 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouFu: A Double Fusion Joint Learning Method For Driving Trajectory Representation
Paper and Code
May 05, 2022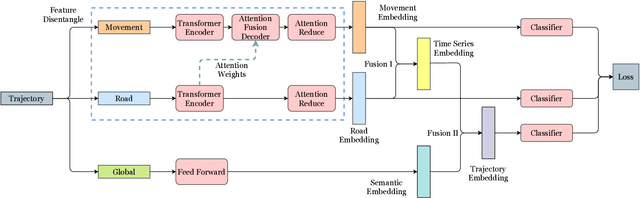
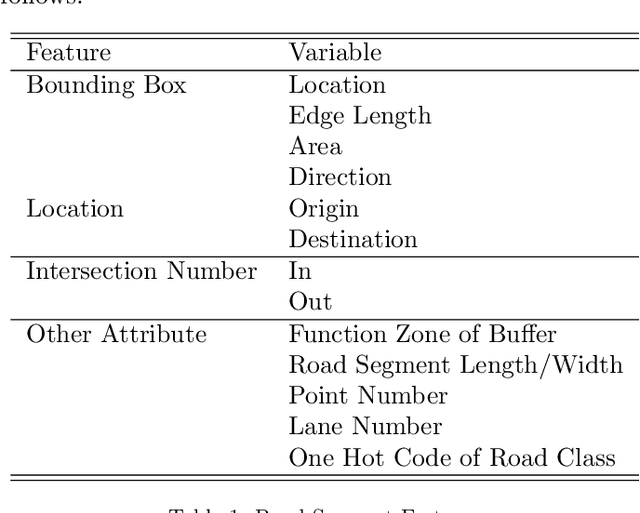
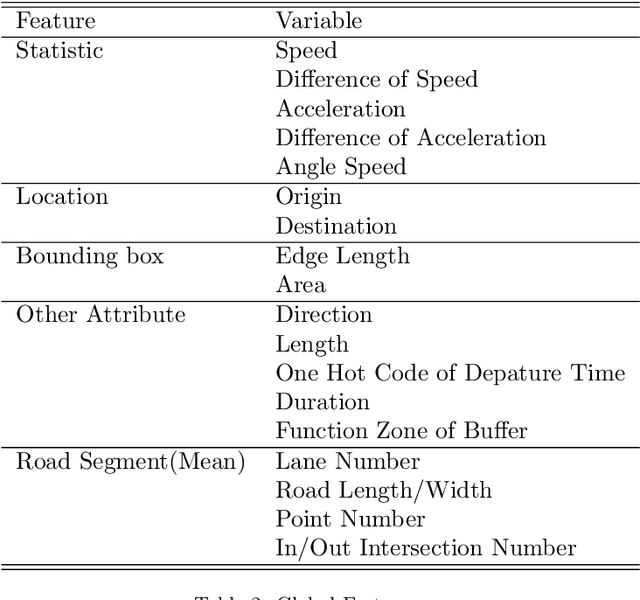
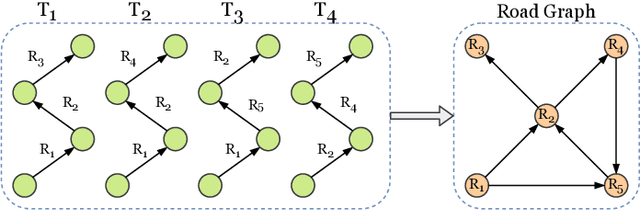
Driving trajectory representation learning is of great significance for various location-based services, such as driving pattern mining and route recommendation. However, previous representation generation approaches tend to rarely address three challenges: 1) how to represent the intricate semantic intentions of mobility inexpensively; 2) complex and weak spatial-temporal dependencies due to the sparsity and heterogeneity of the trajectory data; 3) route selection preferences and their correlation to driving behavior. In this paper, we propose a novel multimodal fusion model, DouFu, for trajectory representation joint learning, which applies multimodal learning and attention fusion module to capture the internal characteristics of trajectories. We first design movement, route, and global features generated from the trajectory data and urban functional zones and then analyze them respectively with the attention encoder or feed forward network. The attention fusion module incorporates route features with movement features to create a better spatial-temporal embedding. With the global semantic feature, DouFu produces a comprehensive embedding for each trajectory. We evaluate representations generated by our method and other baseline models on classification and clustering tasks. Empirical results show that DouFu outperforms other models in most of the learning algorithms like the linear regression and the support vector machine by more than 10%.