 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimuAgent: An LLM-Based Simulink Modeling Assistant Enhanced with Reinforcement Learning
Jan 08, 2026Large language models (LLMs) have revolutionized text-based code automation, but their potential in graph-oriented engineering workflows remains under-explored. We introduce SimuAgent, an LLM-powered modeling and simulation agent tailored for Simulink. SimuAgent replaces verbose XML with a concise, dictionary-style Python representation, dramatically cutting token counts, improving interpretability, and enabling fast, in-process simulation. A lightweight plan-execute architecture, trained in two stages, equips the agent with both low-level tool skills and high-level design reasoning. To tackle sparse rewards in long-horizon tasks, we propose Reflection-GRPO (ReGRPO), which augments Group Relative Policy Optimization (GRPO) with self-reflection traces that supply rich intermediate feedback, accelerating convergence and boosting robustness. Experiments on SimuBench, our newly released benchmark comprising 5300 multi-domain modeling tasks, show that a Qwen2.5-7B model fine-tuned with SimuAgent converges faster and achieves higher modeling accuracy than standard RL baselines, and even surpasses GPT-4o when evaluated with few-shot prompting on the same benchmark. Ablations confirm that the two-stage curriculum and abstract-reconstruct data augmentation further enhance generalization. SimuAgent trains and runs entirely on-premise with modest hardware, delivering a privacy-preserving, cost-effective solution for industrial model-driven engineering. SimuAgent bridges the gap between LLMs and graphical modeling environments, offering a practical solution for AI-assisted engineering design in industrial settings.
CheX-DS: Improving Chest X-ray Image Classification with Ensemble Learning Based on DenseNet and Swin Transformer
May 16, 2025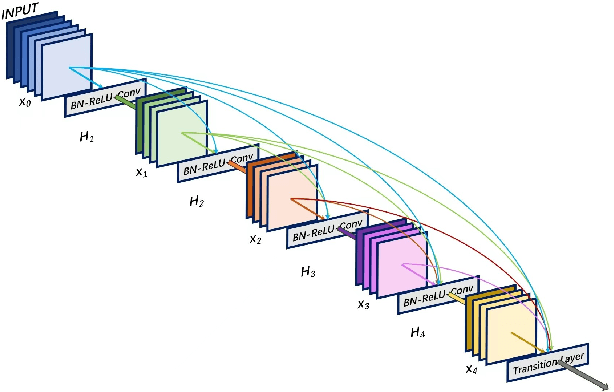
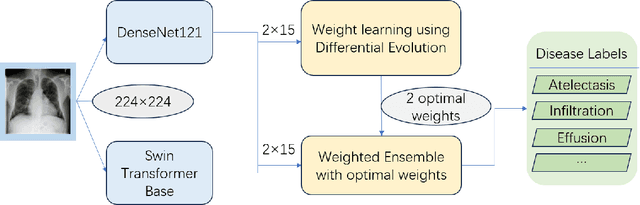
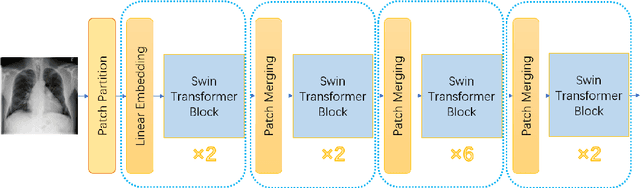
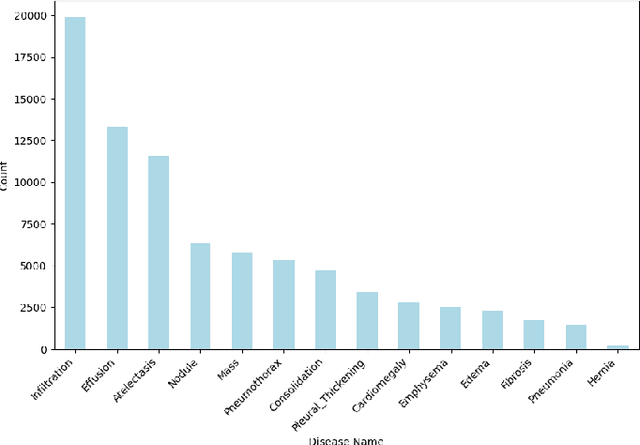
The automatic diagnosis of chest diseases is a popular and challenging task. Most current methods are based on convolutional neural networks (CNNs), which focus on local features while neglecting global features. Recently, self-attention mechanisms have been introduced into the field of computer vision, demonstrating superior performance. Therefore, this paper proposes an effective model, CheX-DS, for classifying long-tail multi-label data in the medical field of chest X-rays. The model is based on the excellent CNN model DenseNet for medical imaging and the newly popular Swin Transformer model, utilizing ensemble deep learning techniques to combine the two models and leverage the advantages of both CNNs and Transformers. The loss function of CheX-DS combines weighted binary cross-entropy loss with asymmetric loss, effectively addressing the issue of data imbalance. The NIH ChestX-ray14 dataset is selected to evaluate the model's effectiveness. The model outperforms previous studies with an excellent average AUC score of 83.76\%, demonstrating its superior performance.
* BIBM
Semantics Guided Disentangled GAN for Chest X-ray Image Rib Segmentation
Jul 22, 2024The label annotations for chest X-ray image rib segmentation are time consuming and laborious, and the labeling quality heavily relies on medical knowledge of annotators. To reduce the dependency on annotated data, existing works often utilize generative adversarial network (GAN) to generate training data. However, GAN-based methods overlook the nuanced information specific to individual organs, which degrades the generation quality of chest X-ray image. Hence, we propose a novel Semantics guided Disentangled GAN (SD-GAN), which can generate the high-quality training data by fully utilizing the semantic information of different organs, for chest X-ray image rib segmentation. In particular, we use three ResNet50 branches to disentangle features of different organs, then use a decoder to combine features and generate corresponding images. To ensure that the generated images correspond to the input organ labels in semantics tags, we employ a semantics guidance module to perform semantic guidance on the generated images. To evaluate the efficacy of SD-GAN in generating high-quality samples, we introduce modified TransUNet(MTUNet), a specialized segmentation network designed for multi-scale contextual information extracting and multi-branch decoding, effectively tackling the challenge of organ overlap. We also propose a new chest X-ray image dataset (CXRS). It includes 1250 samples from various medical institutions. Lungs, clavicles, and 24 ribs are simultaneously annotated on each chest X-ray image. The visualization and quantitative results demonstrate the efficacy of SD-GAN in generating high-quality chest X-ray image-mask pairs. Using generated data, our trained MTUNet overcomes the limitations of the data scale and outperforms other segmentation networks.
Dual Encoder: Exploiting the Potential of Syntactic and Semantic for Aspect Sentiment Triplet Extraction
Feb 23, 2024
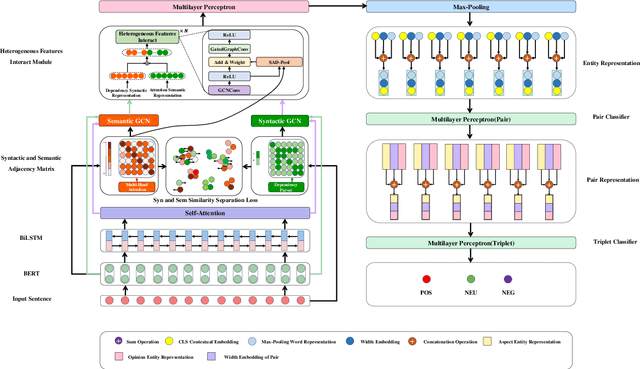
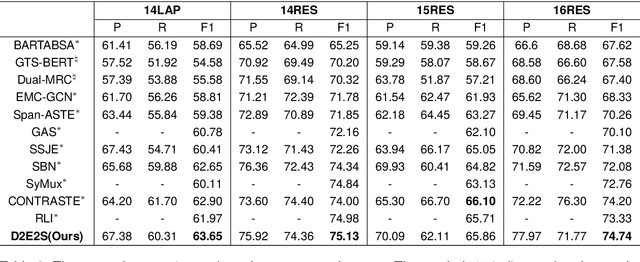
Aspect Sentiment Triple Extraction (ASTE) is an emerging task in fine-grained sentiment analysis. Recent studies have employed Graph Neural Networks (GNN) to model the syntax-semantic relationships inherent in triplet elements. However, they have yet to fully tap into the vast potential of syntactic and semantic information within the ASTE task. In this work, we propose a \emph{Dual Encoder: Exploiting the potential of Syntactic and Semantic} model (D2E2S), which maximizes the syntactic and semantic relationships among words. Specifically, our model utilizes a dual-channel encoder with a BERT channel to capture semantic information, and an enhanced LSTM channel for comprehensive syntactic information capture. Subsequently, we introduce the heterogeneous feature interaction module to capture intricate interactions between dependency syntax and attention semantics, and to dynamically select vital nodes. We leverage the synergy of these modules to harness the significant potential of syntactic and semantic information in ASTE tasks. Testing on public benchmarks, our D2E2S model surpasses the current state-of-the-art(SOTA), demonstrating its effectiveness.
Extensible Multi-Granularity Fusion Network for Aspect-based Sentiment Analysis
Feb 13, 2024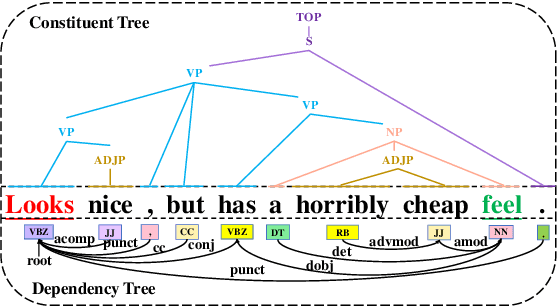
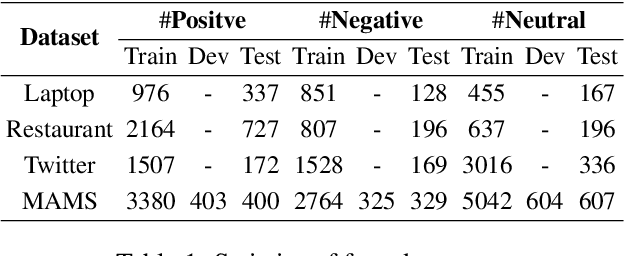
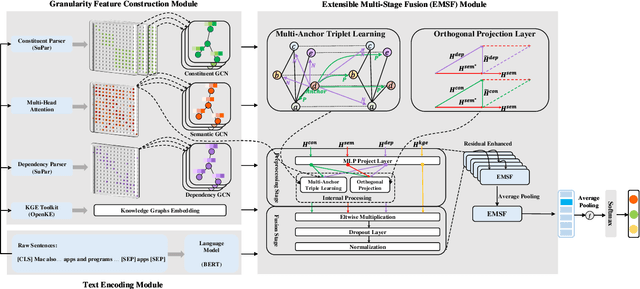
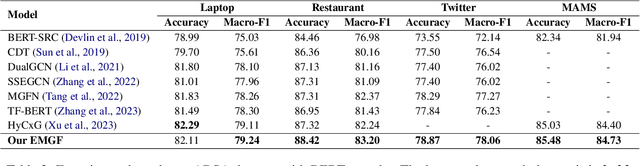
Aspect-based Sentiment Analysis (ABSA) evaluates sentiment expressions within a text to comprehend sentiment information. Previous studies integrated external knowledge, such as knowledge graphs, to enhance the semantic features in ABSA models. Recent research has examined the use of Graph Neural Networks (GNNs) on dependency and constituent trees for syntactic analysis. With the ongoing development of ABSA, more innovative linguistic and structural features are being incorporated (e.g. latent graph), but this also introduces complexity and confusion. As of now, a scalable framework for integrating diverse linguistic and structural features into ABSA does not exist. This paper presents the Extensible Multi-Granularity Fusion (EMGF) network, which integrates information from dependency and constituent syntactic, attention semantic , and external knowledge graphs. EMGF, equipped with multi-anchor triplet learning and orthogonal projection, efficiently harnesses the combined potential of each granularity feature and their synergistic interactions, resulting in a cumulative effect without additional computational expenses. Experimental findings on SemEval 2014 and Twitter datasets confirm EMGF's superiority over existing ABSA methods.
LSwinSR: UAV Imagery Super-Resolution based on Linear Swin Transformer
Mar 17, 2023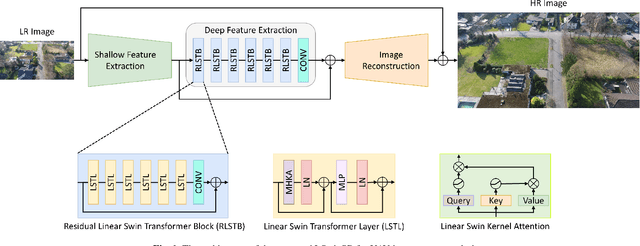
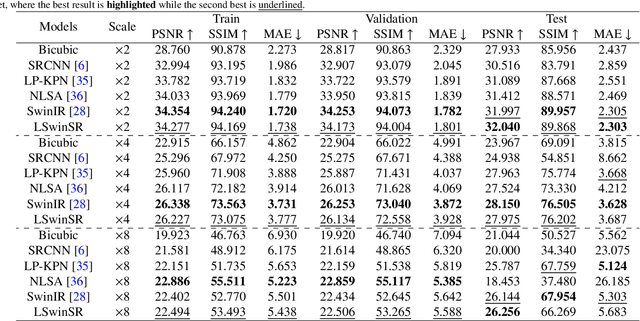

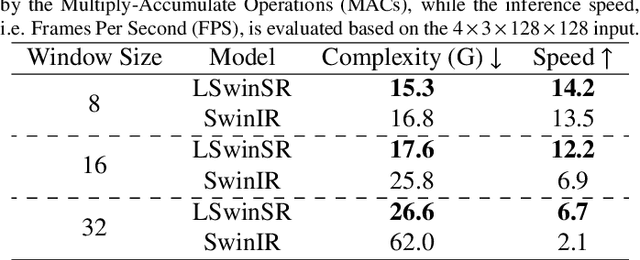
Super-resolution, which aims to reconstruct high-resolution images from low-resolution images, has drawn considerable attention and has been intensively studied in computer vision and remote sensing communities. The super-resolution technology is especially beneficial for Unmanned Aerial Vehicles (UAV), as the amount and resolution of images captured by UAV are highly limited by physical constraints such as flight altitude and load capacity. In the wake of the successful application of deep learning methods in the super-resolution task, in recent years, a series of super-resolution algorithms have been developed. In this paper, for the super-resolution of UAV images, a novel network based on the state-of-the-art Swin Transformer is proposed with better efficiency and competitive accuracy. Meanwhile, as one of the essential applications of the UAV is land cover and land use monitoring, simple image quality assessments such as the Peak-Signal-to-Noise Ratio (PSNR) and the Structural Similarity Index Measure (SSIM) are not enough to comprehensively measure the performance of an algorithm. Therefore, we further investigate the effectiveness of super-resolution methods using the accuracy of semantic segmentation. The code will be available at https://github.com/lironui/LSwinSR.
GMF: General Multimodal Fusion Framework for Correspondence Outlier Rejection
Nov 01, 2022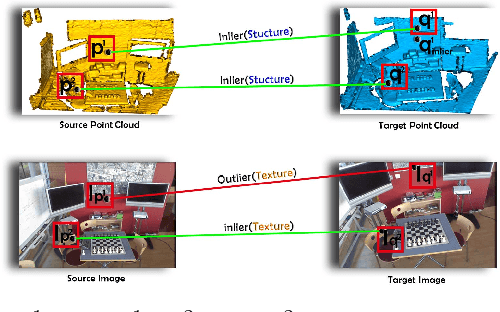
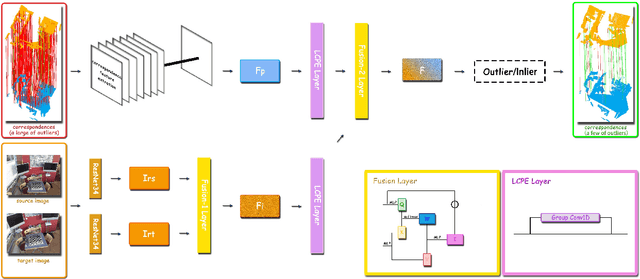
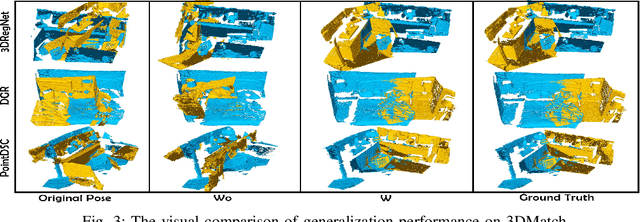
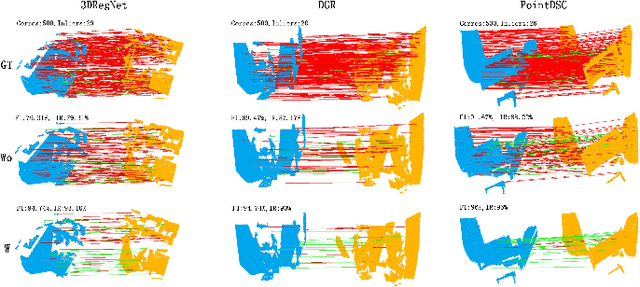
Rejecting correspondence outliers enables to boost the correspondence quality, which is a critical step in achieving high point cloud registration accuracy. The current state-of-the-art correspondence outlier rejection methods only utilize the structure features of the correspondences. However, texture information is critical to reject the correspondence outliers in our human vision system. In this paper, we propose General Multimodal Fusion (GMF) to learn to reject the correspondence outliers by leveraging both the structure and texture information. Specifically, two cross-attention-based fusion layers are proposed to fuse the texture information from paired images and structure information from point correspondences. Moreover, we propose a convolutional position encoding layer to enhance the difference between Tokens and enable the encoding feature pay attention to neighbor information. Our position encoding layer will make the cross-attention operation integrate both local and global information. Experiments on multiple datasets(3DMatch, 3DLoMatch, KITTI) and recent state-of-the-art models (3DRegNet, DGR, PointDSC) prove that our GMF achieves wide generalization ability and consistently improves the point cloud registration accuracy. Furthermore, several ablation studies demonstrate the robustness of the proposed GMF on different loss functions, lighting conditions and noises.The code is available at https://github.com/XiaoshuiHuang/GMF.
Revisiting Open World Object Detection
Jan 04, 2022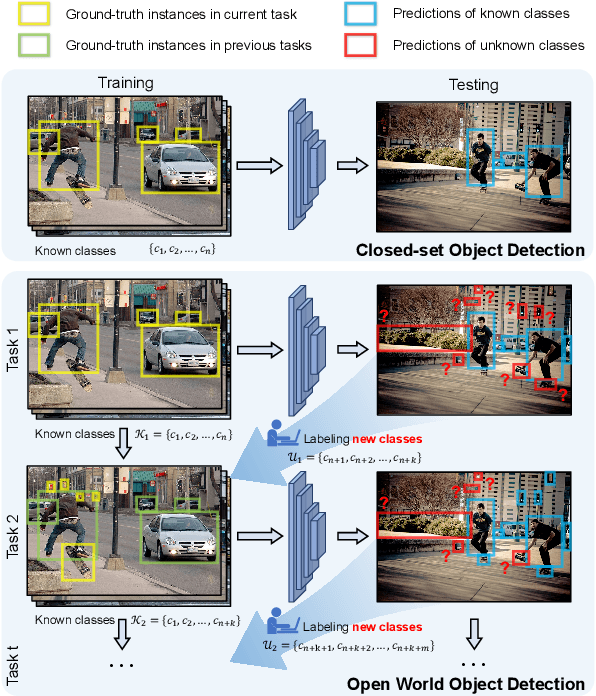
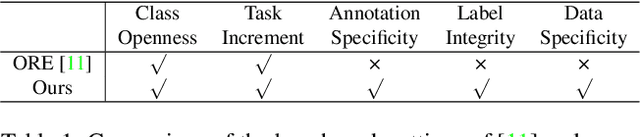
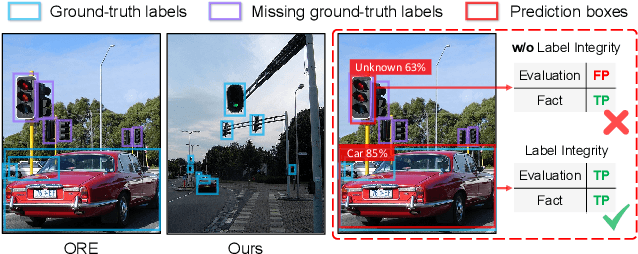

Open World Object Detection (OWOD), simulating the real dynamic world where knowledge grows continuously, attempts to detect both known and unknown classes and incrementally learn the identified unknown ones. We find that although the only previous OWOD work constructively puts forward to the OWOD definition, the experimental settings are unreasonable with the illogical benchmark, confusing metric calculation, and inappropriate method. In this paper, we rethink the OWOD experimental setting and propose five fundamental benchmark principles to guide the OWOD benchmark construction. Moreover, we design two fair evaluation protocols specific to the OWOD problem, filling the void of evaluating from the perspective of unknown classes. Furthermore, we introduce a novel and effective OWOD framework containing an auxiliary Proposal ADvisor (PAD) and a Class-specific Expelling Classifier (CEC). The non-parametric PAD could assist the RPN in identifying accurate unknown proposals without supervision, while CEC calibrates the over-confident activation boundary and filters out confusing predictions through a class-specific expelling function. Comprehensive experiments conducted on our fair benchmark demonstrate that our method outperforms other state-of-the-art object detection approaches in terms of both existing and our new metrics. Our benchmark and code are available at https://github.com/RE-OWOD/RE-OWOD.
IMFNet: Interpretable Multimodal Fusion for Point Cloud Registration
Nov 18, 2021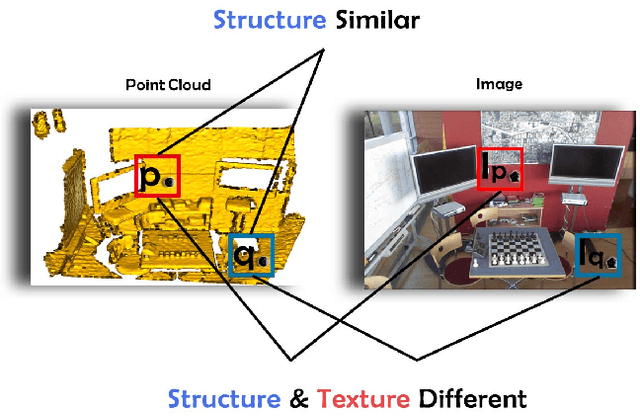
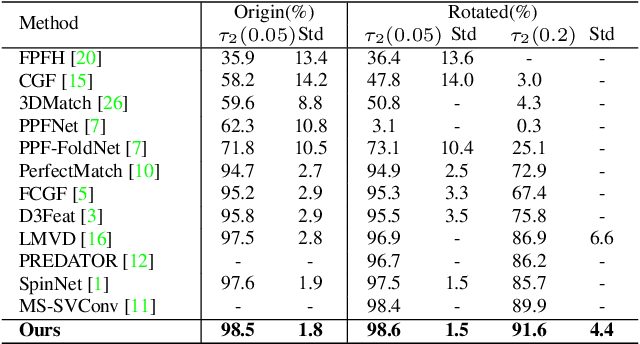
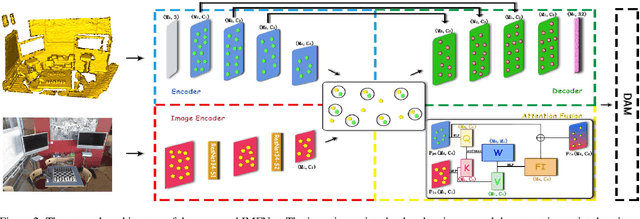
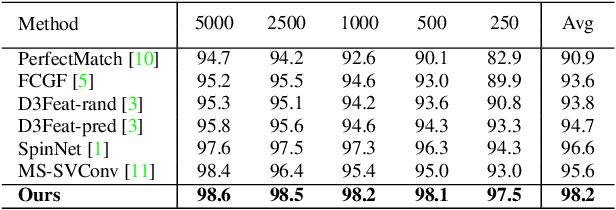
The existing state-of-the-art point descriptor relies on structure information only, which omit the texture information. However, texture information is crucial for our humans to distinguish a scene part. Moreover, the current learning-based point descriptors are all black boxes which are unclear how the original points contribute to the final descriptor. In this paper, we propose a new multimodal fusion method to generate a point cloud registration descriptor by considering both structure and texture information. Specifically, a novel attention-fusion module is designed to extract the weighted texture information for the descriptor extraction. In addition, we propose an interpretable module to explain the original points in contributing to the final descriptor. We use the descriptor element as the loss to backpropagate to the target layer and consider the gradient as the significance of this point to the final descriptor. This paper moves one step further to explainable deep learning in the registration task. Comprehensive experiments on 3DMatch, 3DLoMatch and KITTI demonstrate that the multimodal fusion descriptor achieves state-of-the-art accuracy and improve the descriptor's distinctiveness. We also demonstrate that our interpretable module in explaining the registration descriptor extraction.
Simplifying Reinforced Feature Selection via Restructured Choice Strategy of Single Agent
Sep 19, 2020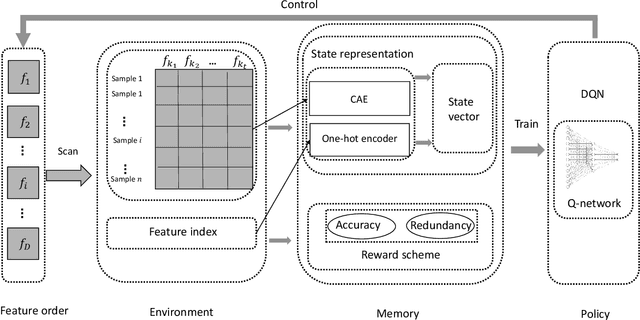
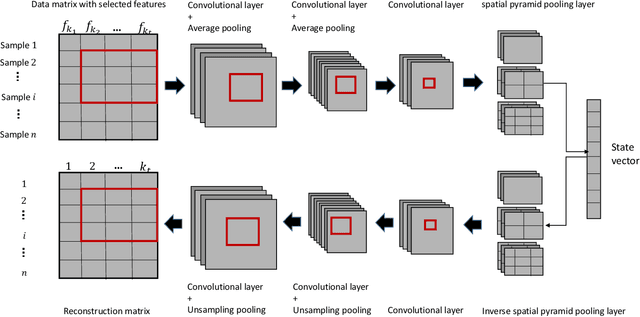
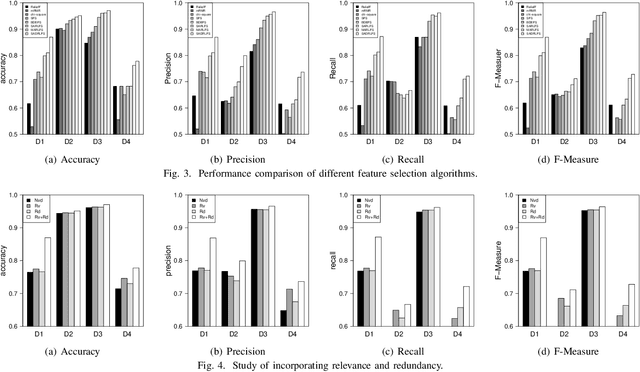
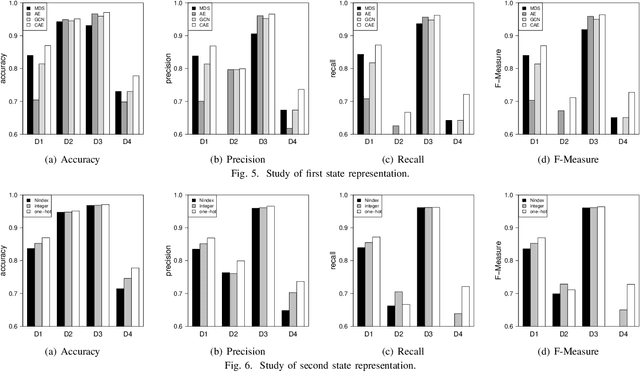
Feature selection aims to select a subset of features to optimize the performances of downstream predictive tasks. Recently, multi-agent reinforced feature selection (MARFS) has been introduced to automate feature selection, by creating agents for each feature to select or deselect corresponding features. Although MARFS enjoys the automation of the selection process, MARFS suffers from not just the data complexity in terms of contents and dimensionality, but also the exponentially-increasing computational costs with regard to the number of agents. The raised concern leads to a new research question: Can we simplify the selection process of agents under reinforcement learning context so as to improve the efficiency and costs of feature selection? To address the question, we develop a single-agent reinforced feature selection approach integrated with restructured choice strategy. Specifically, the restructured choice strategy includes: 1) we exploit only one single agent to handle the selection task of multiple features, instead of using multiple agents. 2) we develop a scanning method to empower the single agent to make multiple selection/deselection decisions in each round of scanning. 3) we exploit the relevance to predictive labels of features to prioritize the scanning orders of the agent for multiple features. 4) we propose a convolutional auto-encoder algorithm, integrated with the encoded index information of features, to improve state representation. 5) we design a reward scheme that take into account both prediction accuracy and feature redundancy to facilitate the exploration process. Finally, we present extensive experimental results to demonstrate the efficiency and effectiveness of the proposed method.