 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph-in-Graph Learning Framework for Drug-Target Interaction Prediction
Jul 15, 2025



Accurately predicting drug-target interactions (DTIs) is pivotal for advancing drug discovery and target validation techniques. While machine learning approaches including those that are based on Graph Neural Networks (GNN) have achieved notable success in DTI prediction, many of them have difficulties in effectively integrating the diverse features of drugs, targets and their interactions. To address this limitation, we introduce a novel framework to take advantage of the power of both transductive learning and inductive learning so that features at molecular level and drug-target interaction network level can be exploited. Within this framework is a GNN-based model called Graph-in-Graph (GiG) that represents graphs of drug and target molecular structures as meta-nodes in a drug-target interaction graph, enabling a detailed exploration of their intricate relationships. To evaluate the proposed model, we have compiled a special benchmark comprising drug SMILES, protein sequences, and their interaction data, which is interesting in its own right. Our experimental results demonstrate that the GiG model significantly outperforms existing approaches across all evaluation metrics, highlighting the benefits of integrating different learning paradigms and interaction data.
GWRBoost:A geographically weighted gradient boosting method for explainable quantification of spatially-varying relationships
Dec 15, 2022



The geographically weighted regression (GWR) is an essential tool for estimating the spatial variation of relationships between dependent and independent variables in geographical contexts. However, GWR suffers from the problem that classical linear regressions, which compose the GWR model, are more prone to be underfitting, especially for significant volume and complex nonlinear data, causing inferior comparative performance. Nevertheless, some advanced models, such as the decision tree and the support vector machine, can learn features from complex data more effectively while they cannot provide explainable quantification for the spatial variation of localized relationships. To address the above issues, we propose a geographically gradient boosting weighted regression model, GWRBoost, that applies the localized additive model and gradient boosting optimization method to alleviate underfitting problems and retains explainable quantification capability for spatially-varying relationships between geographically located variables. Furthermore, we formulate the computation method of the Akaike information score for the proposed model to conduct the comparative analysis with the classic GWR algorithm. Simulation experiments and the empirical case study are applied to prove the efficient performance and practical value of GWRBoost. The results show that our proposed model can reduce the RMSE by 18.3% in parameter estimation accuracy and AICc by 67.3% in the goodness of fit.
Learning Branching Heuristics from Graph Neural Networks
Nov 26, 2022



Backtracking has been widely used for solving problems in artificial intelligence (AI), including constraint satisfaction problems and combinatorial optimization problems. Good branching heuristics can efficiently improve the performance of backtracking by helping prune the search space and leading the search to the most promising direction. In this paper, we first propose a new graph neural network (GNN) model designed using the probabilistic method. From the GNN model, we introduce an approach to learn a branching heuristic for combinatorial optimization problems. In particular, our GNN model learns appropriate probability distributions on vertices in given graphs from which the branching heuristic is extracted and used in a backtracking search. Our experimental results for the (minimum) dominating-clique problem show that this learned branching heuristic performs better than the minimum-remaining-values heuristic in terms of the number of branches of the whole search tree. Our approach introduces a new way of applying GNNs towards enhancing the classical backtracking algorithm used in AI.
Code Representation Learning with Prüfer Sequences
Nov 14, 2021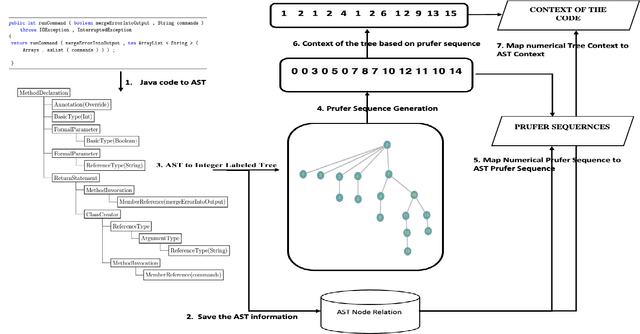



An effective and efficient encoding of the source code of a computer program is critical to the success of sequence-to-sequence deep neural network models for tasks in computer program comprehension, such as automated code summarization and documentation. A significant challenge is to find a sequential representation that captures the structural/syntactic information in a computer program and facilitates the training of the learning models. In this paper, we propose to use the Pr\"ufer sequence of the Abstract Syntax Tree (AST) of a computer program to design a sequential representation scheme that preserves the structural information in an AST. Our representation makes it possible to develop deep-learning models in which signals carried by lexical tokens in the training examples can be exploited automatically and selectively based on their syntactic role and importance. Unlike other recently-proposed approaches, our representation is concise and lossless in terms of the structural information of the AST. Empirical studies on real-world benchmark datasets, using a sequence-to-sequence learning model we designed for code summarization, show that our Pr\"ufer-sequence-based representation is indeed highly effective and efficient, outperforming significantly all the recently-proposed deep-learning models we used as the baseline models.
Content Filtering Enriched GNN Framework for News Recommendation
Oct 25, 2021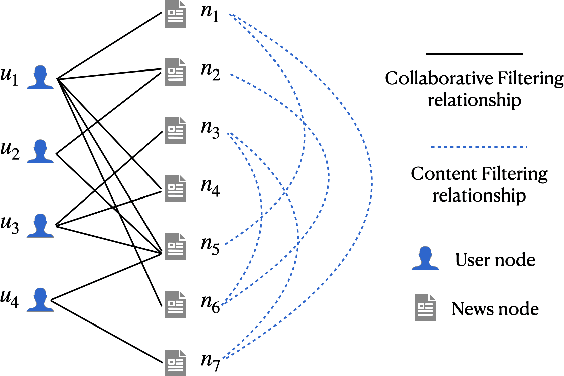
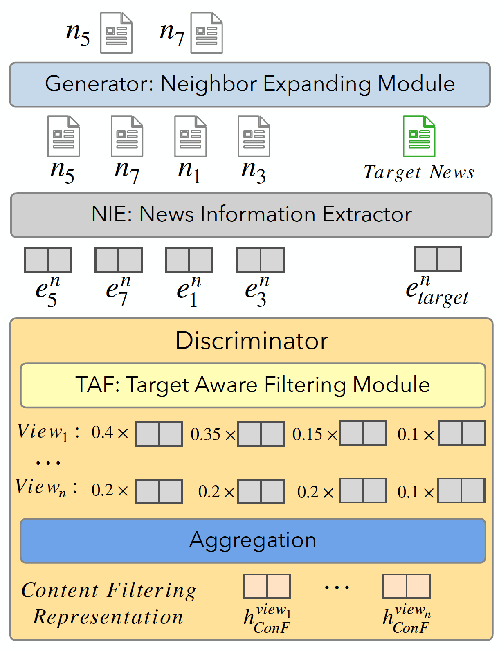
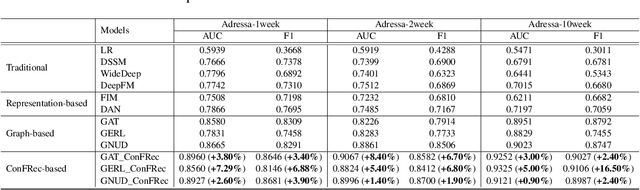
Learning accurate users and news representations is critical for news recommendation. Despite great progress, existing methods seem to have a strong bias towards content representation or just capture collaborative filtering relationship. However, these approaches may suffer from the data sparsity problem (user-news interactive behavior sparsity problem) or maybe affected more by news (or user) with high popularity. In this paper, to address such limitations, we propose content filtering enriched GNN framework for news recommendation, ConFRec in short. It is compatible with existing GNN-based approaches for news recommendation and can capture both collaborative and content filtering information simultaneously. Comprehensive experiments are conducted to demonstrate the effectiveness of ConFRec over the state-of-the-art baseline models for news recommendation on real-world datasets for news recommendation.
ScaleFreeCTR: MixCache-based Distributed Training System for CTR Models with Huge Embedding Table
May 11, 2021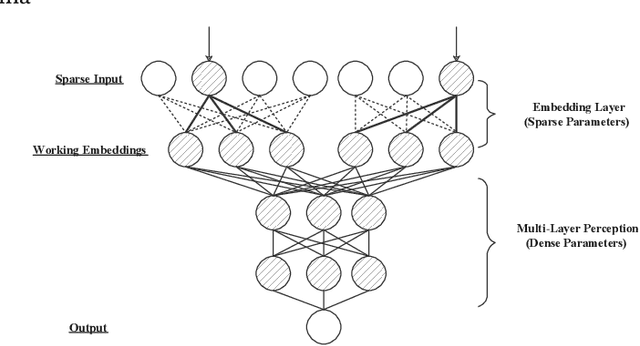

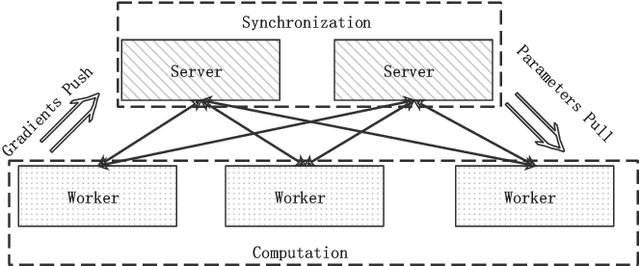
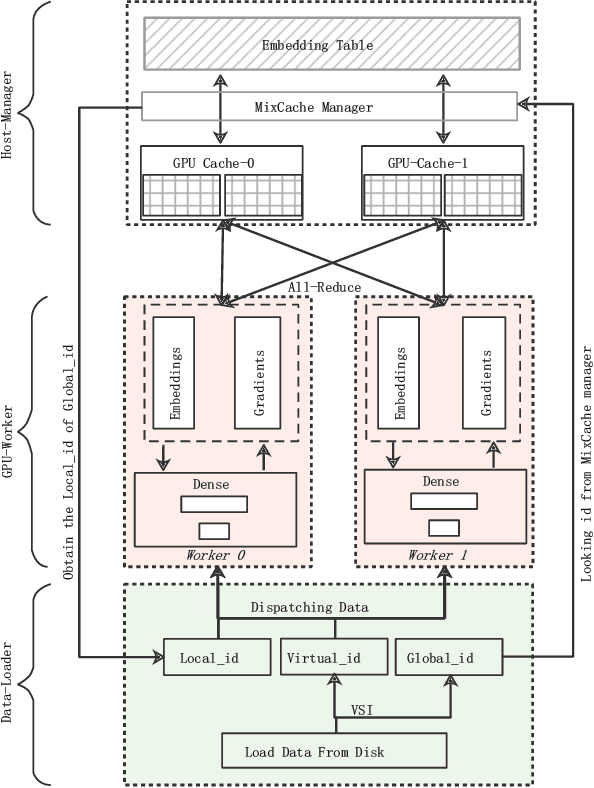
Because of the superior feature representation ability of deep learning, various deep Click-Through Rate (CTR) models are deployed in the commercial systems by industrial companies. To achieve better performance, it is necessary to train the deep CTR models on huge volume of training data efficiently, which makes speeding up the training process an essential problem. Different from the models with dense training data, the training data for CTR models is usually high-dimensional and sparse. To transform the high-dimensional sparse input into low-dimensional dense real-value vectors, almost all deep CTR models adopt the embedding layer, which easily reaches hundreds of GB or even TB. Since a single GPU cannot afford to accommodate all the embedding parameters, when performing distributed training, it is not reasonable to conduct the data-parallelism only. Therefore, existing distributed training platforms for recommendation adopt model-parallelism. Specifically, they use CPU (Host) memory of servers to maintain and update the embedding parameters and utilize GPU worker to conduct forward and backward computations. Unfortunately, these platforms suffer from two bottlenecks: (1) the latency of pull \& push operations between Host and GPU; (2) parameters update and synchronization in the CPU servers. To address such bottlenecks, in this paper, we propose the ScaleFreeCTR: a MixCache-based distributed training system for CTR models. Specifically, in SFCTR, we also store huge embedding table in CPU but utilize GPU instead of CPU to conduct embedding synchronization efficiently. To reduce the latency of data transfer between both GPU-Host and GPU-GPU, the MixCache mechanism and Virtual Sparse Id operation are proposed. Comprehensive experiments and ablation studies are conducted to demonstrate the effectiveness and efficiency of SFCTR.
Phase Transition of Tractability in Constraint Satisfaction and Bayesian Network Inference
Oct 19, 2012There has been great interest in identifying tractable subclasses of NP complete problems and designing efficient algorithms for these tractable classes. Constraint satisfaction and Bayesian network inference are two examples of such problems that are of great importance in AI and algorithms. In this paper we study, under the frameworks of random constraint satisfaction problems and random Bayesian networks, a typical tractable subclass characterized by the treewidth of the problems. We show that the property of having a bounded treewidth for CSPs and Bayesian network inference problem has a phase transition that occurs while the underlying structures of problems are still sparse. This implies that algorithms making use of treewidth based structural knowledge only work efficiently in a limited range of random instance.
A Fixed-Parameter Algorithm for Random Instances of Weighted d-CNF Satisfiability
Jun 28, 2008We study random instances of the weighted $d$-CNF satisfiability problem (WEIGHTED $d$-SAT), a generic W[1]-complete problem. A random instance of the problem consists of a fixed parameter $k$ and a random $d$-CNF formula $\weicnf{n}{p}{k, d}$ generated as follows: for each subset of $d$ variables and with probability $p$, a clause over the $d$ variables is selected uniformly at random from among the $2^d - 1$ clauses that contain at least one negated literals. We show that random instances of WEIGHTED $d$-SAT can be solved in $O(k^2n + n^{O(1)})$-time with high probability, indicating that typical instances of WEIGHTED $d$-SAT under this instance distribution are fixed-parameter tractable. The result also hold for random instances from the model $\weicnf{n}{p}{k,d}(d')$ where clauses containing less than $d' (1 < d' < d)$ negated literals are forbidden, and for random instances of the renormalized (miniaturized) version of WEIGHTED $d$-SAT in certain range of the random model's parameter $p(n)$. This, together with our previous results on the threshold behavior and the resolution complexity of unsatisfiable instances of $\weicnf{n}{p}{k, d}$, provides an almost complete characterization of the typical-case behavior of random instances of WEIGHTED $d$-SAT.