 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Robust Point Cloud Semantic Segmentation Network with Single-Step Conditional Diffusion Models
Nov 25, 2024



Existing conditional Denoising Diffusion Probabilistic Models (DDPMs) with a Noise-Conditional Framework (NCF) remain challenging for 3D scene understanding tasks, as the complex geometric details in scenes increase the difficulty of fitting the gradients of the data distribution (the scores) from semantic labels. This also results in longer training and inference time for DDPMs compared to non-DDPMs. From a different perspective, we delve deeply into the model paradigm dominated by the Conditional Network. In this paper, we propose an end-to-end robust semantic \textbf{Seg}mentation \textbf{Net}work based on a \textbf{C}onditional-Noise Framework (CNF) of D\textbf{D}PMs, named \textbf{CDSegNet}. Specifically, CDSegNet models the Noise Network (NN) as a learnable noise-feature generator. This enables the Conditional Network (CN) to understand 3D scene semantics under multi-level feature perturbations, enhancing the generalization in unseen scenes. Meanwhile, benefiting from the noise system of DDPMs, CDSegNet exhibits strong noise and sparsity robustness in experiments. Moreover, thanks to CNF, CDSegNet can generate the semantic labels in a single-step inference like non-DDPMs, due to avoiding directly fitting the scores from semantic labels in the dominant network of CDSegNet. On public indoor and outdoor benchmarks, CDSegNet significantly outperforms existing methods, achieving state-of-the-art performance.
A Conditional Denoising Diffusion Probabilistic Model for Point Cloud Upsampling
Dec 03, 2023



Point cloud upsampling (PCU) enriches the representation of raw point clouds, significantly improving the performance in downstream tasks such as classification and reconstruction. Most of the existing point cloud upsampling methods focus on sparse point cloud feature extraction and upsampling module design. In a different way, we dive deeper into directly modelling the gradient of data distribution from dense point clouds. In this paper, we proposed a conditional denoising diffusion probability model (DDPM) for point cloud upsampling, called PUDM. Specifically, PUDM treats the sparse point cloud as a condition, and iteratively learns the transformation relationship between the dense point cloud and the noise. Simultaneously, PUDM aligns with a dual mapping paradigm to further improve the discernment of point features. In this context, PUDM enables learning complex geometry details in the ground truth through the dominant features, while avoiding an additional upsampling module design. Furthermore, to generate high-quality arbitrary-scale point clouds during inference, PUDM exploits the prior knowledge of the scale between sparse point clouds and dense point clouds during training by parameterizing a rate factor. Moreover, PUDM exhibits strong noise robustness in experimental results. In the quantitative and qualitative evaluations on PU1K and PUGAN, PUDM significantly outperformed existing methods in terms of Chamfer Distance (CD) and Hausdorff Distance (HD), achieving state of the art (SOTA) performance.
Frozen CLIP Model is An Efficient Point Cloud Backbone
Dec 09, 2022The pretraining-finetuning paradigm has demonstrated great success in NLP and 2D image fields because of the high-quality representation ability and transferability of their pretrained models. However, pretraining such a strong model is difficult in the 3D point cloud field since the training data is limited and point cloud collection is expensive. This paper introduces Efficient Point Cloud Learning (EPCL), an effective and efficient point cloud learner for directly training high-quality point cloud models with a frozen CLIP model. Our EPCL connects the 2D and 3D modalities by semantically aligning the 2D features and point cloud features without paired 2D-3D data. Specifically, the input point cloud is divided into a sequence of tokens and directly fed into the frozen CLIP model to learn point cloud representation. Furthermore, we design a task token to narrow the gap between 2D images and 3D point clouds. Comprehensive experiments on 3D detection, semantic segmentation, classification and few-shot learning demonstrate that the 2D CLIP model can be an efficient point cloud backbone and our method achieves state-of-the-art accuracy on both real-world and synthetic downstream tasks. Code will be available.
GMF: General Multimodal Fusion Framework for Correspondence Outlier Rejection
Nov 01, 2022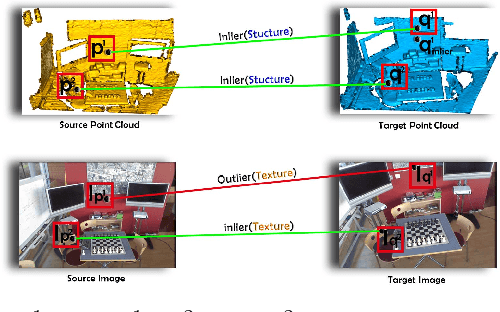
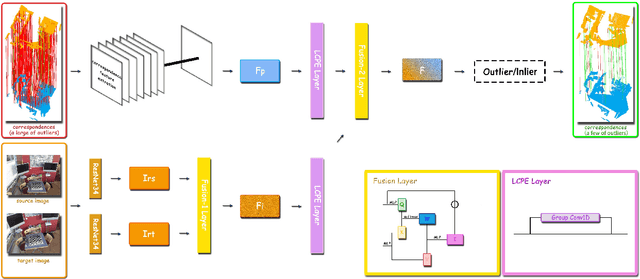
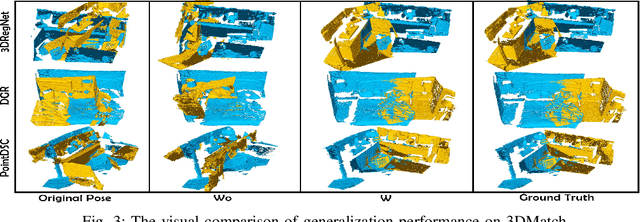
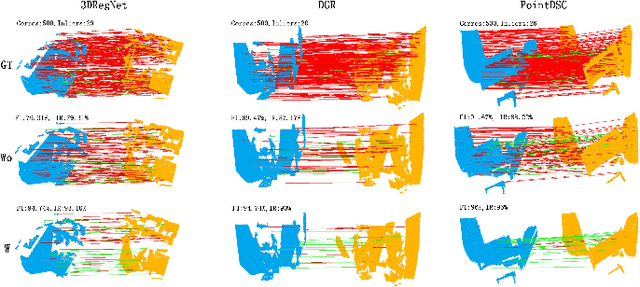
Rejecting correspondence outliers enables to boost the correspondence quality, which is a critical step in achieving high point cloud registration accuracy. The current state-of-the-art correspondence outlier rejection methods only utilize the structure features of the correspondences. However, texture information is critical to reject the correspondence outliers in our human vision system. In this paper, we propose General Multimodal Fusion (GMF) to learn to reject the correspondence outliers by leveraging both the structure and texture information. Specifically, two cross-attention-based fusion layers are proposed to fuse the texture information from paired images and structure information from point correspondences. Moreover, we propose a convolutional position encoding layer to enhance the difference between Tokens and enable the encoding feature pay attention to neighbor information. Our position encoding layer will make the cross-attention operation integrate both local and global information. Experiments on multiple datasets(3DMatch, 3DLoMatch, KITTI) and recent state-of-the-art models (3DRegNet, DGR, PointDSC) prove that our GMF achieves wide generalization ability and consistently improves the point cloud registration accuracy. Furthermore, several ablation studies demonstrate the robustness of the proposed GMF on different loss functions, lighting conditions and noises.The code is available at https://github.com/XiaoshuiHuang/GMF.
IMFNet: Interpretable Multimodal Fusion for Point Cloud Registration
Nov 18, 2021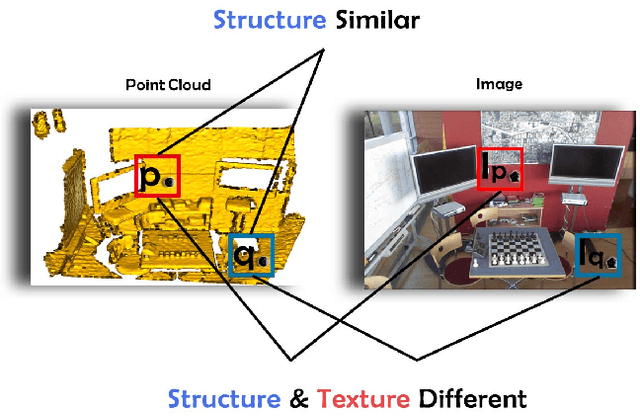
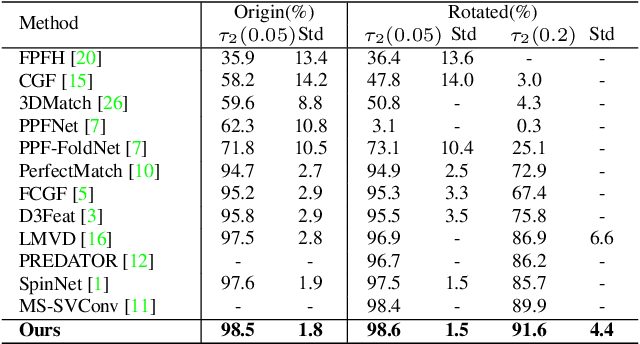
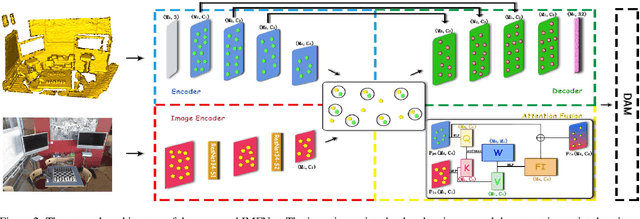
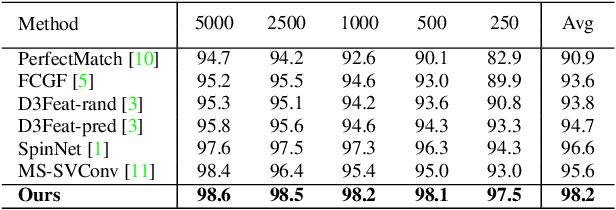
The existing state-of-the-art point descriptor relies on structure information only, which omit the texture information. However, texture information is crucial for our humans to distinguish a scene part. Moreover, the current learning-based point descriptors are all black boxes which are unclear how the original points contribute to the final descriptor. In this paper, we propose a new multimodal fusion method to generate a point cloud registration descriptor by considering both structure and texture information. Specifically, a novel attention-fusion module is designed to extract the weighted texture information for the descriptor extraction. In addition, we propose an interpretable module to explain the original points in contributing to the final descriptor. We use the descriptor element as the loss to backpropagate to the target layer and consider the gradient as the significance of this point to the final descriptor. This paper moves one step further to explainable deep learning in the registration task. Comprehensive experiments on 3DMatch, 3DLoMatch and KITTI demonstrate that the multimodal fusion descriptor achieves state-of-the-art accuracy and improve the descriptor's distinctiveness. We also demonstrate that our interpretable module in explaining the registration descriptor extraction.