 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMF: General Multimodal Fusion Framework for Correspondence Outlier Rejection
Paper and Code
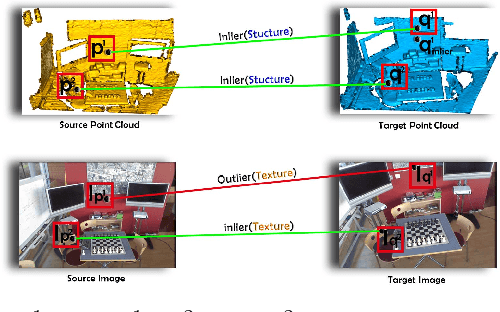
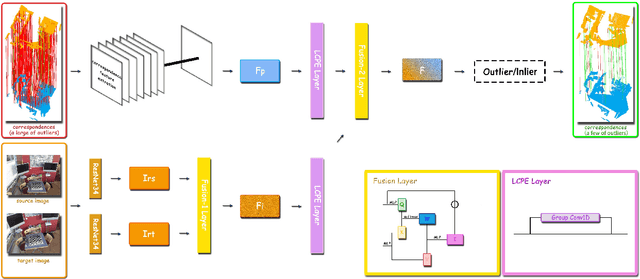
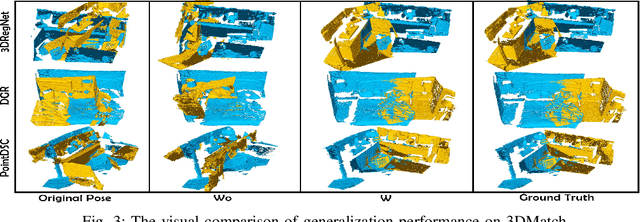
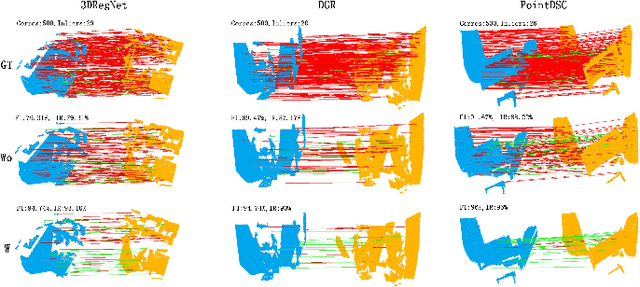
Rejecting correspondence outliers enables to boost the correspondence quality, which is a critical step in achieving high point cloud registration accuracy. The current state-of-the-art correspondence outlier rejection methods only utilize the structure features of the correspondences. However, texture information is critical to reject the correspondence outliers in our human vision system. In this paper, we propose General Multimodal Fusion (GMF) to learn to reject the correspondence outliers by leveraging both the structure and texture information. Specifically, two cross-attention-based fusion layers are proposed to fuse the texture information from paired images and structure information from point correspondences. Moreover, we propose a convolutional position encoding layer to enhance the difference between Tokens and enable the encoding feature pay attention to neighbor information. Our position encoding layer will make the cross-attention operation integrate both local and global information. Experiments on multiple datasets(3DMatch, 3DLoMatch, KITTI) and recent state-of-the-art models (3DRegNet, DGR, PointDSC) prove that our GMF achieves wide generalization ability and consistently improves the point cloud registration accuracy. Furthermore, several ablation studies demonstrate the robustness of the proposed GMF on different loss functions, lighting conditions and noises.The code is available at https://github.com/XiaoshuiHuang/GMF.