 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Brain Iterative Merging: Mitigating Interference in LLM Merging
Feb 17, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities, but their high computational costs pose challenges for customization. Model merging offers a cost-effective alternative, yet existing methods suffer from interference among parameters, leading to performance degradation. In this work, we propose Optimal Brain Iterative Merging (OBIM), a novel method designed to mitigate both intra-model and inter-model interference. OBIM consists of two key components: (1) A saliency measurement mechanism that evaluates parameter importance based on loss changes induced by individual weight alterations, reducing intra-model interference by preserving only high-saliency parameters. (2) A mutually exclusive iterative merging framework, which incrementally integrates models using a binary mask to avoid direct parameter averaging, thereby mitigating inter-model interference. We validate OBIM through experiments on both Supervised Fine-Tuned (SFT) models and post-pretrained checkpoints. The results show that OBIM significantly outperforms existing merging techniques. Overall, OBIM provides an effective and practical solution for enhancing LLM merging.
SFE-AI at SemEval-2022 Task 11: Low-Resource Named Entity Recognition using Large Pre-trained Language Models
May 29, 2022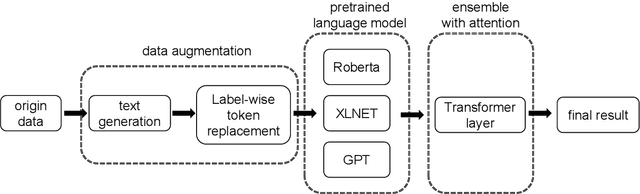
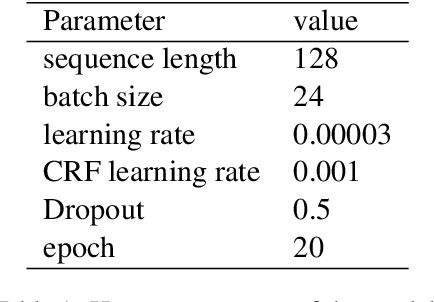
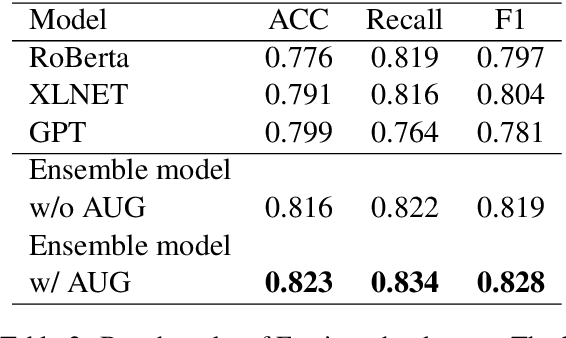
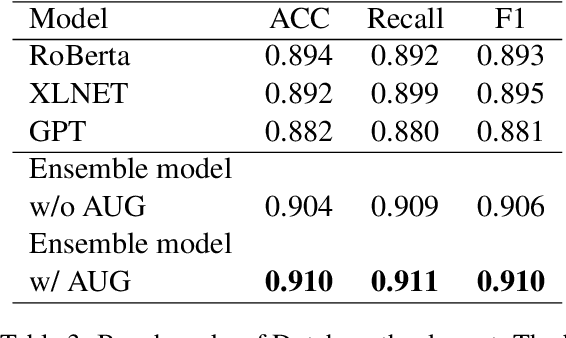
Large scale pre-training models have been widely used in named entity recognition (NER) tasks. However, model ensemble through parameter averaging or voting can not give full play to the differentiation advantages of different models, especially in the open domain. This paper describes our NER system in the SemEval 2022 task11: MultiCoNER. We proposed an effective system to adaptively ensemble pre-trained language models by a Transformer layer. By assigning different weights to each model for different inputs, we adopted the Transformer layer to integrate the advantages of diverse models effectively. Experimental results show that our method achieves superior performances in Farsi and Dutch.
PASH at TREC 2021 Deep Learning Track: Generative Enhanced Model for Multi-stage Ranking
May 24, 2022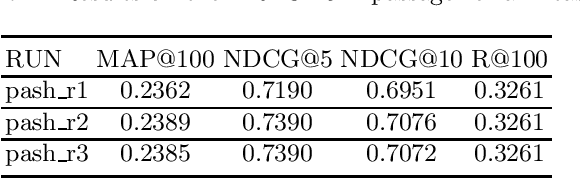
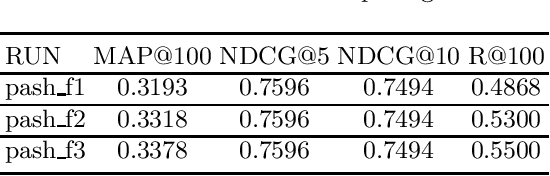
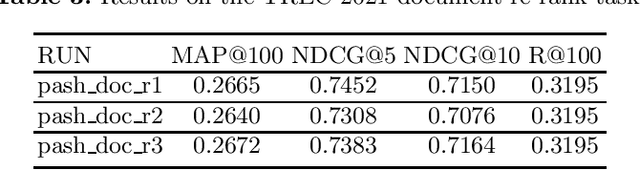
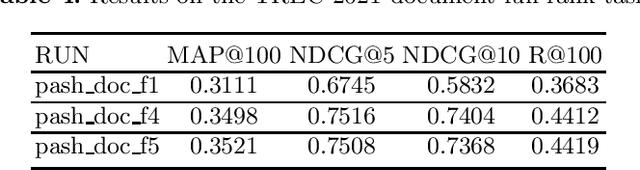
This paper describes the PASH participation in TREC 2021 Deep Learning Track. In the recall stage, we adopt a scheme combining sparse and dense retrieval method. In the multi-stage ranking phase, point-wise and pair-wise ranking strategies are used one after another based on model continual pre-trained on general knowledge and document-level data. Compared to TREC 2020 Deep Learning Track, we have additionally introduced the generative model T5 to further enhance the performance.
CandidateDrug4Cancer: An Open Molecular Graph Learning Benchmark on Drug Discovery for Cancer
Mar 02, 2022

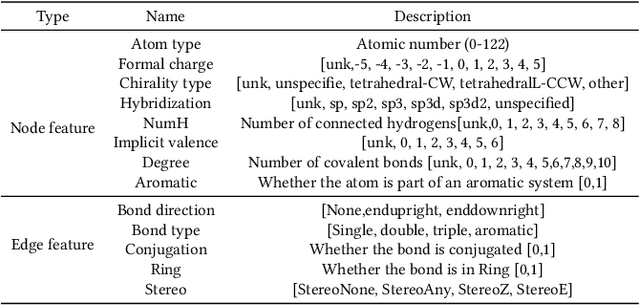
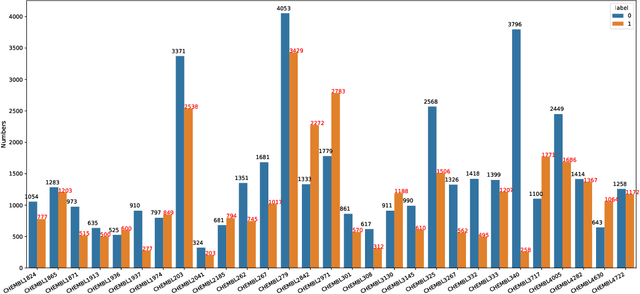
Anti-cancer drug discoveries have been serendipitous, we sought to present the Open Molecular Graph Learning Benchmark, named CandidateDrug4Cancer, a challenging and realistic benchmark dataset to facilitate scalable, robust, and reproducible graph machine learning research for anti-cancer drug discovery. CandidateDrug4Cancer dataset encompasses multiple most-mentioned 29 targets for cancer, covering 54869 cancer-related drug molecules which are ranged from pre-clinical, clinical and FDA-approved. Besides building the datasets, we also perform benchmark experiments with effective Drug Target Interaction (DTI) prediction baselines using descriptors and expressive graph neural networks. Experimental results suggest that CandidateDrug4Cancer presents significant challenges for learning molecular graphs and targets in practical application, indicating opportunities for future researches on developing candidate drugs for treating cancers.
Revisiting Open World Object Detection
Jan 04, 2022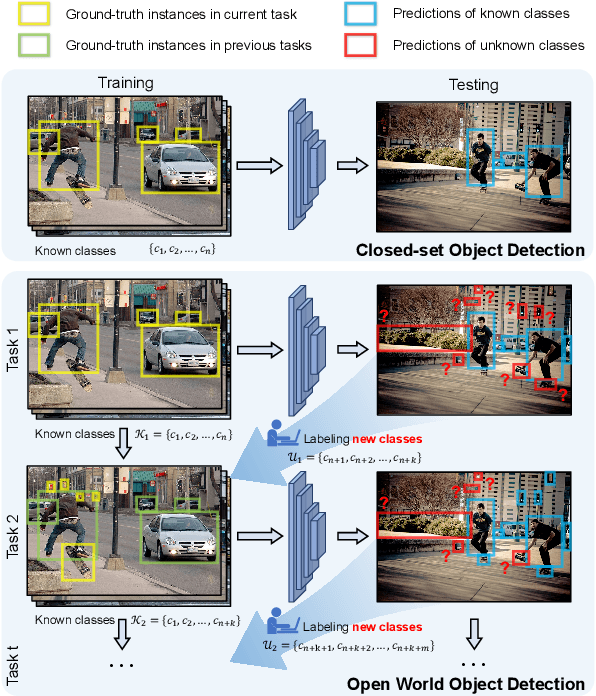
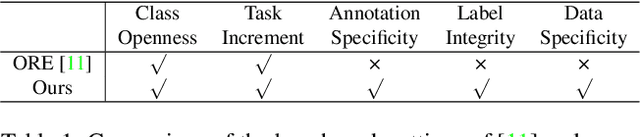
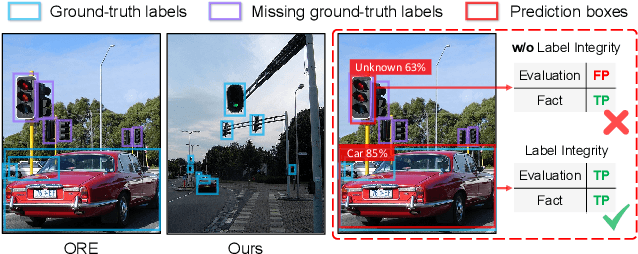

Open World Object Detection (OWOD), simulating the real dynamic world where knowledge grows continuously, attempts to detect both known and unknown classes and incrementally learn the identified unknown ones. We find that although the only previous OWOD work constructively puts forward to the OWOD definition, the experimental settings are unreasonable with the illogical benchmark, confusing metric calculation, and inappropriate method. In this paper, we rethink the OWOD experimental setting and propose five fundamental benchmark principles to guide the OWOD benchmark construction. Moreover, we design two fair evaluation protocols specific to the OWOD problem, filling the void of evaluating from the perspective of unknown classes. Furthermore, we introduce a novel and effective OWOD framework containing an auxiliary Proposal ADvisor (PAD) and a Class-specific Expelling Classifier (CEC). The non-parametric PAD could assist the RPN in identifying accurate unknown proposals without supervision, while CEC calibrates the over-confident activation boundary and filters out confusing predictions through a class-specific expelling function. Comprehensive experiments conducted on our fair benchmark demonstrate that our method outperforms other state-of-the-art object detection approaches in terms of both existing and our new metrics. Our benchmark and code are available at https://github.com/RE-OWOD/RE-OWOD.
Superpixel-Based Building Damage Detection from Post-earthquake Very High Resolution Imagery Using Deep Neural Networks
Dec 22, 2021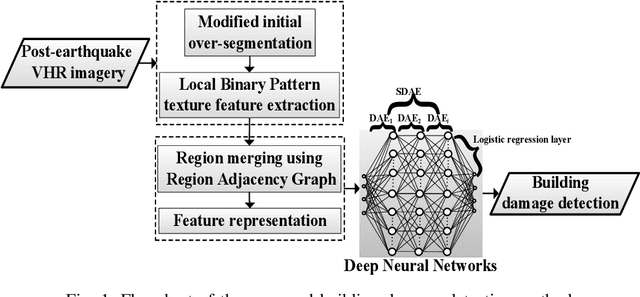


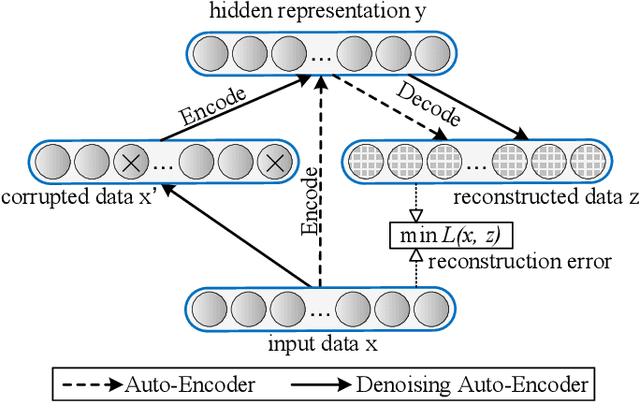
Building damage detection after natural disasters like earthquakes is crucial for initiating effective emergency response actions. Remotely sensed very high spatial resolution (VHR) imagery can provide vital information due to their ability to map the affected buildings with high geometric precision. Many approaches have been developed to detect damaged buildings due to earthquakes. However, little attention has been paid to exploiting rich features represented in VHR images using Deep Neural Networks (DNN). This paper presents a novel superpixel based approach combining DNN and a modified segmentation method, to detect damaged buildings from VHR imagery. Firstly, a modified Fast Scanning and Adaptive Merging method is extended to create initial over-segmentation. Secondly, the segments are merged based on the Region Adjacent Graph (RAG), considered an improved semantic similarity criterion composed of Local Binary Patterns (LBP) texture, spectral, and shape features. Thirdly, a pre-trained DNN using Stacked Denoising Auto-Encoders called SDAE-DNN is presented, to exploit the rich semantic features for building damage detection. Deep-layer feature abstraction of SDAE-DNN could boost detection accuracy through learning more intrinsic and discriminative features, which outperformed other methods using state-of-the-art alternative classifiers. We demonstrate the feasibility and effectiveness of our method using a subset of WorldView-2 imagery, in the complex urban areas of Bhaktapur, Nepal, which was affected by the Nepal Earthquake of April 25, 2015.
Pairwise Half-graph Discrimination: A Simple Graph-level Self-supervised Strategy for Pre-training Graph Neural Networks
Oct 26, 2021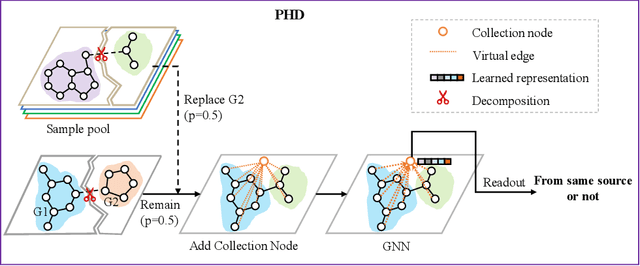
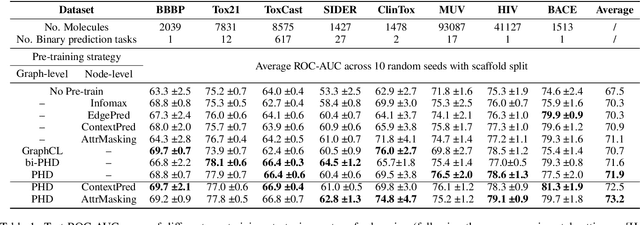
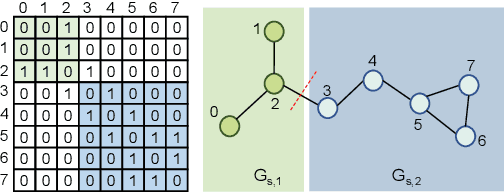

Self-supervised learning has gradually emerged as a powerful technique for graph representation learning. However, transferable, generalizable, and robust representation learning on graph data still remains a challenge for pre-training graph neural networks. In this paper, we propose a simple and effective self-supervised pre-training strategy, named Pairwise Half-graph Discrimination (PHD), that explicitly pre-trains a graph neural network at graph-level. PHD is designed as a simple binary classification task to discriminate whether two half-graphs come from the same source. Experiments demonstrate that the PHD is an effective pre-training strategy that offers comparable or superior performance on 13 graph classification tasks compared with state-of-the-art strategies, and achieves notable improvements when combined with node-level strategies. Moreover, the visualization of learned representation revealed that PHD strategy indeed empowers the model to learn graph-level knowledge like the molecular scaffold. These results have established PHD as a powerful and effective self-supervised learning strategy in graph-level representation learning.
Winner Team Mia at TextVQA Challenge 2021: Vision-and-Language Representation Learning with Pre-trained Sequence-to-Sequence Model
Jun 24, 2021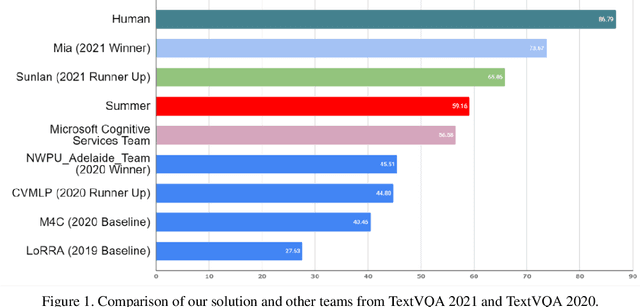
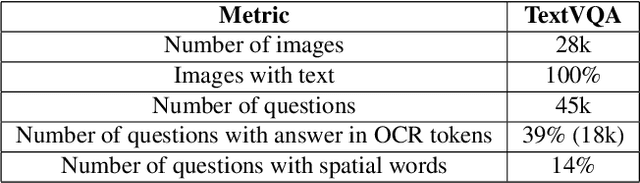
TextVQA requires models to read and reason about text in images to answer questions about them. Specifically, models need to incorporate a new modality of text present in the images and reason over it to answer TextVQA questions. In this challenge, we use generative model T5 for TextVQA task. Based on pre-trained checkpoint T5-3B from HuggingFace repository, two other pre-training tasks including masked language modeling(MLM) and relative position prediction(RPP) are designed to better align object feature and scene text. In the stage of pre-training, encoder is dedicate to handle the fusion among multiple modalities: question text, object text labels, scene text labels, object visual features, scene visual features. After that decoder generates the text sequence step-by-step, cross entropy loss is required by default. We use a large-scale scene text dataset in pre-training and then fine-tune the T5-3B with the TextVQA dataset only.
Learn molecular representations from large-scale unlabeled molecules for drug discovery
Dec 21, 2020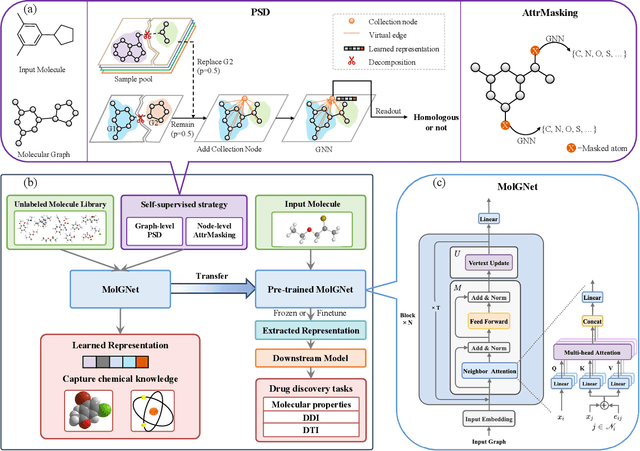

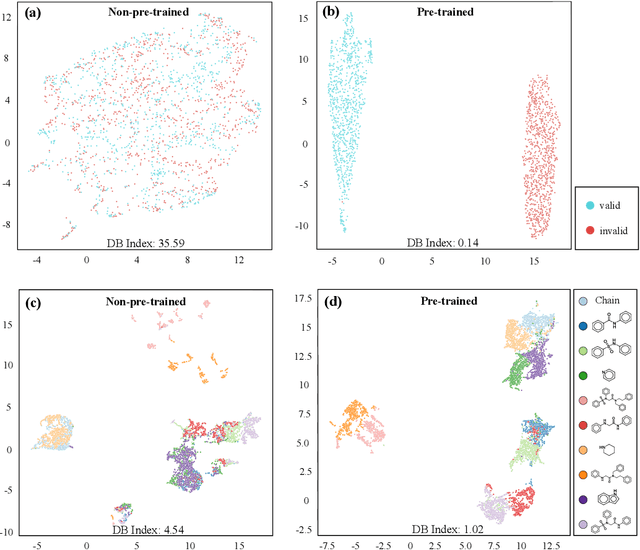

How to produce expressive molecular representations is a fundamental challenge in AI-driven drug discovery. Graph neural network (GNN) has emerged as a powerful technique for modeling molecular data. However, previous supervised approaches usually suffer from the scarcity of labeled data and have poor generalization capability. Here, we proposed a novel Molecular Pre-training Graph-based deep learning framework, named MPG, that leans molecular representations from large-scale unlabeled molecules. In MPG, we proposed a powerful MolGNet model and an effective self-supervised strategy for pre-training the model at both the node and graph-level. After pre-training on 11 million unlabeled molecules, we revealed that MolGNet can capture valuable chemistry insights to produce interpretable representation. The pre-trained MolGNet can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of drug discovery tasks, including molecular properties prediction, drug-drug interaction, and drug-target interaction, involving 13 benchmark datasets. Our work demonstrates that MPG is promising to become a novel approach in the drug discovery pipeline.