although these methods achieved promising results, they potentially produced excessively beautified results with lower identity consistency or insufficiently improved facial attractiveness. To enhance facial aesthetics with less loss of identity, we propose the Nearest Neighbor Structure Guidance based on Diffusion (NNSG-Diffusion), a diffusion-based FAE method that beautifies a 2D facial image with 3D structure guidance. Specifically, we propose to extract FAE guidance from a nearest neighbor reference face. To allow for less change of facial structures in the FAE process, a 3D face model is recovered by referring to both the matched 2D reference face and the 2D input face, so that the depth and contour guidance can be extracted from the 3D face model. Then the depth and contour clues can provide effective guidance to Stable Diffusion with ControlNet for FAE. Extensive experiments demonstrate that our method is superior to previous relevant methods in enhancing facial aesthetics while preserving facial identity.
Viewport-Unaware Blind Omnidirectional Image Quality Assessment: A Flexible and Effective Paradigm
Mar 08, 2025Most of existing blind omnidirectional image quality assessment (BOIQA) models rely on viewport generation by modeling user viewing behavior or transforming omnidirectional images (OIs) into varying formats; however, these methods are either computationally expensive or less scalable. To solve these issues, in this paper, we present a flexible and effective paradigm, which is viewport-unaware and can be easily adapted to 2D plane image quality assessment (2D-IQA). Specifically, the proposed BOIQA model includes an adaptive prior-equator sampling module for extracting a patch sequence from the equirectangular projection (ERP) image in a resolution-agnostic manner, a progressive deformation-unaware feature fusion module which is able to capture patch-wise quality degradation in a deformation-immune way, and a local-to-global quality aggregation module to adaptively map local perception to global quality. Extensive experiments across four OIQA databases (including uniformly distorted OIs and non-uniformly distorted OIs) demonstrate that the proposed model achieves competitive performance with low complexity against other state-of-the-art models, and we also verify its adaptive capacity to 2D-IQA.
Computational Analysis of Degradation Modeling in Blind Panoramic Image Quality Assessment
Mar 05, 2025



Blind panoramic image quality assessment (BPIQA) has recently brought new challenge to the visual quality community, due to the complex interaction between immersive content and human behavior. Although many efforts have been made to advance BPIQA from both conducting psychophysical experiments and designing performance-driven objective algorithms, \textit{limited content} and \textit{few samples} in those closed sets inevitably would result in shaky conclusions, thereby hindering the development of BPIQA, we refer to it as the \textit{easy-database} issue. In this paper, we present a sufficient computational analysis of degradation modeling in BPIQA to thoroughly explore the \textit{easy-database issue}, where we carefully design three types of experiments via investigating the gap between BPIQA and blind image quality assessment (BIQA), the necessity of specific design in BPIQA models, and the generalization ability of BPIQA models. From extensive experiments, we find that easy databases narrow the gap between the performance of BPIQA and BIQA models, which is unconducive to the development of BPIQA. And the easy databases make the BPIQA models be closed to saturation, therefore the effectiveness of the associated specific designs can not be well verified. Besides, the BPIQA models trained on our recently proposed databases with complicated degradation show better generalization ability. Thus, we believe that much more efforts are highly desired to put into BPIQA from both subjective viewpoint and objective viewpoint.
Max360IQ: Blind Omnidirectional Image Quality Assessment with Multi-axis Attention
Feb 26, 2025Omnidirectional image, also called 360-degree image, is able to capture the entire 360-degree scene, thereby providing more realistic immersive feelings for users than general 2D image and stereoscopic image. Meanwhile, this feature brings great challenges to measuring the perceptual quality of omnidirectional images, which is closely related to users' quality of experience, especially when the omnidirectional images suffer from non-uniform distortion. In this paper, we propose a novel and effective blind omnidirectional image quality assessment (BOIQA) model with multi-axis attention (Max360IQ), which can proficiently measure not only the quality of uniformly distorted omnidirectional images but also the quality of non-uniformly distorted omnidirectional images. Specifically, the proposed Max360IQ is mainly composed of a backbone with stacked multi-axis attention modules for capturing both global and local spatial interactions of extracted viewports, a multi-scale feature integration (MSFI) module to fuse multi-scale features and a quality regression module with deep semantic guidance for predicting the quality of omnidirectional images. Experimental results demonstrate that the proposed Max360IQ outperforms the state-of-the-art Assessor360 by 3.6\% in terms of SRCC on the JUFE database with non-uniform distortion, and gains improvement of 0.4\% and 0.8\% in terms of SRCC on the OIQA and CVIQ databases, respectively. The source code is available at https://github.com/WenJuing/Max360IQ.
Omnidirectional Image Quality Captioning: A Large-scale Database and A New Model
Feb 21, 2025



The fast growing application of omnidirectional images calls for effective approaches for omnidirectional image quality assessment (OIQA). Existing OIQA methods have been developed and tested on homogeneously distorted omnidirectional images, but it is hard to transfer their success directly to the heterogeneously distorted omnidirectional images. In this paper, we conduct the largest study so far on OIQA, where we establish a large-scale database called OIQ-10K containing 10,000 omnidirectional images with both homogeneous and heterogeneous distortions. A comprehensive psychophysical study is elaborated to collect human opinions for each omnidirectional image, together with the spatial distributions (within local regions or globally) of distortions, and the head and eye movements of the subjects. Furthermore, we propose a novel multitask-derived adaptive feature-tailoring OIQA model named IQCaption360, which is capable of generating a quality caption for an omnidirectional image in a manner of textual template. Extensive experiments demonstrate the effectiveness of IQCaption360, which outperforms state-of-the-art methods by a significant margin on the proposed OIQ-10K database. The OIQ-10K database and the related source codes are available at https://github.com/WenJuing/IQCaption360.
Multitask Auxiliary Network for Perceptual Quality Assessment of Non-Uniformly Distorted Omnidirectional Images
Jan 20, 2025Omnidirectional image quality assessment (OIQA) has been widely investigated in the past few years and achieved much success. However, most of existing studies are dedicated to solve the uniform distortion problem in OIQA, which has a natural gap with the non-uniform distortion problem, and their ability in capturing non-uniform distortion is far from satisfactory. To narrow this gap, in this paper, we propose a multitask auxiliary network for non-uniformly distorted omnidirectional images, where the parameters are optimized by jointly training the main task and other auxiliary tasks. The proposed network mainly consists of three parts: a backbone for extracting multiscale features from the viewport sequence, a multitask feature selection module for dynamically allocating specific features to different tasks, and auxiliary sub-networks for guiding the proposed model to capture local distortion and global quality change. Extensive experiments conducted on two large-scale OIQA databases demonstrate that the proposed model outperforms other state-of-the-art OIQA metrics, and these auxiliary sub-networks contribute to improve the performance of the proposed model. The source code is available at https://github.com/RJL2000/MTAOIQA.
Video Quality Assessment for Online Processing: From Spatial to Temporal Sampling
Jan 13, 2025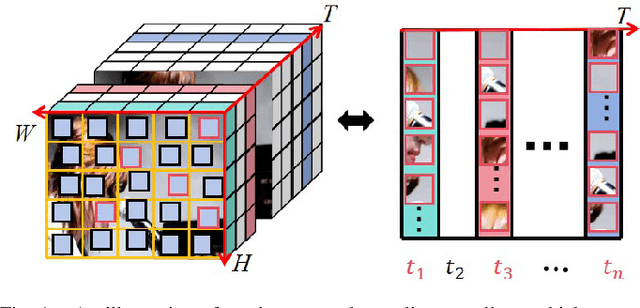
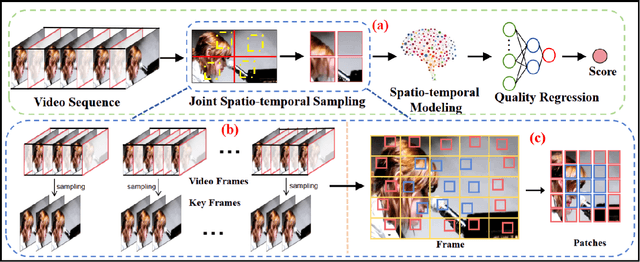
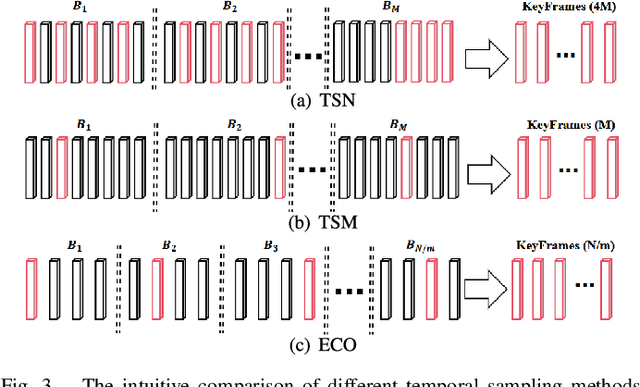
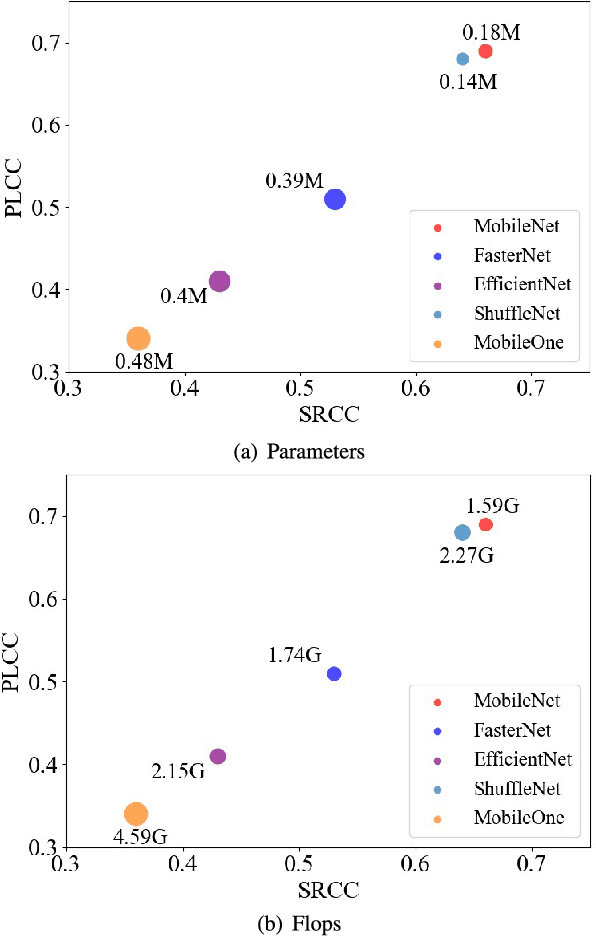
With the rapid development of multimedia processing and deep learning technologies, especially in the field of video understanding, video quality assessment (VQA) has achieved significant progress. Although researchers have moved from designing efficient video quality mapping models to various research directions, in-depth exploration of the effectiveness-efficiency trade-offs of spatio-temporal modeling in VQA models is still less sufficient. Considering the fact that videos have highly redundant information, this paper investigates this problem from the perspective of joint spatial and temporal sampling, aiming to seek the answer to how little information we should keep at least when feeding videos into the VQA models while with acceptable performance sacrifice. To this end, we drastically sample the video's information from both spatial and temporal dimensions, and the heavily squeezed video is then fed into a stable VQA model. Comprehensive experiments regarding joint spatial and temporal sampling are conducted on six public video quality databases, and the results demonstrate the acceptable performance of the VQA model when throwing away most of the video information. Furthermore, with the proposed joint spatial and temporal sampling strategy, we make an initial attempt to design an online VQA model, which is instantiated by as simple as possible a spatial feature extractor, a temporal feature fusion module, and a global quality regression module. Through quantitative and qualitative experiments, we verify the feasibility of online VQA model by simplifying itself and reducing input.
Meta-Point Learning and Refining for Category-Agnostic Pose Estimation
Mar 20, 2024



Category-agnostic pose estimation (CAPE) aims to predict keypoints for arbitrary classes given a few support images annotated with keypoints. Existing methods only rely on the features extracted at support keypoints to predict or refine the keypoints on query image, but a few support feature vectors are local and inadequate for CAPE. Considering that human can quickly perceive potential keypoints of arbitrary objects, we propose a novel framework for CAPE based on such potential keypoints (named as meta-points). Specifically, we maintain learnable embeddings to capture inherent information of various keypoints, which interact with image feature maps to produce meta-points without any support. The produced meta-points could serve as meaningful potential keypoints for CAPE. Due to the inevitable gap between inherency and annotation, we finally utilize the identities and details offered by support keypoints to assign and refine meta-points to desired keypoints in query image. In addition, we propose a progressive deformable point decoder and a slacked regression loss for better prediction and supervision. Our novel framework not only reveals the inherency of keypoints but also outperforms existing methods of CAPE. Comprehensive experiments and in-depth studies on large-scale MP-100 dataset demonstrate the effectiveness of our framework.
Perceptually Optimized Deep High-Dynamic-Range Image Tone Mapping
Sep 02, 2021
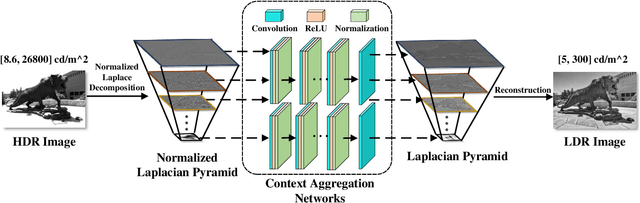


We describe a deep high-dynamic-range (HDR) image tone mapping operator that is computationally efficient and perceptually optimized. We first decompose an HDR image into a normalized Laplacian pyramid, and use two deep neural networks (DNNs) to estimate the Laplacian pyramid of the desired tone-mapped image from the normalized representation. We then end-to-end optimize the entire method over a database of HDR images by minimizing the normalized Laplacian pyramid distance (NLPD), a recently proposed perceptual metric. Qualitative and quantitative experiments demonstrate that our method produces images with better visual quality, and runs the fastest among existing local tone mapping algorithms.