 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
Robust sensor fusion against on-vehicle sensor staleness
Jun 06, 2025Sensor fusion is crucial for a performant and robust Perception system in autonomous vehicles, but sensor staleness, where data from different sensors arrives with varying delays, poses significant challenges. Temporal misalignment between sensor modalities leads to inconsistent object state estimates, severely degrading the quality of trajectory predictions that are critical for safety. We present a novel and model-agnostic approach to address this problem via (1) a per-point timestamp offset feature (for LiDAR and radar both relative to camera) that enables fine-grained temporal awareness in sensor fusion, and (2) a data augmentation strategy that simulates realistic sensor staleness patterns observed in deployed vehicles. Our method is integrated into a perspective-view detection model that consumes sensor data from multiple LiDARs, radars and cameras. We demonstrate that while a conventional model shows significant regressions when one sensor modality is stale, our approach reaches consistently good performance across both synchronized and stale conditions.
Recurrent Feature Mining and Keypoint Mixup Padding for Category-Agnostic Pose Estimation
Mar 27, 2025



Category-agnostic pose estimation aims to locate keypoints on query images according to a few annotated support images for arbitrary novel classes. Existing methods generally extract support features via heatmap pooling, and obtain interacted features from support and query via cross-attention. Hence, these works neglect to mine fine-grained and structure-aware (FGSA) features from both support and query images, which are crucial for pixel-level keypoint localization. To this end, we propose a novel yet concise framework, which recurrently mines FGSA features from both support and query images. Specifically, we design a FGSA mining module based on deformable attention mechanism. On the one hand, we mine fine-grained features by applying deformable attention head over multi-scale feature maps. On the other hand, we mine structure-aware features by offsetting the reference points of keypoints to their linked keypoints. By means of above module, we recurrently mine FGSA features from support and query images, and thus obtain better support features and query estimations. In addition, we propose to use mixup keypoints to pad various classes to a unified keypoint number, which could provide richer supervision than the zero padding used in existing works. We conduct extensive experiments and in-depth studies on large-scale MP-100 dataset, and outperform SOTA method dramatically (+3.2\%PCK@0.05). Code is avaiable at https://github.com/chenbys/FMMP.
Computational Analysis of Degradation Modeling in Blind Panoramic Image Quality Assessment
Mar 05, 2025



Blind panoramic image quality assessment (BPIQA) has recently brought new challenge to the visual quality community, due to the complex interaction between immersive content and human behavior. Although many efforts have been made to advance BPIQA from both conducting psychophysical experiments and designing performance-driven objective algorithms, \textit{limited content} and \textit{few samples} in those closed sets inevitably would result in shaky conclusions, thereby hindering the development of BPIQA, we refer to it as the \textit{easy-database} issue. In this paper, we present a sufficient computational analysis of degradation modeling in BPIQA to thoroughly explore the \textit{easy-database issue}, where we carefully design three types of experiments via investigating the gap between BPIQA and blind image quality assessment (BIQA), the necessity of specific design in BPIQA models, and the generalization ability of BPIQA models. From extensive experiments, we find that easy databases narrow the gap between the performance of BPIQA and BIQA models, which is unconducive to the development of BPIQA. And the easy databases make the BPIQA models be closed to saturation, therefore the effectiveness of the associated specific designs can not be well verified. Besides, the BPIQA models trained on our recently proposed databases with complicated degradation show better generalization ability. Thus, we believe that much more efforts are highly desired to put into BPIQA from both subjective viewpoint and objective viewpoint.
Max360IQ: Blind Omnidirectional Image Quality Assessment with Multi-axis Attention
Feb 26, 2025Omnidirectional image, also called 360-degree image, is able to capture the entire 360-degree scene, thereby providing more realistic immersive feelings for users than general 2D image and stereoscopic image. Meanwhile, this feature brings great challenges to measuring the perceptual quality of omnidirectional images, which is closely related to users' quality of experience, especially when the omnidirectional images suffer from non-uniform distortion. In this paper, we propose a novel and effective blind omnidirectional image quality assessment (BOIQA) model with multi-axis attention (Max360IQ), which can proficiently measure not only the quality of uniformly distorted omnidirectional images but also the quality of non-uniformly distorted omnidirectional images. Specifically, the proposed Max360IQ is mainly composed of a backbone with stacked multi-axis attention modules for capturing both global and local spatial interactions of extracted viewports, a multi-scale feature integration (MSFI) module to fuse multi-scale features and a quality regression module with deep semantic guidance for predicting the quality of omnidirectional images. Experimental results demonstrate that the proposed Max360IQ outperforms the state-of-the-art Assessor360 by 3.6\% in terms of SRCC on the JUFE database with non-uniform distortion, and gains improvement of 0.4\% and 0.8\% in terms of SRCC on the OIQA and CVIQ databases, respectively. The source code is available at https://github.com/WenJuing/Max360IQ.
PSReg: Prior-guided Sparse Mixture of Experts for Point Cloud Registration
Jan 14, 2025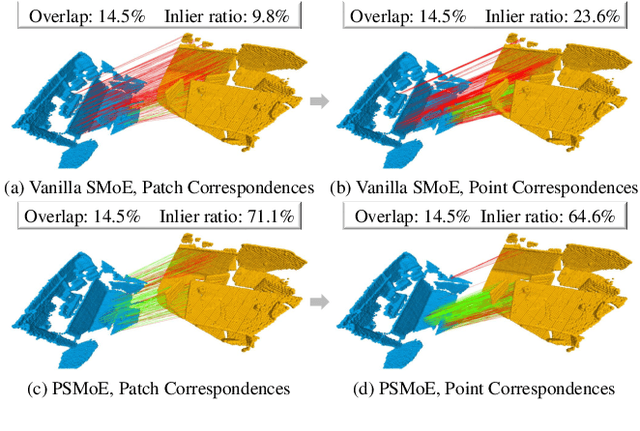
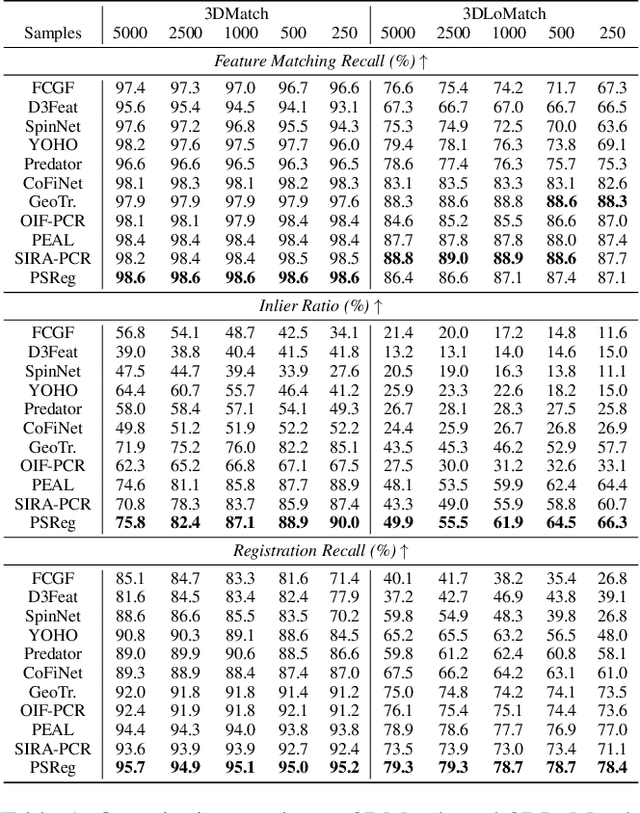

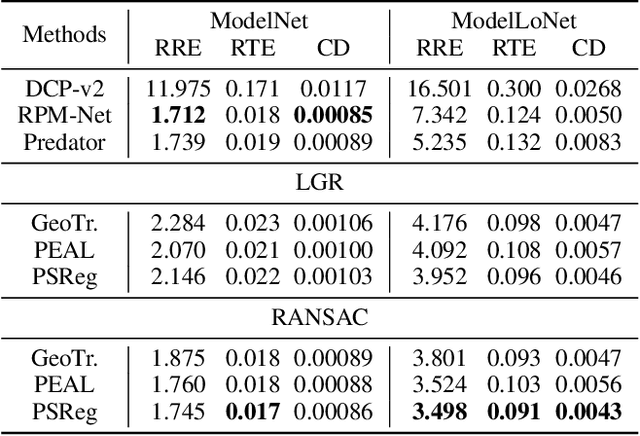
The discriminative feature is crucial for point cloud registration. Recent methods improve the feature discriminative by distinguishing between non-overlapping and overlapping region points. However, they still face challenges in distinguishing the ambiguous structures in the overlapping regions. Therefore, the ambiguous features they extracted resulted in a significant number of outlier matches from overlapping regions. To solve this problem, we propose a prior-guided SMoE-based registration method to improve the feature distinctiveness by dispatching the potential correspondences to the same experts. Specifically, we propose a prior-guided SMoE module by fusing prior overlap and potential correspondence embeddings for routing, assigning tokens to the most suitable experts for processing. In addition, we propose a registration framework by a specific combination of Transformer layer and prior-guided SMoE module. The proposed method not only pays attention to the importance of locating the overlapping areas of point clouds, but also commits to finding more accurate correspondences in overlapping areas. Our extensive experiments demonstrate the effectiveness of our method, achieving state-of-the-art registration recall (95.7\%/79.3\%) on the 3DMatch/3DLoMatch benchmark. Moreover, we also test the performance on ModelNet40 and demonstrate excellent performance.
GSTran: Joint Geometric and Semantic Coherence for Point Cloud Segmentation
Aug 21, 2024



Learning meaningful local and global information remains a challenge in point cloud segmentation tasks. When utilizing local information, prior studies indiscriminately aggregates neighbor information from different classes to update query points, potentially compromising the distinctive feature of query points. In parallel, inaccurate modeling of long-distance contextual dependencies when utilizing global information can also impact model performance. To address these issues, we propose GSTran, a novel transformer network tailored for the segmentation task. The proposed network mainly consists of two principal components: a local geometric transformer and a global semantic transformer. In the local geometric transformer module, we explicitly calculate the geometric disparity within the local region. This enables amplifying the affinity with geometrically similar neighbor points while suppressing the association with other neighbors. In the global semantic transformer module, we design a multi-head voting strategy. This strategy evaluates semantic similarity across the entire spatial range, facilitating the precise capture of contextual dependencies. Experiments on ShapeNetPart and S3DIS benchmarks demonstrate the effectiveness of the proposed method, showing its superiority over other algorithms. The code is available at https://github.com/LAB123-tech/GSTran.
Frozen CLIP Model is An Efficient Point Cloud Backbone
Dec 09, 2022The pretraining-finetuning paradigm has demonstrated great success in NLP and 2D image fields because of the high-quality representation ability and transferability of their pretrained models. However, pretraining such a strong model is difficult in the 3D point cloud field since the training data is limited and point cloud collection is expensive. This paper introduces Efficient Point Cloud Learning (EPCL), an effective and efficient point cloud learner for directly training high-quality point cloud models with a frozen CLIP model. Our EPCL connects the 2D and 3D modalities by semantically aligning the 2D features and point cloud features without paired 2D-3D data. Specifically, the input point cloud is divided into a sequence of tokens and directly fed into the frozen CLIP model to learn point cloud representation. Furthermore, we design a task token to narrow the gap between 2D images and 3D point clouds. Comprehensive experiments on 3D detection, semantic segmentation, classification and few-shot learning demonstrate that the 2D CLIP model can be an efficient point cloud backbone and our method achieves state-of-the-art accuracy on both real-world and synthetic downstream tasks. Code will be available.
CFNet: Conditional Filter Learning with Dynamic Noise Estimation for Real Image Denoising
Nov 26, 2022



A mainstream type of the state of the arts (SOTAs) based on convolutional neural network (CNN) for real image denoising contains two sub-problems, i.e., noise estimation and non-blind denoising. This paper considers real noise approximated by heteroscedastic Gaussian/Poisson Gaussian distributions with in-camera signal processing pipelines. The related works always exploit the estimated noise prior via channel-wise concatenation followed by a convolutional layer with spatially sharing kernels. Due to the variable modes of noise strength and frequency details of all feature positions, this design cannot adaptively tune the corresponding denoising patterns. To address this problem, we propose a novel conditional filter in which the optimal kernels for different feature positions can be adaptively inferred by local features from the image and the noise map. Also, we bring the thought that alternatively performs noise estimation and non-blind denoising into CNN structure, which continuously updates noise prior to guide the iterative feature denoising. In addition, according to the property of heteroscedastic Gaussian distribution, a novel affine transform block is designed to predict the stationary noise component and the signal-dependent noise component. Compared with SOTAs, extensive experiments are conducted on five synthetic datasets and three real datasets, which shows the improvement of the proposed CFNet.
GMF: General Multimodal Fusion Framework for Correspondence Outlier Rejection
Nov 01, 2022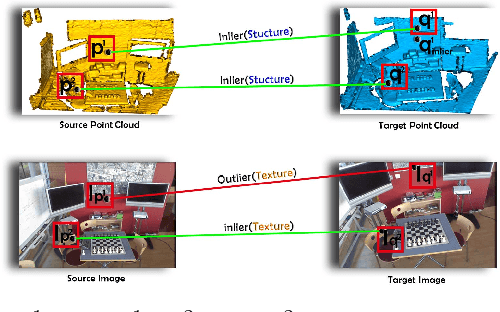
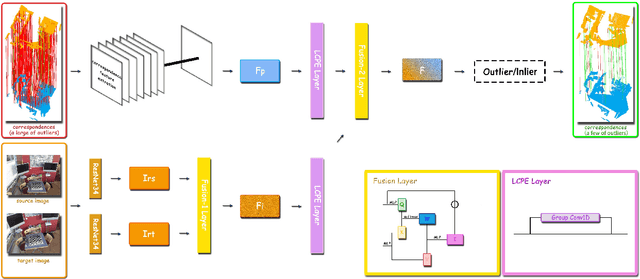
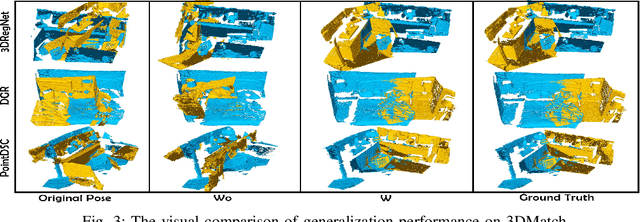
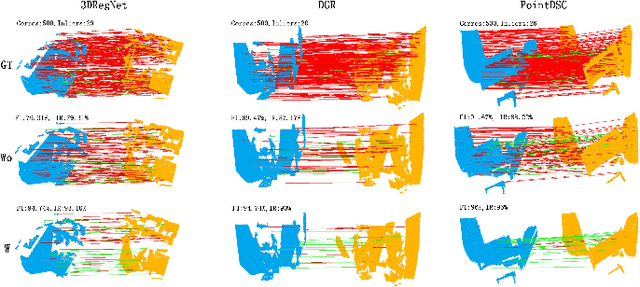
Rejecting correspondence outliers enables to boost the correspondence quality, which is a critical step in achieving high point cloud registration accuracy. The current state-of-the-art correspondence outlier rejection methods only utilize the structure features of the correspondences. However, texture information is critical to reject the correspondence outliers in our human vision system. In this paper, we propose General Multimodal Fusion (GMF) to learn to reject the correspondence outliers by leveraging both the structure and texture information. Specifically, two cross-attention-based fusion layers are proposed to fuse the texture information from paired images and structure information from point correspondences. Moreover, we propose a convolutional position encoding layer to enhance the difference between Tokens and enable the encoding feature pay attention to neighbor information. Our position encoding layer will make the cross-attention operation integrate both local and global information. Experiments on multiple datasets(3DMatch, 3DLoMatch, KITTI) and recent state-of-the-art models (3DRegNet, DGR, PointDSC) prove that our GMF achieves wide generalization ability and consistently improves the point cloud registration accuracy. Furthermore, several ablation studies demonstrate the robustness of the proposed GMF on different loss functions, lighting conditions and noises.The code is available at https://github.com/XiaoshuiHuang/GMF.