 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Distribution Shifts: Adaptive Hyperspectral Image Classification at Test Time
Sep 10, 2025Hyperspectral image (HSI) classification models are highly sensitive to distribution shifts caused by various real-world degradations such as noise, blur, compression, and atmospheric effects. To address this challenge, we propose HyperTTA, a unified framework designed to enhance model robustness under diverse degradation conditions. Specifically, we first construct a multi-degradation hyperspectral dataset that systematically simulates nine representative types of degradations, providing a comprehensive benchmark for robust classification evaluation. Based on this, we design a spectral-spatial transformer classifier (SSTC) enhanced with a multi-level receptive field mechanism and label smoothing regularization to jointly capture multi-scale spatial context and improve generalization. Furthermore, HyperTTA incorporates a lightweight test-time adaptation (TTA) strategy, the confidence-aware entropy-minimized LayerNorm adapter (CELA), which updates only the affine parameters of LayerNorm layers by minimizing prediction entropy on high-confidence unlabeled target samples. This confidence-aware adaptation prevents unreliable updates from noisy predictions, enabling robust and dynamic adaptation without access to source data or target annotations. Extensive experiments on two benchmark datasets demonstrate that HyperTTA outperforms existing baselines across a wide range of degradation scenarios, validating the effectiveness of both its classification backbone and the proposed TTA scheme. Code will be made available publicly.
PSReg: Prior-guided Sparse Mixture of Experts for Point Cloud Registration
Jan 14, 2025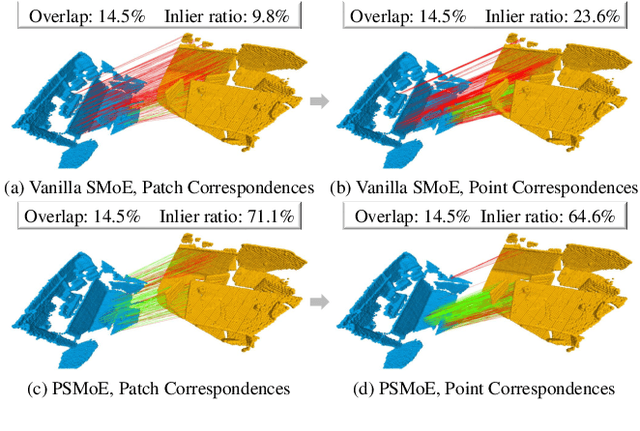
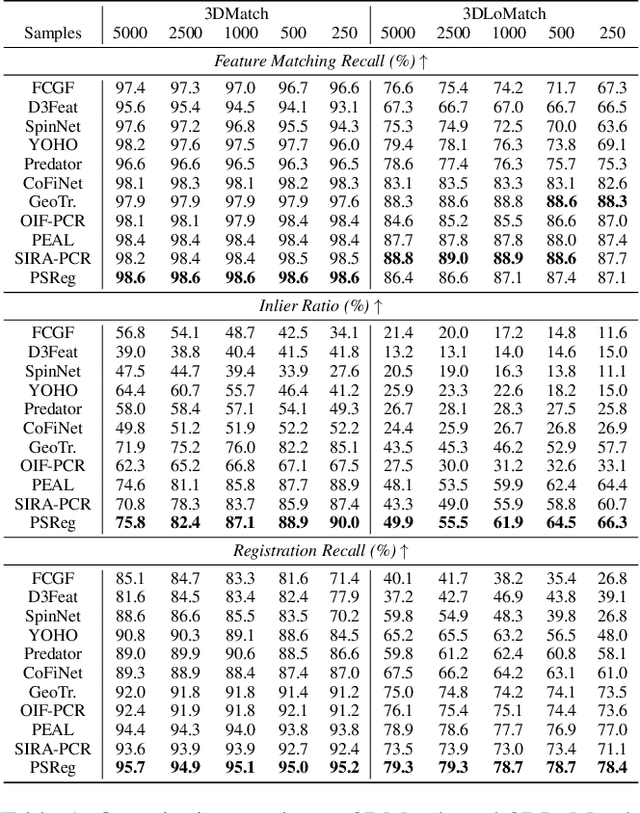

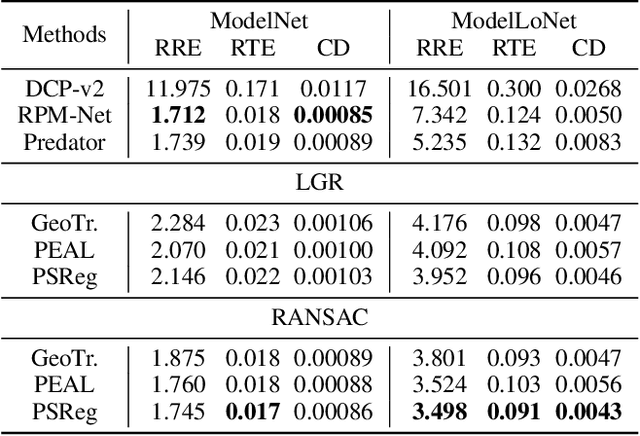
The discriminative feature is crucial for point cloud registration. Recent methods improve the feature discriminative by distinguishing between non-overlapping and overlapping region points. However, they still face challenges in distinguishing the ambiguous structures in the overlapping regions. Therefore, the ambiguous features they extracted resulted in a significant number of outlier matches from overlapping regions. To solve this problem, we propose a prior-guided SMoE-based registration method to improve the feature distinctiveness by dispatching the potential correspondences to the same experts. Specifically, we propose a prior-guided SMoE module by fusing prior overlap and potential correspondence embeddings for routing, assigning tokens to the most suitable experts for processing. In addition, we propose a registration framework by a specific combination of Transformer layer and prior-guided SMoE module. The proposed method not only pays attention to the importance of locating the overlapping areas of point clouds, but also commits to finding more accurate correspondences in overlapping areas. Our extensive experiments demonstrate the effectiveness of our method, achieving state-of-the-art registration recall (95.7\%/79.3\%) on the 3DMatch/3DLoMatch benchmark. Moreover, we also test the performance on ModelNet40 and demonstrate excellent performance.
Change-Aware Siamese Network for Surface Defects Segmentation under Complex Background
Sep 01, 2024
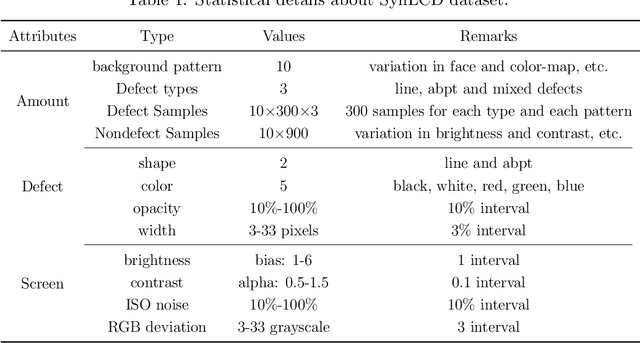
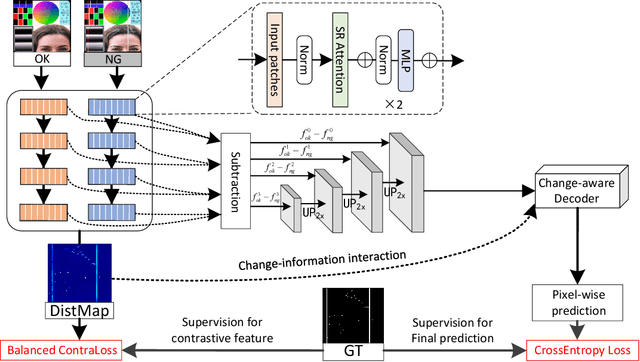
Despite the eye-catching breakthroughs achieved by deep visual networks in detecting region-level surface defects, the challenge of high-quality pixel-wise defect detection remains due to diverse defect appearances and data scarcity. To avoid over-reliance on defect appearance and achieve accurate defect segmentation, we proposed a change-aware Siamese network that solves the defect segmentation in a change detection framework. A novel multi-class balanced contrastive loss is introduced to guide the Transformer-based encoder, which enables encoding diverse categories of defects as the unified class-agnostic difference between defect and defect-free images. The difference presented by a distance map is then skip-connected to the change-aware decoder to assist in the location of both inter-class and out-of-class pixel-wise defects. In addition, we proposed a synthetic dataset with multi-class liquid crystal display (LCD) defects under a complex and disjointed background context, to demonstrate the advantages of change-based modeling over appearance-based modeling for defect segmentation. In our proposed dataset and two public datasets, our model achieves superior performances than the leading semantic segmentation methods, while maintaining a relatively small model size. Moreover, our model achieves a new state-of-the-art performance compared to the semi-supervised approaches in various supervision settings.
TCLC-GS: Tightly Coupled LiDAR-Camera Gaussian Splatting for Surrounding Autonomous Driving Scenes
Apr 03, 2024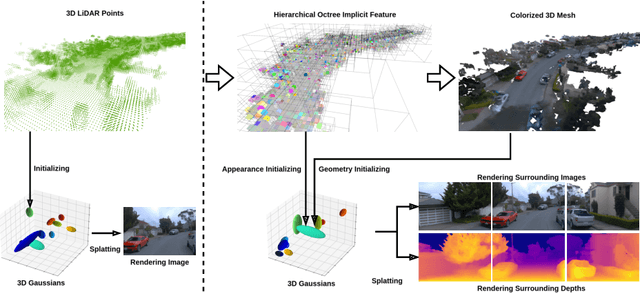
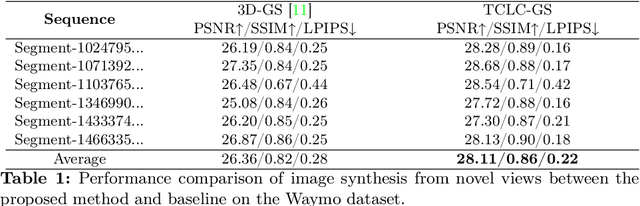
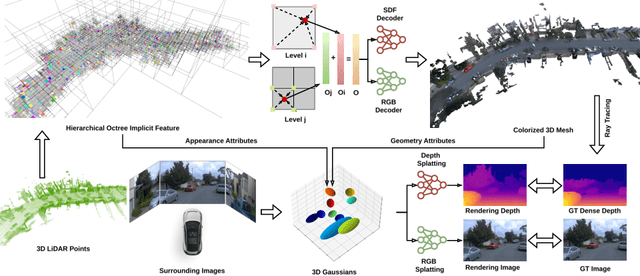
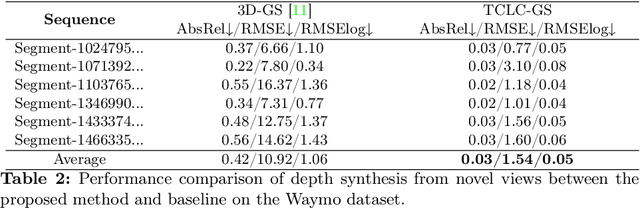
Most 3D Gaussian Splatting (3D-GS) based methods for urban scenes initialize 3D Gaussians directly with 3D LiDAR points, which not only underutilizes LiDAR data capabilities but also overlooks the potential advantages of fusing LiDAR with camera data. In this paper, we design a novel tightly coupled LiDAR-Camera Gaussian Splatting (TCLC-GS) to fully leverage the combined strengths of both LiDAR and camera sensors, enabling rapid, high-quality 3D reconstruction and novel view RGB/depth synthesis. TCLC-GS designs a hybrid explicit (colorized 3D mesh) and implicit (hierarchical octree feature) 3D representation derived from LiDAR-camera data, to enrich the properties of 3D Gaussians for splatting. 3D Gaussian's properties are not only initialized in alignment with the 3D mesh which provides more completed 3D shape and color information, but are also endowed with broader contextual information through retrieved octree implicit features. During the Gaussian Splatting optimization process, the 3D mesh offers dense depth information as supervision, which enhances the training process by learning of a robust geometry. Comprehensive evaluations conducted on the Waymo Open Dataset and nuScenes Dataset validate our method's state-of-the-art (SOTA) performance. Utilizing a single NVIDIA RTX 3090 Ti, our method demonstrates fast training and achieves real-time RGB and depth rendering at 90 FPS in resolution of 1920x1280 (Waymo), and 120 FPS in resolution of 1600x900 (nuScenes) in urban scenarios.
Feature Shrinkage Pyramid for Camouflaged Object Detection with Transformers
Mar 26, 2023



Vision transformers have recently shown strong global context modeling capabilities in camouflaged object detection. However, they suffer from two major limitations: less effective locality modeling and insufficient feature aggregation in decoders, which are not conducive to camouflaged object detection that explores subtle cues from indistinguishable backgrounds. To address these issues, in this paper, we propose a novel transformer-based Feature Shrinkage Pyramid Network (FSPNet), which aims to hierarchically decode locality-enhanced neighboring transformer features through progressive shrinking for camouflaged object detection. Specifically, we propose a nonlocal token enhancement module (NL-TEM) that employs the non-local mechanism to interact neighboring tokens and explore graph-based high-order relations within tokens to enhance local representations of transformers. Moreover, we design a feature shrinkage decoder (FSD) with adjacent interaction modules (AIM), which progressively aggregates adjacent transformer features through a layer-bylayer shrinkage pyramid to accumulate imperceptible but effective cues as much as possible for object information decoding. Extensive quantitative and qualitative experiments demonstrate that the proposed model significantly outperforms the existing 24 competitors on three challenging COD benchmark datasets under six widely-used evaluation metrics. Our code is publicly available at https://github.com/ZhouHuang23/FSPNet.
GWRBoost:A geographically weighted gradient boosting method for explainable quantification of spatially-varying relationships
Dec 15, 2022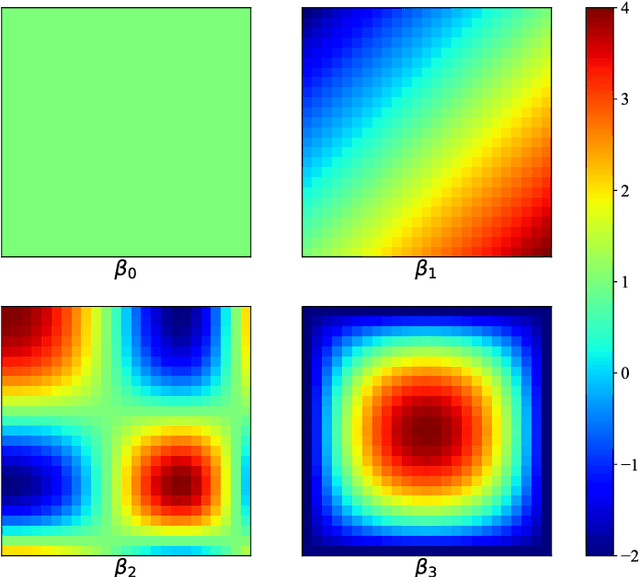



The geographically weighted regression (GWR) is an essential tool for estimating the spatial variation of relationships between dependent and independent variables in geographical contexts. However, GWR suffers from the problem that classical linear regressions, which compose the GWR model, are more prone to be underfitting, especially for significant volume and complex nonlinear data, causing inferior comparative performance. Nevertheless, some advanced models, such as the decision tree and the support vector machine, can learn features from complex data more effectively while they cannot provide explainable quantification for the spatial variation of localized relationships. To address the above issues, we propose a geographically gradient boosting weighted regression model, GWRBoost, that applies the localized additive model and gradient boosting optimization method to alleviate underfitting problems and retains explainable quantification capability for spatially-varying relationships between geographically located variables. Furthermore, we formulate the computation method of the Akaike information score for the proposed model to conduct the comparative analysis with the classic GWR algorithm. Simulation experiments and the empirical case study are applied to prove the efficient performance and practical value of GWRBoost. The results show that our proposed model can reduce the RMSE by 18.3% in parameter estimation accuracy and AICc by 67.3% in the goodness of fit.
PolyBuilding: Polygon Transformer for End-to-End Building Extraction
Nov 03, 2022We present PolyBuilding, a fully end-to-end polygon Transformer for building extraction. PolyBuilding direct predicts vector representation of buildings from remote sensing images. It builds upon an encoder-decoder transformer architecture and simultaneously outputs building bounding boxes and polygons. Given a set of polygon queries, the model learns the relations among them and encodes context information from the image to predict the final set of building polygons with fixed vertex numbers. Corner classification is performed to distinguish the building corners from the sampled points, which can be used to remove redundant vertices along the building walls during inference. A 1-d non-maximum suppression (NMS) is further applied to reduce vertex redundancy near the building corners. With the refinement operations, polygons with regular shapes and low complexity can be effectively obtained. Comprehensive experiments are conducted on the CrowdAI dataset. Quantitative and qualitative results show that our approach outperforms prior polygonal building extraction methods by a large margin. It also achieves a new state-of-the-art in terms of pixel-level coverage, instance-level precision and recall, and geometry-level properties (including contour regularity and polygon complexity).
DouFu: A Double Fusion Joint Learning Method For Driving Trajectory Representation
May 05, 2022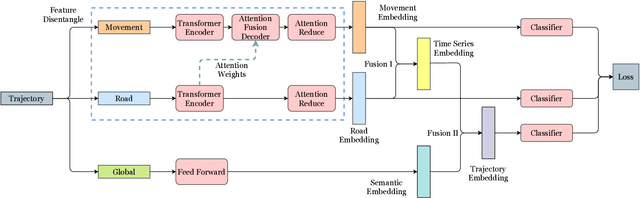
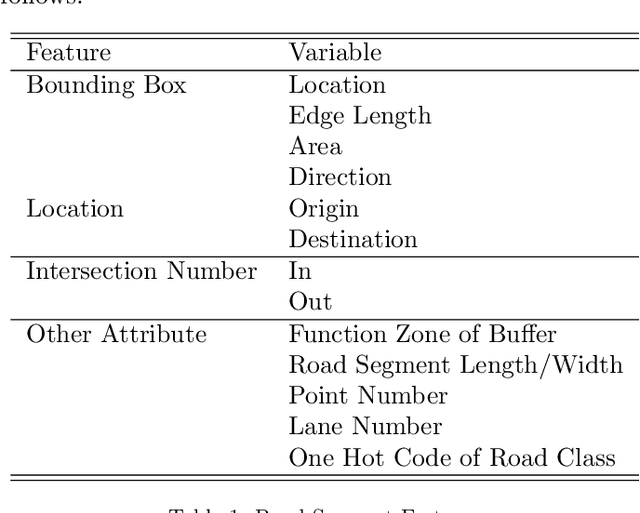
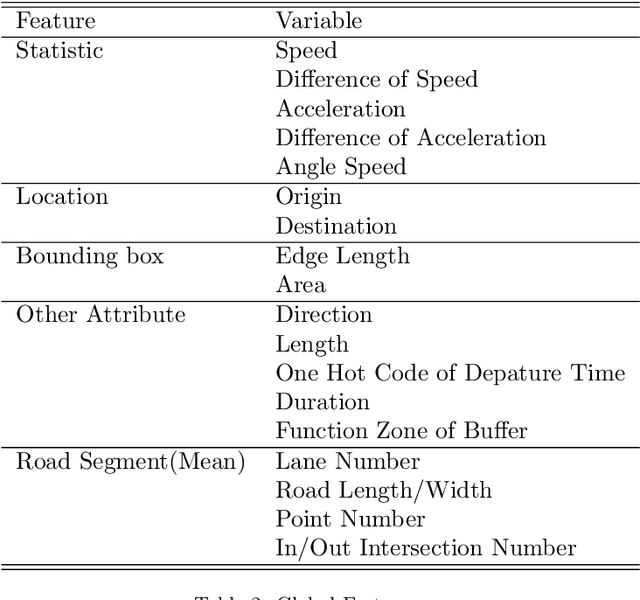
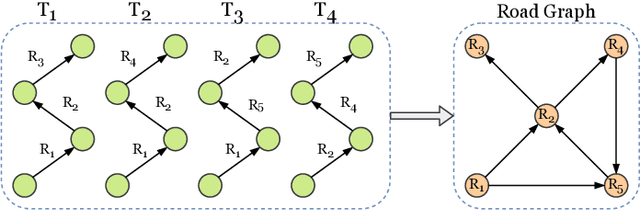
Driving trajectory representation learning is of great significance for various location-based services, such as driving pattern mining and route recommendation. However, previous representation generation approaches tend to rarely address three challenges: 1) how to represent the intricate semantic intentions of mobility inexpensively; 2) complex and weak spatial-temporal dependencies due to the sparsity and heterogeneity of the trajectory data; 3) route selection preferences and their correlation to driving behavior. In this paper, we propose a novel multimodal fusion model, DouFu, for trajectory representation joint learning, which applies multimodal learning and attention fusion module to capture the internal characteristics of trajectories. We first design movement, route, and global features generated from the trajectory data and urban functional zones and then analyze them respectively with the attention encoder or feed forward network. The attention fusion module incorporates route features with movement features to create a better spatial-temporal embedding. With the global semantic feature, DouFu produces a comprehensive embedding for each trajectory. We evaluate representations generated by our method and other baseline models on classification and clustering tasks. Empirical results show that DouFu outperforms other models in most of the learning algorithms like the linear regression and the support vector machine by more than 10%.
Scribble-based Boundary-aware Network for Weakly Supervised Salient Object Detection in Remote Sensing Images
Feb 07, 2022
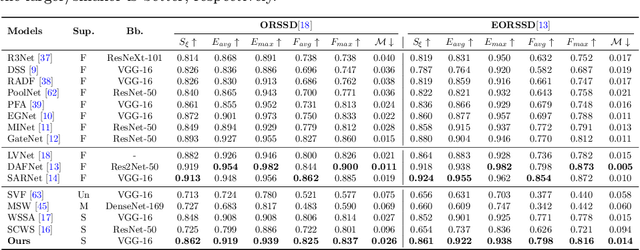
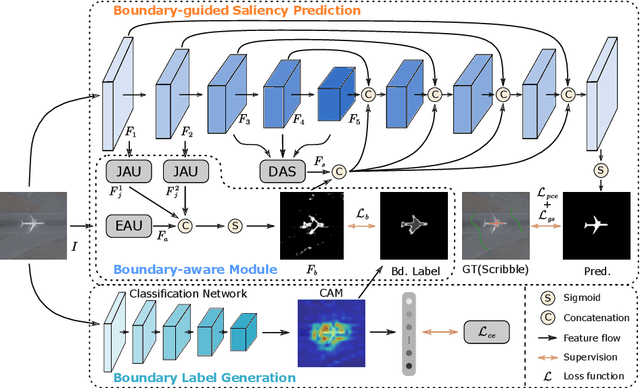
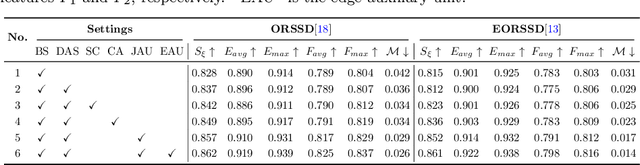
Existing CNNs-based salient object detection (SOD) heavily depends on the large-scale pixel-level annotations, which is labor-intensive, time-consuming, and expensive. By contrast, the sparse annotations become appealing to the salient object detection community. However, few efforts are devoted to learning salient object detection from sparse annotations, especially in the remote sensing field. In addition, the sparse annotation usually contains scanty information, which makes it challenging to train a well-performing model, resulting in its performance largely lagging behind the fully-supervised models. Although some SOD methods adopt some prior cues to improve the detection performance, they usually lack targeted discrimination of object boundaries and thus provide saliency maps with poor boundary localization. To this end, in this paper, we propose a novel weakly-supervised salient object detection framework to predict the saliency of remote sensing images from sparse scribble annotations. To implement it, we first construct the scribble-based remote sensing saliency dataset by relabelling an existing large-scale SOD dataset with scribbles, namely S-EOR dataset. After that, we present a novel scribble-based boundary-aware network (SBA-Net) for remote sensing salient object detection. Specifically, we design a boundary-aware module (BAM) to explore the object boundary semantics, which is explicitly supervised by the high-confidence object boundary (pseudo) labels generated by the boundary label generation (BLG) module, forcing the model to learn features that highlight the object structure and thus boosting the boundary localization of objects. Then, the boundary semantics are integrated with high-level features to guide the salient object detection under the supervision of scribble labels.
Detecting the Saliency of Remote Sensing Images Based on Sparse Representation of Contrast-weighted Atoms
Apr 06, 2020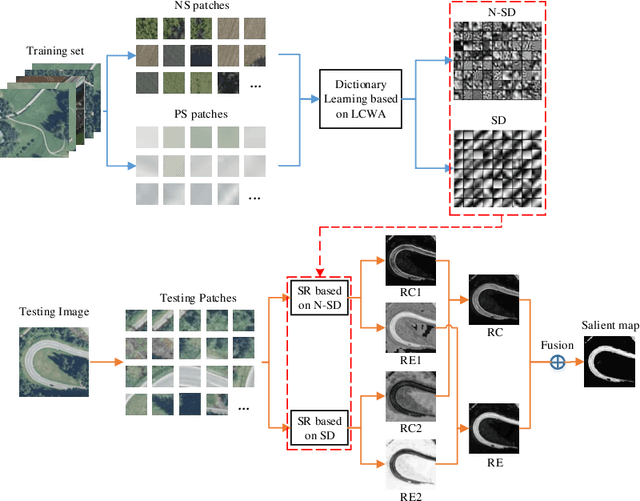

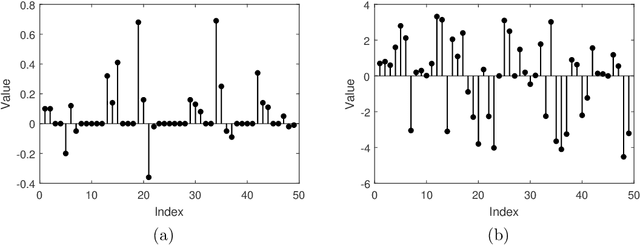

Object detection is an important task in remote sensing (RS) image analysis. To reduce the computational complexity of redundant information and improve the efficiency of image processing, visual saliency models are gradually being applied in this field. In this paper, a novel saliency detection method is proposed by exploring the sparse representation (SR) of, based on learning, contrast-weighted atoms (LCWA). Specifically, this paper uses the proposed LCWA atom learning formula on positive and negative samples to construct a saliency dictionary, and on nonsaliency atoms to construct a discriminant dictionary. An online discriminant dictionary learning algorithm is proposed to solve the atom learning formula. Then, we measure saliency by combining the coefficients of SR and reconstruction errors. Furthermore, under the proposed joint saliency measure, a variety of salient maps are generated by the discriminant dictionary. Finally, a fusion method based on global gradient optimisation is proposed to integrate multiple salient maps. Experimental results show that the proposed method significantly outperforms current state-of-the-art methods under six evaluation measures.