 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Representation Learning with Prüfer Sequences
Nov 14, 2021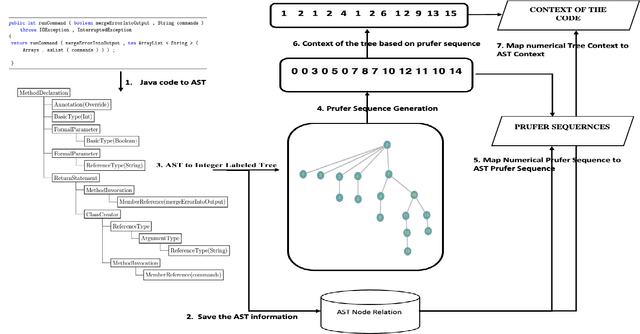



An effective and efficient encoding of the source code of a computer program is critical to the success of sequence-to-sequence deep neural network models for tasks in computer program comprehension, such as automated code summarization and documentation. A significant challenge is to find a sequential representation that captures the structural/syntactic information in a computer program and facilitates the training of the learning models. In this paper, we propose to use the Pr\"ufer sequence of the Abstract Syntax Tree (AST) of a computer program to design a sequential representation scheme that preserves the structural information in an AST. Our representation makes it possible to develop deep-learning models in which signals carried by lexical tokens in the training examples can be exploited automatically and selectively based on their syntactic role and importance. Unlike other recently-proposed approaches, our representation is concise and lossless in terms of the structural information of the AST. Empirical studies on real-world benchmark datasets, using a sequence-to-sequence learning model we designed for code summarization, show that our Pr\"ufer-sequence-based representation is indeed highly effective and efficient, outperforming significantly all the recently-proposed deep-learning models we used as the baseline models.