Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Aggregation for Video Classification
Paper and Code
Oct 27, 2017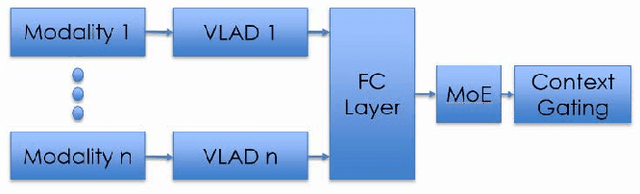
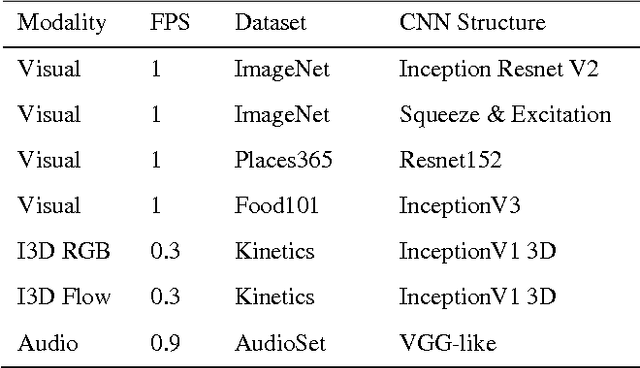
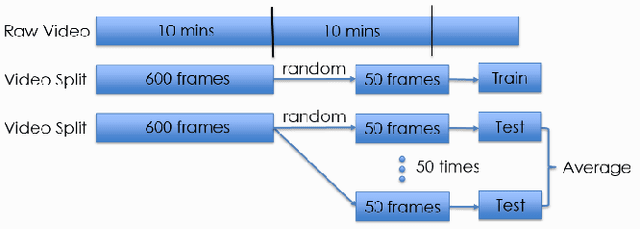

In this paper, we present a solution to Large-Scale Video Classification Challenge (LSVC2017) [1] that ranked the 1st place. We focused on a variety of modalities that cover visual, motion and audio. Also, we visualized the aggregation process to better understand how each modality takes effect. Among the extracted modalities, we found Temporal-Spatial features calculated by 3D convolution quite promising that greatly improved the performance. We attained the official metric mAP 0.8741 on the testing set with the ensemble model.
View paper on